【步骤零】实验环境准备
写在前面
简介:本文章基于厦门大学提供的大数据课程实验案例:网站用户行为分析,通过使用 CentOS 操作编写而来。具体介绍请打开链接进行阅读。
这里介绍几点值得特别注意的事项:
1、对于案例所涉及的系统及软件此文档使用的是以下版本,其他软件版本随意:
- Linux系统(CentOS7)
- MySQL(5.7)
- Hadoop(3.1.3)
- HBase(2.2.2,HBase版本需要和Hadoop版本兼容)
- Hive(3.1.2,Hive需要和Hadoop版本兼容)
- Sqoop(1.4.7)
- R(3.6.0)
- IDEA( 2023.3.6 社区版)
PS:Hadoop 与 HBase、Hive 版本一定要兼容!!!版本一定要兼容!!!这很重要!!!😃😃😃其他软件随意。
2、所有下载的安装包均在 / 目录下。所有安装的软件均在 /usr/local/ 目录下以 软件名-版本号 方式命名。在进行每个软件的安装操作之前请先整体阅读整个软件安装流程的文章有个整体思路,了解到安装此软件需要做哪些设置再进行操作,这样可以避免很多不必要的麻烦。
3、此案例分为五个步骤,请按照步骤顺序进行阅读!!🙂🙂
1. 安装 Linux 系统
1.1 Linux 的选择
在 Linux 系统各个发行版中,CentOS 系统和 Ubuntu 系统在服务端和桌面端使用占比最高,选择 Ubuntu 还是 CentOS 主要取决于你的具体需求和使用场景。
适用场景:
- CentOS 更适合用于企业级服务器环境,特别是那些需要长时间运行和大量数据处理的场景。它属于Red Hat Enterprise Linux(RHEL)的社区版本,核心思想是企业级稳定性和可靠性。
- Ubuntu 则更注重用户友好和易用性,因此更适合个人电脑和桌面应用。它也常用于学习和探索 Linux 的初学者。
稳定性:
- CentOS 以其稳定性著称。它经过长时间的测试,只有经过验证的稳定版本才会被发布,因此更加安全稳定。
- Ubuntu 的 LTS(长期支持)版本也非常稳定,提供长达五年的维护和支持。然而,其升级包有时可能会造成系统的不稳定和不安全。
使用难度和界面:
- Ubuntu 对新手更为友好,它拥有大量的帮助文档和教程,用户界面也更加友好,适合不熟悉 Linux 的用户。
- CentOS 则相对较难上手,特别是对新用户来说。它的界面设计更加简洁,侧重于稳定性和安全性。
软件包和兼容性:
- CentOS 拥有庞大的软件包库,提供了大量的开源软件。
- Ubuntu 则与 Canonical 公司以及其他软件供应商有良好的兼容性,对于一些商业软件的支持也更好。
社区支持:
- Ubuntu 由于其商业支持者和更大的社区,可能在某些情况下能提供更多的帮助。
- CentOS 虽然也有社区支持,但可能不如 Ubuntu 的社区那么活跃和广泛。
综上所述,如果你需要一个稳定且适用于企业级服务器环境的系统,CentOS 可能是更好的选择。而如果你更注重易用性和友好的用户界面,或者你是一个 Linux 初学者,那么 Ubuntu 可能更适合你。这只是一个大致的指导,具体选择还需要根据你的具体需求和使用场景进行权衡。
PS:本教程选择的是 CentOS7 版本!!!😀下面我们就开始安装 CentOS7 吧!
1.2 CentOS7 下载地址
.png)
点进去之后依次点击 isos/ –> x86_64/ ,找到下面文件进行下载
.png)
阿里镜像站:与上面版本有些小差异,不过问题不大。都是CentOS7😉)
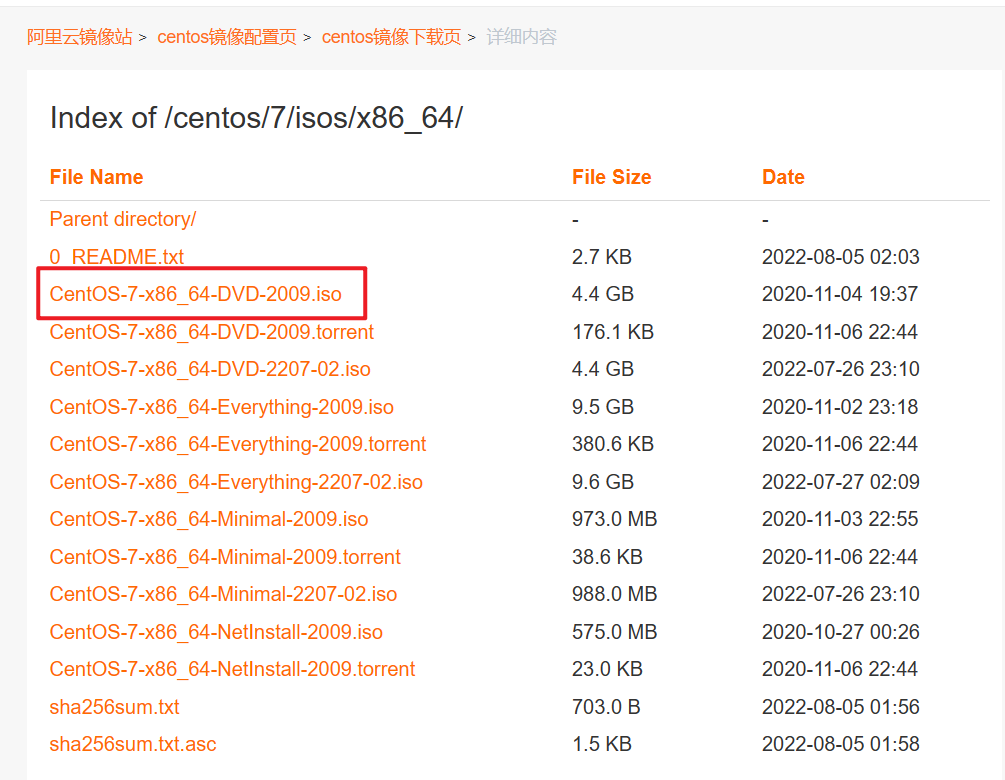
打开网站后下载对应的 ios 文件就可以了。
1.3 CentOS7 系统安装
Linux 系统的安装主要有两种方式:虚拟机安装和双系统安装。
虚拟机安装和使用 Linux 的硬件配置比较高,建议要求电脑至少有8G运行内存且剩余的存储容量足够大。电脑较旧或运行内存小于等于 4G 的电脑强烈建议选择双系统安装。否则,在配置较低的电脑上运行 Linux 虚拟机,系统运行速度会非常慢电脑会卡死😓。
什么是运行内存和存储容量?
通俗的说,运行内存决定了同时运行的程序多少,存储空间决定了能装文件的多少。口语中习惯上用运行内存+存储空间简单描述设备主要指标。
如何查看电脑运行内存和存储容量?
运行内存:
双击
此电脑打开如下界面,然后在空白处右键,点击属性。
然后会出现这个界面,这里显示的
RAM就是电脑的运行内存了。
存储容量:
简单的来说就是你电脑所有盘符的大小,双击
此电脑就可以看到自己电脑所有盘符的信息。
由于我的电脑是16G + 512G ,所以我这里使用虚拟机安装。
虚拟机 VMware 安装
点开后鼠标向下滑,点击 VMware Workstation 17 Pro 栏下的 DOWNLOAD NOW 之后开始下载 VMware。
安装时使用 “傻瓜式” 安装,无脑下一步即可。PS:注意按自己需求修改安装路径!😏
安装完后需要产品许可证激活软件,大家可以在网上自行搜索。
安装成功后,Win + i 打开 Windows 设置找到 网络和 Internet,点击 高级网络设置 里的 更改设配器选项,出现了下面两个网络适配器则说明安装成功了。如果没有出现就说明网络适配器没有安装成功,那可能就要重装 VMware 咯😣。PS:重装之前记得将以前安装的 VMware 删除干净 !!!!!😂
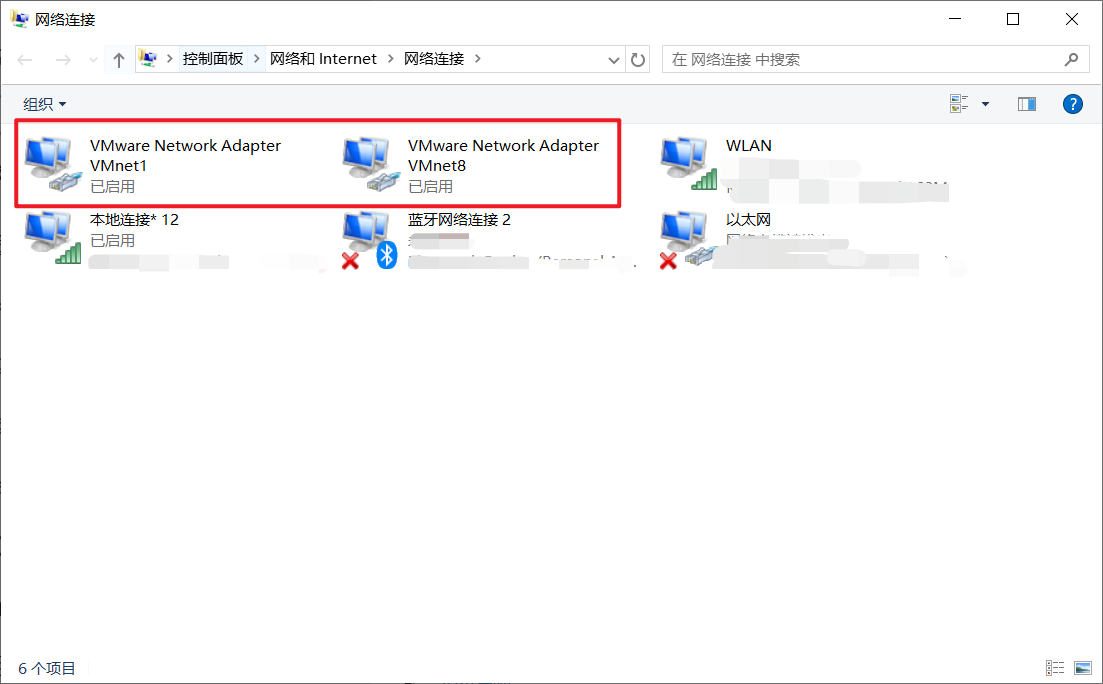
在 Windows 使用 VMware 安装 CentOS7
1、打开 VMware 点击 创建新的虚拟机 。
.png)
2、选择 自定义(高级),点击下一步。
典型安装:VMware 会将主流的配置应用在虚拟机的操作系统上,对于新手来很友好。
自定义安装:自定义安装可以针对性的把一些资源加强,把不需要的资源移除。避免资源的浪费。
这里我选择自定义安装。
.png)
3、连续点击下一步来到这个界面,找到择 iso 文件,然后点击下一步。
.png)
4、设置 Linux 名称、用户名、密码,设置完成点击下一步。
密码建议尽量简单一些,我这里设置的是 123456 。
.png)
5、设置虚拟机名称和位置,然后点击下一步。
虚拟机安装完成后所在的目录,建议放在 C 盘以外的盘符。
我这里设置成 C 盘仅仅是教学需要,因为我电脑其他盘符已经 红 了。😭😭😭
.png)
6、选择处理器数量以及每个处理器的内核数量(两者乘积不能超过本机的CPU内核数),我这里都设置成 2 ,大家随意,然后点击下一步。
.png)
7、选择内存大小(根据本机内存大小适当选择,建议不要选择超过本机一半的内存,例如我的是 16G,所以我选择 4G 内存),然后点击下一步。
.png)
8、连续点击下一步来到这个界面,选择磁盘大小(根据本机大小自己定,建议本机磁盘充裕的情况下越大越好,我这里选择 40G ),将虚拟机磁盘拆分成多个文件,然后点击下一步。
.png)
9、连续点击下一步来到这个界面,核对信息无误后点击 完成 即可。
.png)
至此 CentOS7 的安装就结束啦!现在只需要等待虚拟机开机即可。PS:虚拟机第一次开机较久,大家需要耐心等待哦。😊
加载完成后会出现以下界面:
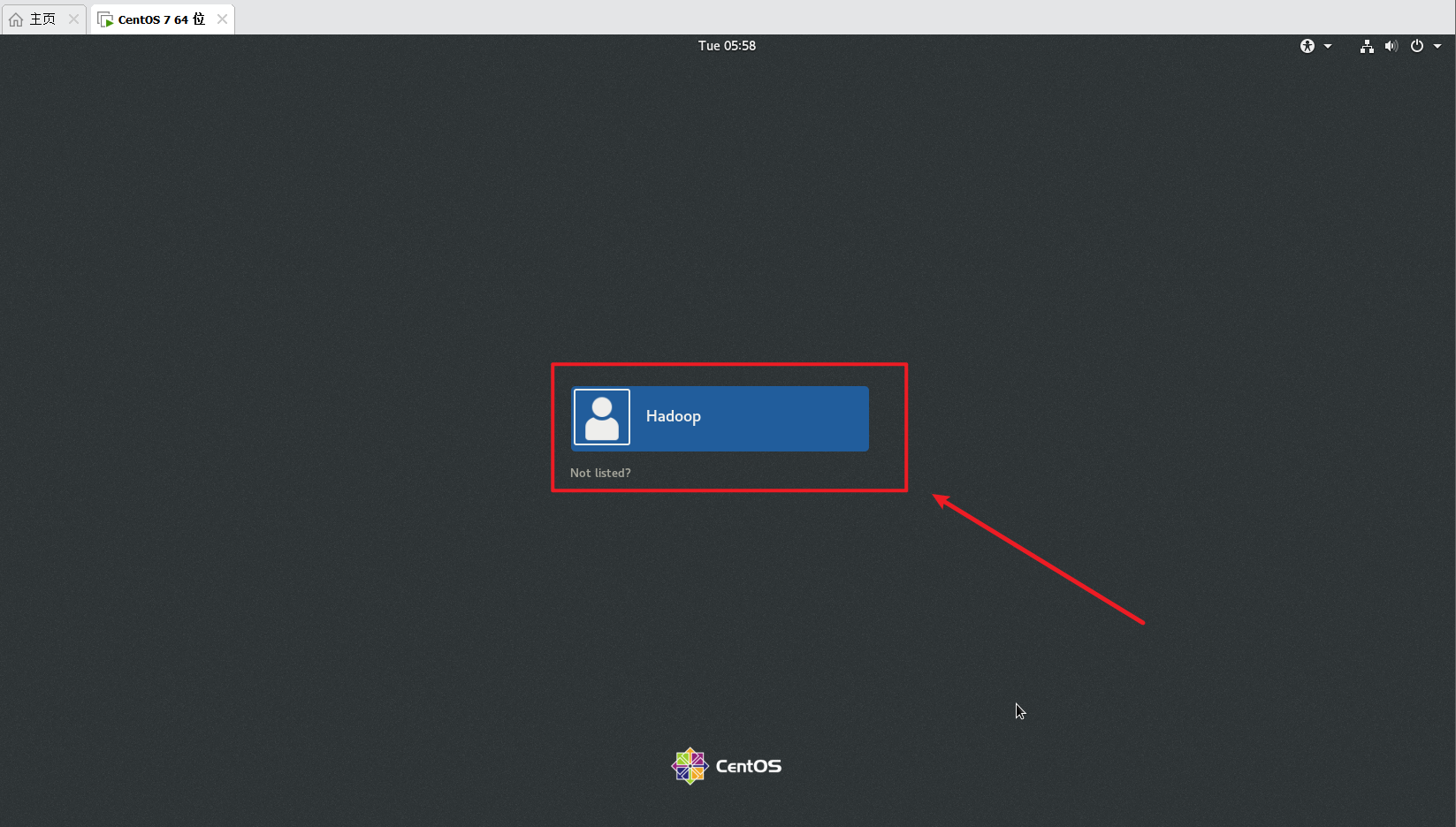
只需要点击一下用户然后输入密码,再点击 Sign In 即可进入虚拟机主界面(第一次开机系统会弹出提示,直接点击右上角 “X” 掉即可),这就成功进入虚拟机了。

至此 Linux 系统已经成功安装好啦!!!!!!!!!!
如何查看自己虚拟机的 ip 地址?
桌面空白处右键点击 Open Terminal 打开 Terminal ,输入 ifconfig 后在 ens33 下看到的这个就是虚拟机的 ip 地址。
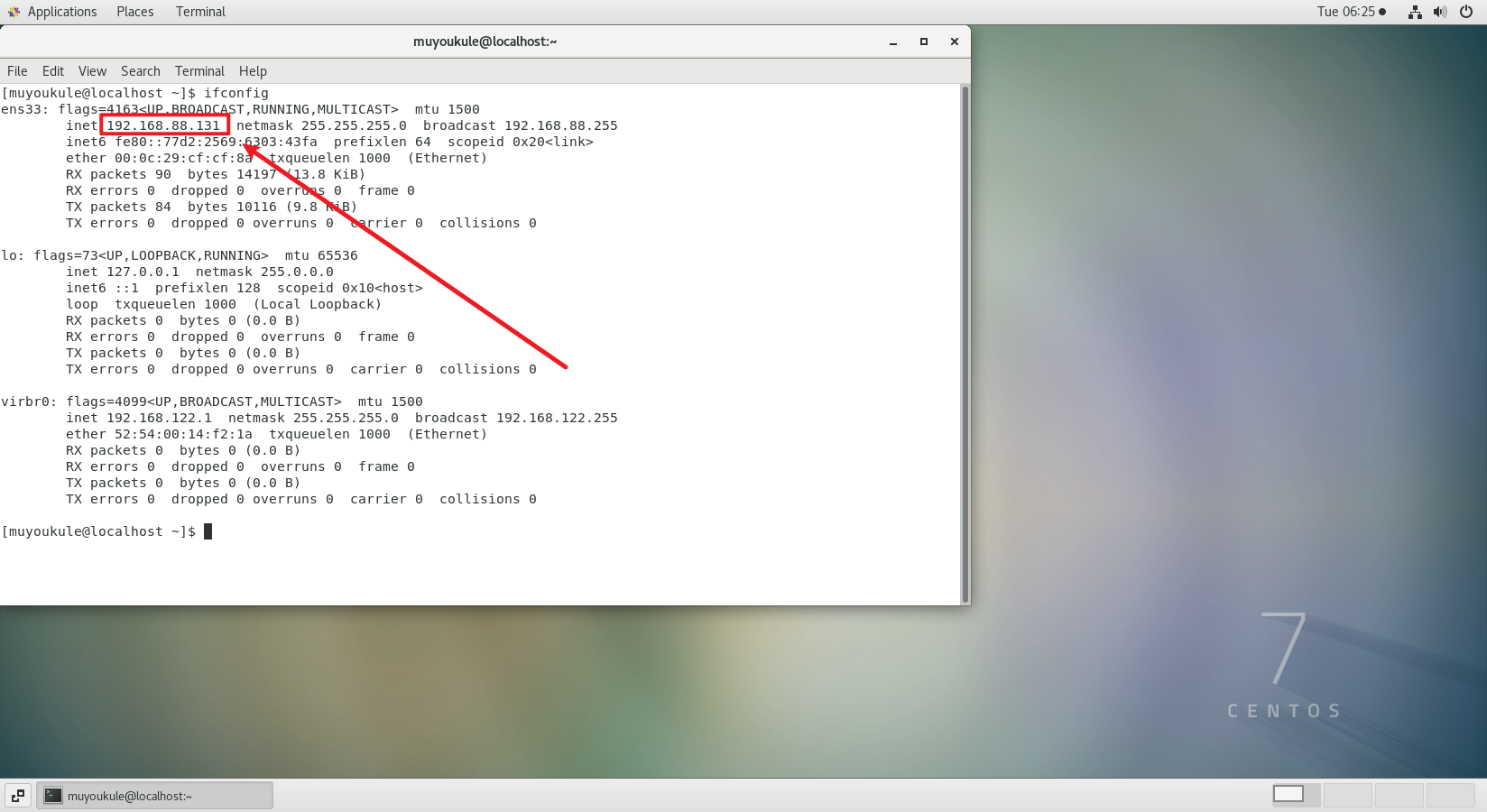
远程连接工具
我们使用 VMware 可以得到 Linux 虚拟机,但是在 VMware 中操作 Linux 的命令行页面不太方便,主要是:和Linux系统的各类交互,跨越 VMware 不方便界面不好看。😐
这里介绍的是 FinalShell ,我为什么选择 FinalShell 呢?主要是 FinalShell 是国产SSH工具(纯中文)我用习惯了而已😁,当然市面上也有很多其他的远程连接工具,你可以自行选择。🤔
FinalShell 下载安装
下载官网,点进去选择相应的版本即可。
安装:安装?安装时使用 “傻瓜式” 安装,无脑下一步即可。PS:注意按自己需求修改安装路径!😏
FinalShell 使用
FinalShell 新建连接
.png)
.png)
.png)
.png)
FinalShell 文件上传
在安装各种软件的时候为了方便,我们通常都是将软件在本机下载好然后再上传到 Linux 系统进行安装,那么怎样将本机下载的软件上传到 Linux 呢?
两种方式:
- 命令上传(需要
sudo yum -y install lrzsz安装) - 直接拖动文件(需要切换 root 用户连接 Linux)
第一种:命令上传
PS:在上传文件之前请前用 cd 命令切换到文件要上传的目录。😊
执行 sudo rz 命令后会弹出以下界面(第一次使用需要 sudo yum -y install lrzsz 安装一下),选择下载的文件后点击确定(或者直接双击文件)
.png)
等待上传进度 100% 即可
.png)
上传完成后可以通过 ll 命令查看,在目录下出现了对应安装包,则上传成功
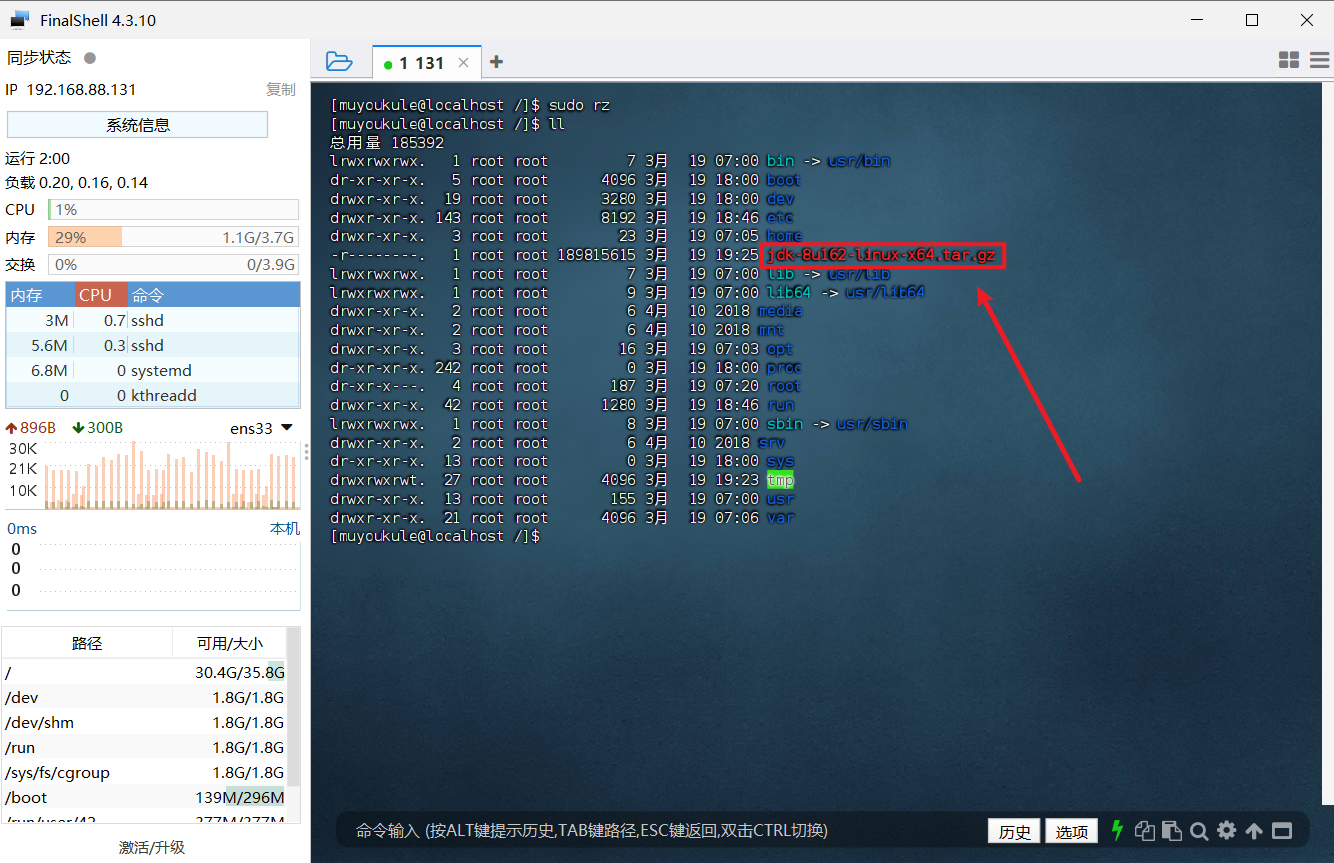
第二种:直接拖动文件
PS:使用这种方式一定要用 root 用户连接Linux,普通用户会上传失败😊
怎么切换用户?
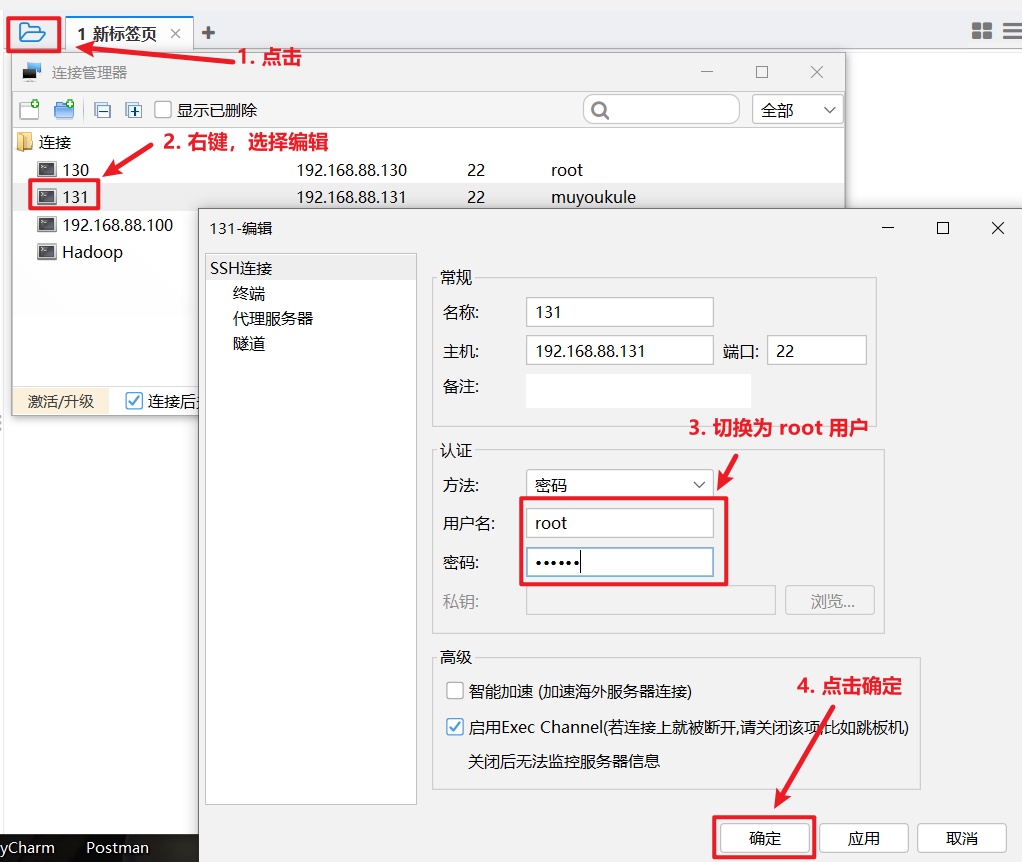
切换用户后点击 FinalShell 右下角箭头
.png)
然后点击选择文件要上传到的目录,在 Windows 中直接将文件拖到此目录即可
.png)
之后就可以通过图形化界面在目录中看到刚刚上传的文件了
.png)
PS:上传完之后记得切换回普通用户,避免误操带来系统损坏。😊
在后面涉及到文件上传的内容均采用以上两种方式(按需自选其一即可),所以后面不再过多赘述。
2. Hadoop
Hadoop 是一个由 Apache 基金会开发的分布式系统框架,它利用集群的强大计算能力进行大数据的存储和处理,通过 HDFS 实现分布式存储,并通过 MapReduce 实现分布式计算,为企业提供了高效、可靠、可扩展的大数据处理能力。
2.1 Hadoop 安装准备
配置操作权限
安装之前我们要先了解到:我们刚才在安装 CentOS 的时候设置的用户名只是普通用户,而普通用户在许多地方的权限是受限的。那要怎么解决普通用户在 Linux 系统下权限受限的问题呢?
两个方案(推荐使用第二种,不建议长期使用 root 用户,避免带来系统损坏):
- 使用 root 用户进行操作( root 用户拥有最大的系统操作权限)。
- 为普通用户配置 sudo 认证(为普通用户增加管理员权限)。(推荐)
第一种:使用 root 用户进行操作
直接使用命令然后输入密码即可切换到 root 用户。(输入密码时可能不会显示,输入密码后直接 Enter 确认就行)。
1 | # 切换到 root 用户 |
切换用户后,可以通过 exit 命令退回上一个用户,也可以使用快捷键:ctrl + d 。
使用普通用户,切换到其它用户需要输入密码,如切换到 root 用户。
使用 root 用户切换到其它用户,无需密码,可以直接切换。
第二种:为普通用户配置 sudo 认证
为普通用户配置 sudo 认证后,在执行其它命令之前,带上 sudo ,即可为这一条命令临时赋予 root 授权。
1、切换到 root 用户,使用命令然后输入密码
1 | # 切换到 root 用户 |
2、执行以下命令,会自动通过 vi 编辑器打开:/etc/sudoers
1 | visudo #或者执行 vi /etc/sudoers |
3、先按一下键盘上的 ESC 键,再输入:set nu 显示行号,找到 root ALL=(ALL) ALL 这行,然后输入 :101 (跳到第101行 ),然后在这行增加一行内容:muyoukule ALL=(ALL) NOPASSWD:ALL (其中 muyoukule 是需要配置 sudo 认证的普通用户,NOPASSWD:ALL 表示使用 sudo 命令时无需输入密码,中间的间隔为 tab ),如下图所示:

4、添加上一行内容后,先按一下键盘上的 ESC 键,然后输入 :wq 再按回车键保存退出就可以了。
5、最后使用 ctrl + d 注销当前 root 用户,回到刚才自己创建的用户,至此为普通用户配置 sudo 认证成功。
检查网络
使用 muyoukule 用户登录后,还需要安装几个软件才能安装 Hadoop。
CentOS 使用 yum 来安装软件,需要联网环境,首先应检查一下是否连上了网络。
提供两种方式:
如下图所示,桌面右上角的网络图标若显示 绿 点,则表明还联网。

使用
ping www.baidu.com,ping 得通说明可以联网。
安装 SSH、配置 SSH 无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),一般情况下,CentOS 默认已安装了 SSH client、SSH server,打开终端执行如下命令进行检验:
1 | # 检验是否安装了 SSH client、SSH server |
如果返回的结果如下图所示,包含了 SSH client 跟 SSH server,则不需要再安装。

若需要安装,则可以通过 yum 进行安装:
1 | sudo yum -y install openssh-clients |
接着执行如下命令测试一下 SSH 是否可用:
1 | ssh localhost |
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 123456 (输入你自己安装虚拟机的时候输入的密码),这样就登陆到本机了。
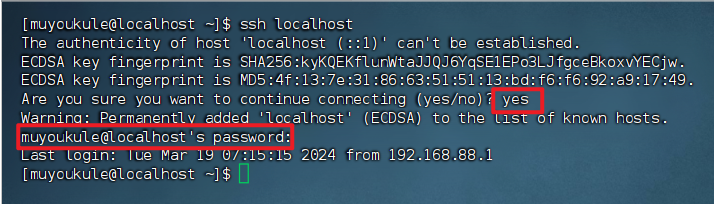
但这样登陆是需要每次输入密码的,我们需要配置成 SSH 无密码登陆比较方便。
首先输入 exit 退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
1 | # 退出刚才的 ssh localhost |
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示:

准备 Java 环境
准备 Java 环境之前我们要知道两件事:
- 软件安装的那些事:Linux软件安装在哪个目录? 很重要!!!!一定要仔细阅读!!!避免后续自己找不到安装的软件!!!😅
- JRE 和 JDK 的主要区别:JRE ( Java 运行环境)仅用于运行已 编译 的 Java 程序,而 JDK ( Java 开发工具包)则包含了 编译、调试、运行 Java 程序所需的所有工具,用于 Java 程序的开发。简单来说,JRE 是运行 Java 的,而 JDK 是开发 Java 的。
在Linux系统中,Java 环境的选择和配置对于运行 Hadoop 等 Java 应用至关重要,因为 Hadoop 是基于 Java 开发的。我们可以选择以下两种方式安装 Java 环境(推荐第二种方式):
- 安装 OpenJDK 。
- 安装 Oracle 的 JDK 。(推荐)
Linux 系统通过 yum 安装 OpenJDK 更为简便且开源免费,而安装 Oracle JDK 则需手动下载并可能涉及商业授权,但享有 Oracle 的专业技术支持,两者在版本更新和稳定性上也有所不同,选择取决于具体需求和偏好。
第一种:安装 OpenJDK
OpenJDK 是开源的,并且被广大社区所支持,因此在许多 Linux 发行版中,包括CentOS ,OpenJDK 被作为默认的 Java 环境安装。以 CentOS7 为例,它默认安装了 OpenJDK 1.8 的 Java 运行环境(JRE)。可以使用 java -version 查看到:

但是不能在系统环境变量中查看到 JAVA_HOME ,由于 Hadoop 需要这个环境变量,所以后面需要进行 Java 的相关环境变量配置。
然而,对于 Hadoop 等 Java 应用的开发和运行,通常需要完整的 Java 开发工具包(JDK),而不仅仅是 JRE 。因此,为了开发方便和确保 Hadoop 等应用的正常运行,用户需要安装 JDK 。
在 CentOS 中,可以通过 yum 包管理器来安装 JDK。具体过程请参考:使用 yum 安装 jdk 并配置环境变量
第二种:安装 Oracle 的 JDK
打开后下拉找到相应的版本下载即可,点击下载后在弹出的页面中输入 Oracle 的账户密码即可下载(如无账户,请自行注册,注册是免费的)。PS:一定要下载以 .tar.gz 结尾的文件,不要下载错了哦!!😊
下载好之后就可以开始安装了:
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 JDK 安装文件到 /usr/local 目录,解压完成后可以进入到 /usr/local 目录查看是否多了以下文件夹:
1 | # 解压缩 JDK 安装文件到 /usr/local 目录 |
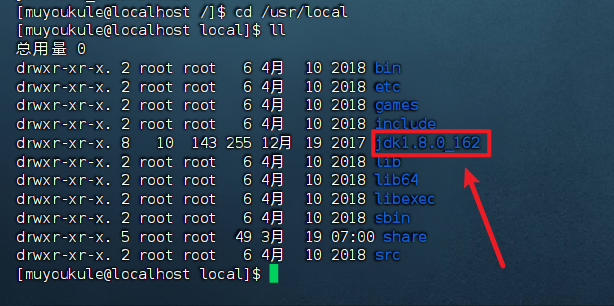
3、配置环境变量,使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
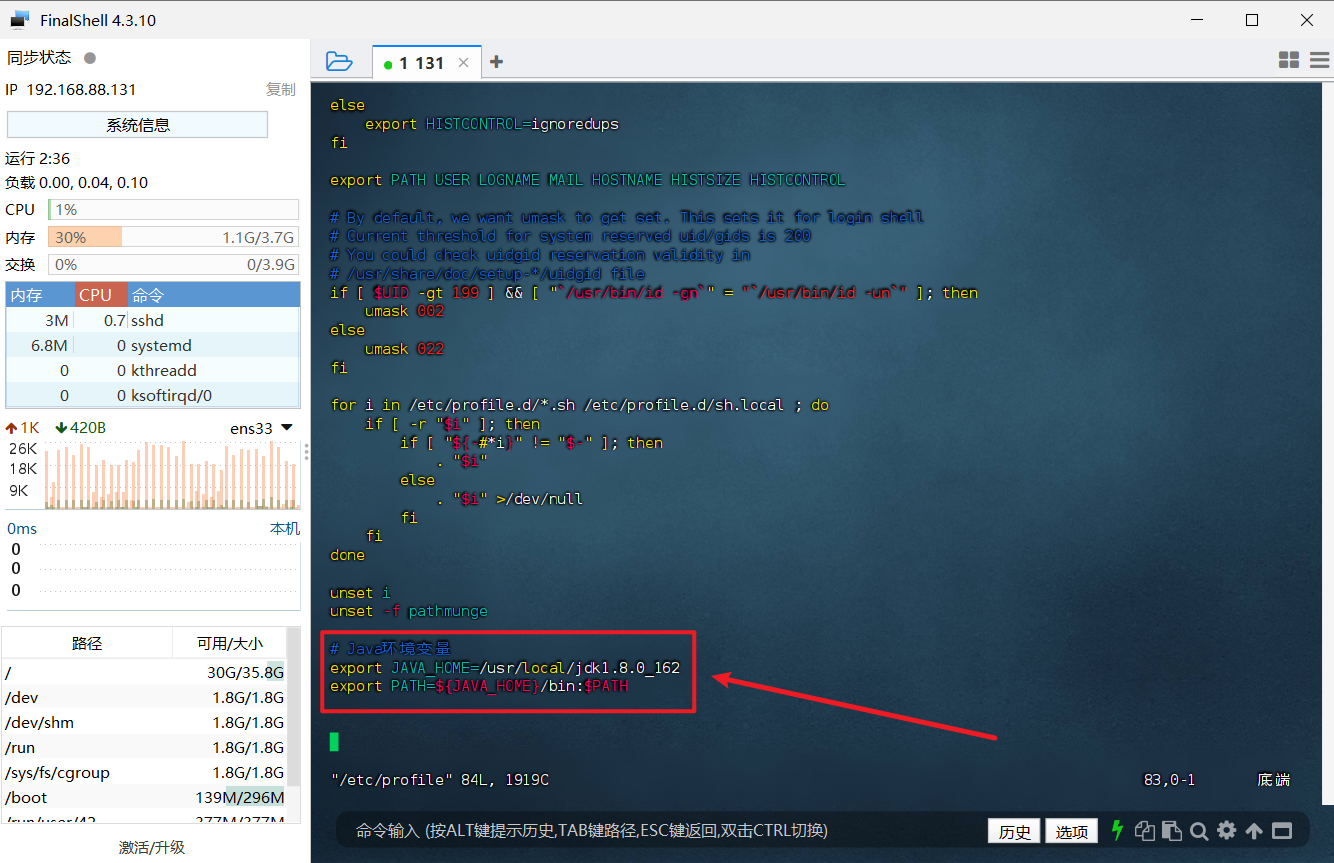
4、重启环境变量配置
1 | source /etc/profile |
5、检查安装结果,如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样:
1 | $JAVA_HOME/bin/java -version |
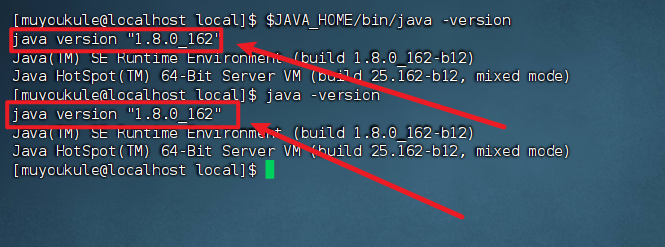
这样,Hadoop 所需的 Java 运行环境就安装好了。
2.2 Hadoop下载安装
.png)
.png)
打不开官网?试试清华大学开源软件镜像站下载,不过好像只有新版。🤔
下载好之后就可以开始安装了:
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 Hadoop 安装文件到 /usr/local 目录,解压完成后可以进入到 /usr/local 目录查看是否成功。
1 | # 解压缩安装文件到 /usr/local 目录 |
3、配置环境变量,使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
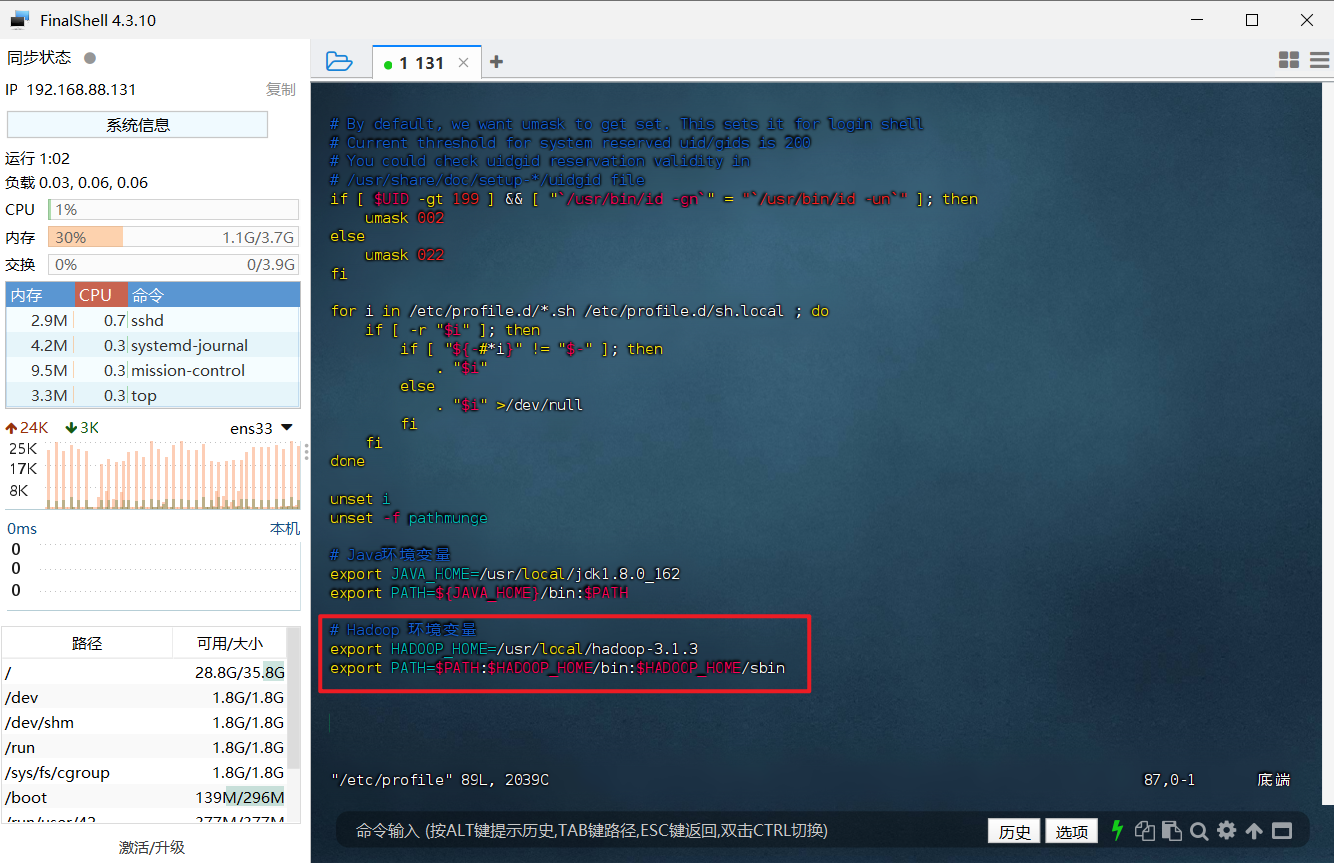
4、重启环境变量配置
1 | source /etc/profile |
5、检查安装结果,出现下面信息代表安装成功
1 | # 查看 Hadoop 版本信息 |

这样,Hadoop 就安装好了。
2.3 Hadoop 单机配置
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子,包括 wordcount、terasort、join、grep 等。
- WordCount 是一个基础示例程序,用于计算文本中每个单词的出现次数,通过MapReduce模型实现数据的分布式处理。
- Terasort 是 Hadoop 中的一个排序算法,能够处理大规模数据集的排序问题,通过分布式计算和 trie 树的性质提高排序效率。
- Join 操作在 Hadoop 中虽然不直接支持,但可以通过编程实现类似的功能,包括 Reduce side join 和 Map side join,用于整合不同数据源中的数据。
- Grep 则是一种文本搜索工具,在 Hadoop 中可以用于搜索存储在 HDFS 中的大规模文本文件,通过编写自定义的 Mapper 程序实现特定正则表达式的匹配。
1 | # 改变当前工作目录到 /usr/local/hadoop-3.1.3 |
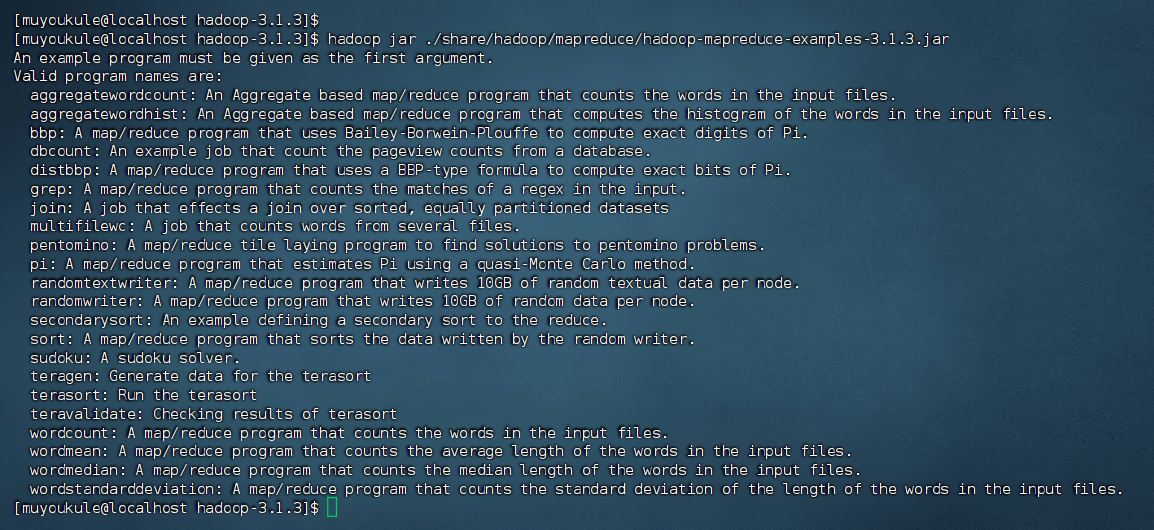
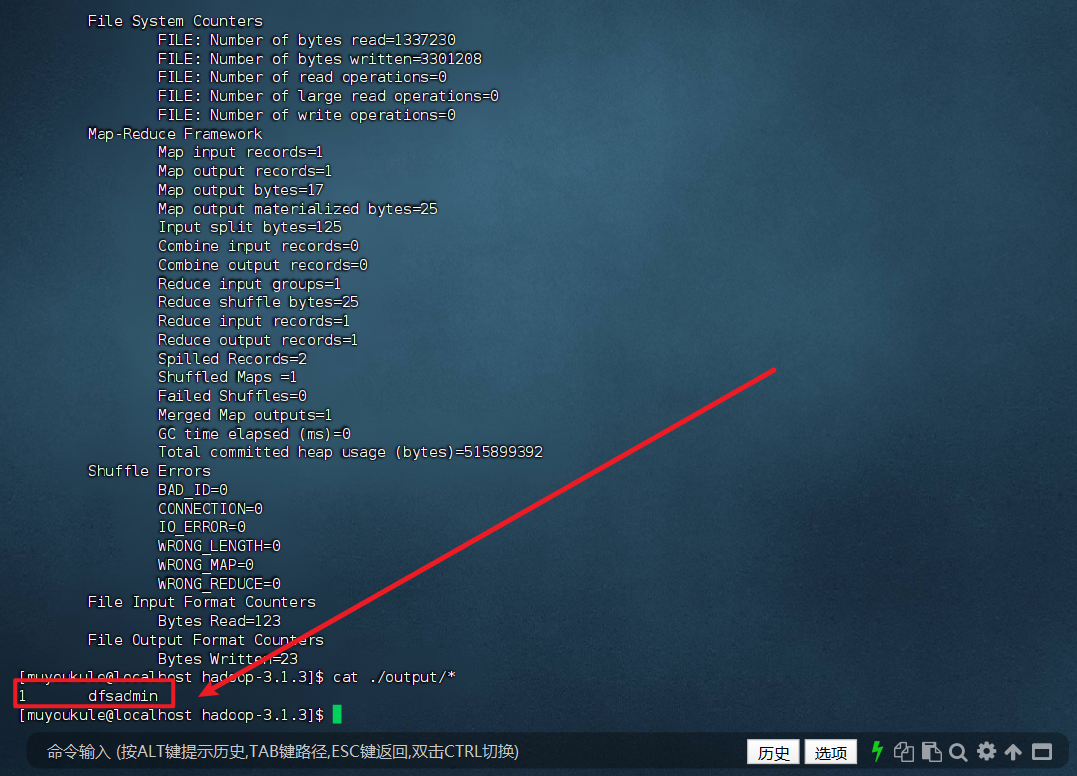
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。需要注意:如果 output 目录已经存在,Hadoop 会报错,因为输出目录必须是空的。
1 | # 改变当前工作目录到 /usr/local/hadoop-3.1.3 |
执行完后可以看到如下内容:
2.4 Hadoop 伪分布式配置
Hadoop 的伪分布式配置允许 Hadoop 在单节点上以分布式的方式运行,尽管所有的 Hadoop 进程都运行在同一台机器上。在这种配置中,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时读取的是 HDFS(Hadoop Distributed File System)中的文件。
cd 进入 Hadoop 安装包内,通过 ll 命令查看文件夹内部结构:
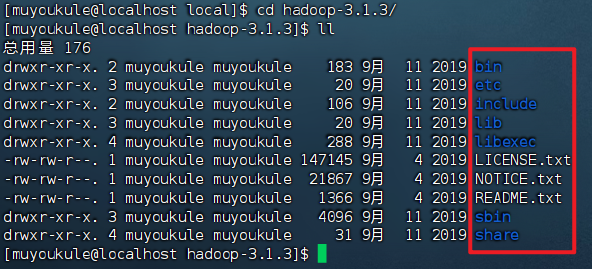
各个文件夹含义如下:
- bin,存放Hadoop的各类程序(命令)
- etc,存放Hadoop的配置文件
- include,C语言的一些头文件
- lib,存放Linux系统的动态链接库(.so文件)
- libexec,存放配置Hadoop系统的脚本文件(.sh和.cmd)
- sbin,管理员程序(super bin)
- share,存放二进制源码(Java jar包)
配置 Hadoop 伪分布式,我们主要涉及到如下文件的修改:
- core-site.xml: Hadoop 核心配置文件
- hdfs-site.xml: HDFS 核心配置文件
这些文件均存在与 $HADOOP_HOME/etc/hadoop 文件夹中,用于设置 Hadoop 集群的各种参数,如 HDFS 的端口号、NameNode 的地址等。Hadoop 的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
PS:$HADOOP_HOME是设置的环境变量,其指代 Hadoop 安装文件夹即 /usr/local/hadoop-3.1.3
1、修改配置文件 core-site.xml
hadoop.tmp.dir
hadoop.tmp.dir 是 Hadoop 框架中的关键配置参数,用于指定临时数据和关键元数据的存储位置。它对于 Hadoop 的稳定运行和数据安全至关重要,特别是在处理大规模数据集时。合理配置这个目录,可以确保中间文件和关键信息得到妥善保存,避免因系统重启或临时目录被清空而导致的数据丢失。因此,在部署和配置 Hadoop 时,建议根据实际需求调整 hadoop.tmp.dir 的路径,并确保其指向持久化的存储位置。这里我们给它设置为 Hadoop 安装目录下的 tmp 文件夹,对于我的安装目录来说,具体路径在 /usr/local/hadoop-3.1.3/tmp,大家可以根据自己的安装目录进行一定的调整。
fs.defaultFS
fs.defaultFS 是 Hadoop 框架中一个重要的配置参数,它用于指定集群中默认的文件系统路径。这个路径通常是 HDFS(Hadoop Distributed FileSystem)的 URI,但也可以是其他支持的文件系统,如本地文件系统、Amazon S3 等。通过配置 fs.defaultFS,Hadoop 应用程序可以无缝地访问和操作存储在这些文件系统中的数据。
这次我们选择用 gedit 而不是 vim 来编辑。gedit 是文本编辑器,类似于 Windows 中的记事本,会比较方便。保存后记得关掉整个 gedit 程序,否则会占用终端。
PS:使用 gedit 需要直接操作虚拟机,不能在远程连接工具操作,否则可能会打不开图形化编辑器。😅
1 | # 改变当前工作目录到 /usr/local/hadoop-3.1.3 |
将当中的
1 | <configuration> |
修改为下面配置:
1 | <configuration> |
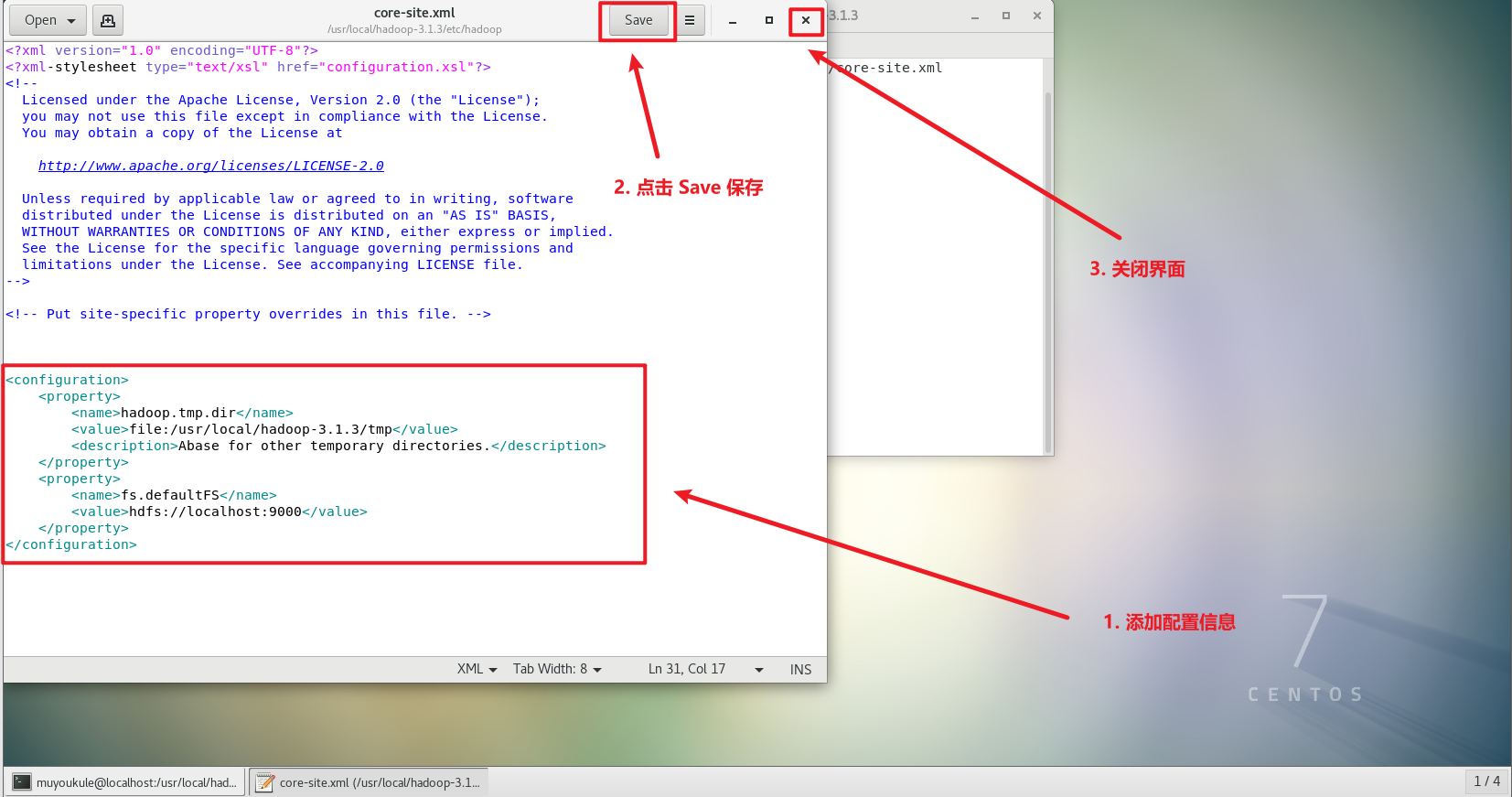
2、同理修改配置文件 hdfs-site.xml
dfs.replication
dfs.replication 是 Hadoop 分布式文件系统(HDFS)中的关键参数,用于指定每个数据块在HDFS中存储的副本数。合理配置该参数可以平衡数据可靠性、存储资源消耗和性能需求,确保HDFS在高可用性和容错性方面表现出色。
dfs.namenode.name.dir 和 dfs.datanode.data.dir
dfs.namenode.name.dir 用于指定保存 HDFS 元数据的目录,包括文件系统的命名空间、属性及块位置等信息,确保元数据的安全存储和可靠访问。
dfs.datanode.data.dir 则用于指定存放 HDFS 数据块文件的目录,是数据节点存储实际数据的本地路径,确保数据的分布式存储和高效访问。
1 | # 打开 hdfs-site.xml 文件 |
1 | <configuration> |
3、配置完成后,执行以下命令格式化 NameNode ,成功的话会看到 successfully formatted。
1 | # 格式化 NameNode |

4、接着执行一下命令,开启 NameNode 和 DataNode 守护进程
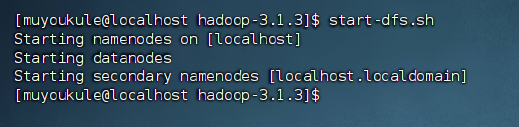
1 | # start-dfs.sh 是个完整的可执行文件,中间没有空格 |
若出现 SSH 的提示 Are you sure you want to continue connecting,输入 yes 即可。最终出现如下画面:
假如出现以下异常请参考:解决Hadoop伪分布式中localhost: ERROR: JAVA_HOME is not set and could not be found)

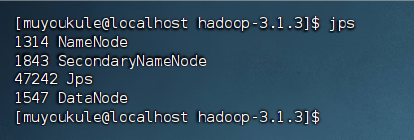
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode”和SecondaryNameNode(如果 SecondaryNameNode 没有启动,请运行 stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
1 | # 判断是否成功启动 |
成功启动后,可以访问 Web 界面查看 HDFS 的 NameNode 状态,可以在线查看 HDFS 中的文件。
PS:访问 WEB 界面时,hadoop 3.x 以下版本的端口为 50070,hadoop 3.x 以上版本的端口为 9870。一定要使用相应的版本访问相应的端口,不然访问不成功!!!!😱😱😱
其实在最开始的时候我也不知道 hadoop 3.x 以上版本的端口号发生了变化😭,而我自己安装的 hadoop 版本为 3.1.3,这就导致了我访问 50070 端口时肯定是失败的😫。在网上进行查阅,发现网上描述出现这个情况的原因无非以下几点:防火墙没关闭;端口被占用;$HADOOP_HOME/etc/hadoop 下的 core-site.xml 和 hdfs-site.xml 没有配置好。我也根据这些问题一一进行排查,尽管没有出现以上问题结果还是访问不了,于是我百思不得其解,跑去 Hadoop 官网查看默认配置项才发现端口号已经发生了改变:

在Hadoop中,dfs.namenode.http-address 是配置参数,用于指定 NameNode Web UI 监听的地址和基端口。这个 Web UI 提供了关于 HDFS 集群状态、配置、以及文件浏览等信息的可视化界面。
发现端口发生改变后我去网上查阅,最后才知道 hadoop 3.x 以下版本的端口为 50070,hadoop 3.x 以上版本的端口变化为了 9870。
最后将Hadoop 官网查看默认配置项链接放在这儿:Apache Hadoop 3.4.0 – MapReduce Tutorial 。大家打开后下拉在左下角找到 Configuration 然后点击 hdfs-site.xml 进入页面在 dfs.namenode.http-address 配置参数就可以查看到端口。

两种访问方式:
- 虚拟机访问
- 本机访问
第一种:虚拟机访问
PS:需要直接操作虚拟机,不能在远程连接工具操作,否则会报错。😅
CentOS 自带有 Firefox 浏览器,不过一般比较旧,有很多兼容性问题,可以先卸载掉再安装新版的 Firefox ,安装成功后再查看版本。
1 | # 卸载 Firefox |
查看 Firefox 版本:
输入命令直接打开 Firefox 浏览器:
1 | # 打开 Firefox 浏览器 |
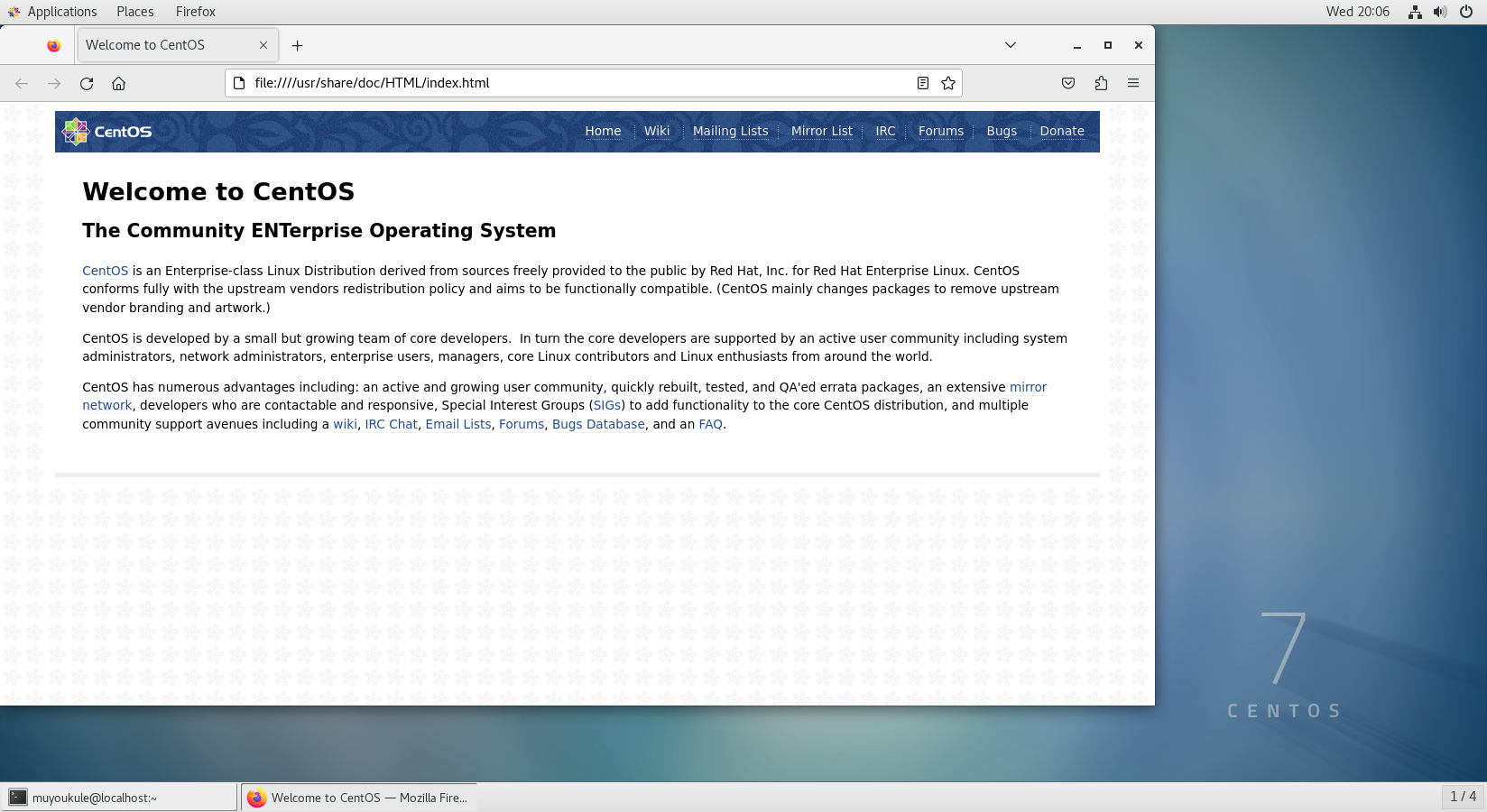
浏览器输入 http://localhost:9870 成功访问到 Web 界面。
第二种:本机访问
PS:本机访问需要关闭虚拟机防火墙,不然访问不了。(自己虚拟机的防火墙无所谓随便关闭,真实的环境中不建议绝对不能这样做,真实的环境一般是开放指定端口)😶
首先查看防火墙状态。出现绿色 Active:active (running) 表示开启,出现白色 Active:inactive (dead) 表示关闭。然后自行对其进行设置。
1 | # 查看防火墙状态 |
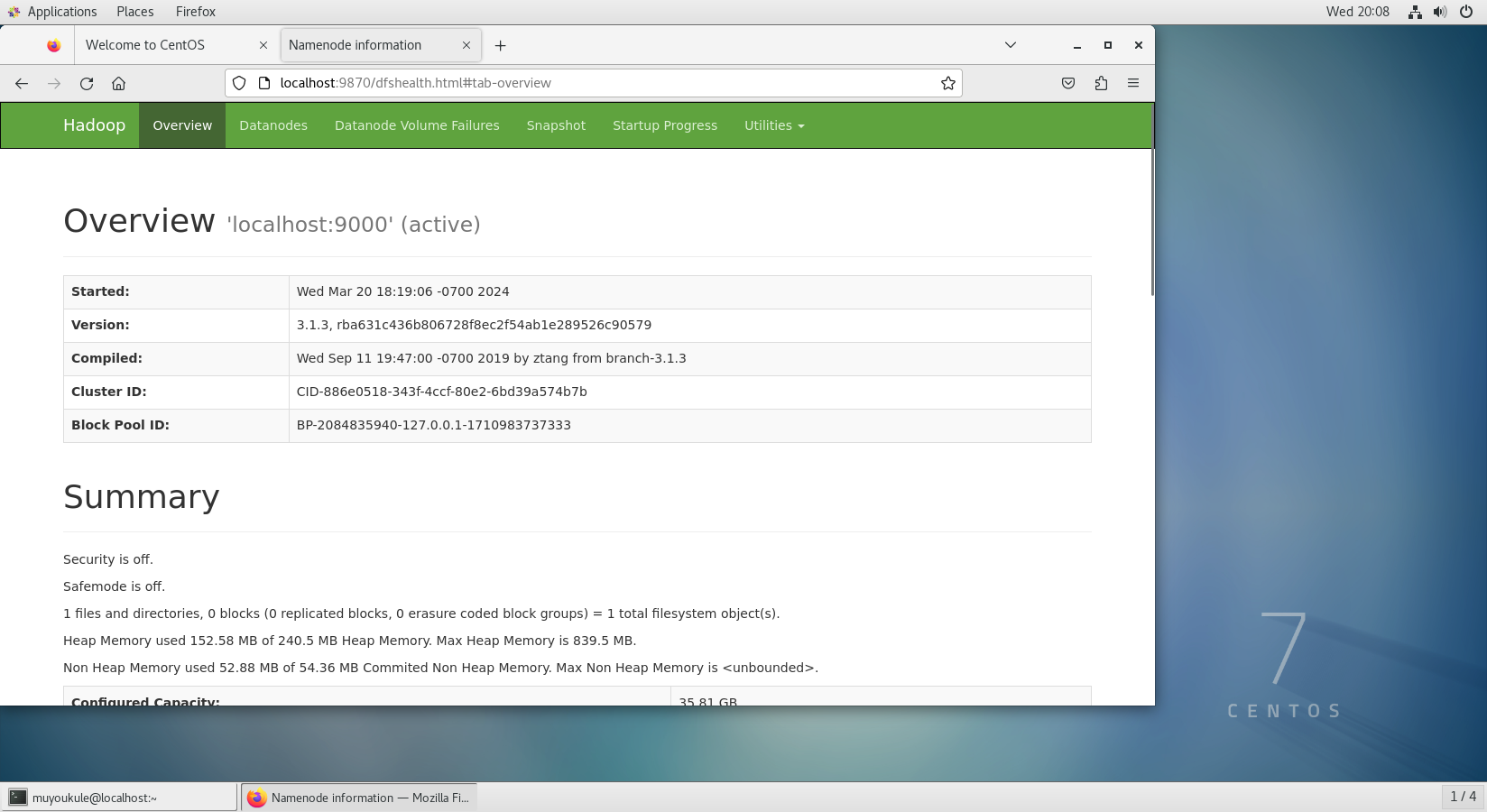
直接打开本机浏览器输入 http://192.168.88.131:9870/ 成功访问到 Web 界面。PS:这里的 192.168.88.131 是虚拟机 ip 地址。
PS:在启动 Hadoop 的时候如果已有 Hadoop 节点在运行,要先关闭所有 Hadoop 服务再启动。
1 | # 关闭 Hadoop |
2.5 运行 Hadoop 伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录(用户名目录名可以随意输入,我这里输入的是 muyoukule ):
1 | # 改变当前工作目录到 /usr/local/hadoop-3.1.3 |
创建成功后可以在 /user 目录下查看到用户目录,查看用户目录应该为空,因为目录下没有内容。

接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop-3.1.3/etc/hadoop 复制到分布式文件系统中的 /user/muyoukule/input 中。我使用的是 muyoukule用户,并且已创建相应的用户目录 /user/muyoukule,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/muyoukule/input:
1 | # 在 HDFS 上创建一个名为 input 的目录 |
复制完成后,可以通过如下命令查看文件列表:
1 | hdfs dfs -ls input |

伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是 HDFS 中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
1 | # 执行一个 MapReduce 作业,该作业使用 Hadoop 自带的 grep 示例程序来搜索 input 目录中匹配给定模式的行,并将结果写入 output 目录 |
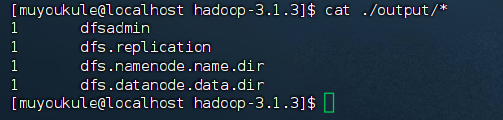
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
1 | hdfs dfs -cat output/* |
如果出现:INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 表示SASL数据传输客户端在进行加密信任检查时,发现本地主机(localHost)和远程主机(remoteHost)都没有被信任。可以不用管它。

将运行结果取回到本地:
1 | # 删除本地文件系统中的 output 目录及其所有内容(如果存在) |
Hadoop 运行程序时,输出目录不能存在,否则会提示错误,因此若要再次执行,需要执行如下命令删除 output 文件夹:
1 | # 删除 HDFS 上的 output 目录及其所有内容 |
若要关闭 Hadoop,则运行:
1 | stop-dfs.sh |

注意:下次启动 Hadoop 时,无需进行 NameNode 的初始化,只需要运行 start-dfs.sh 就可以!
2.6 启动 YARN
PS:伪分布式不启动 YARN 也可以,一般不会影响程序执行。
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性,YARN 的更多介绍在此不展开,有兴趣的可查阅相关资料。
上述通过 start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
1、修改 yarn-site.xml 文件,同样使用 gedit 编辑会比较方便些。( gedit 编辑器使用方法请参照上文 Hadoop 伪分布式配置)
1 | # 改变当前工作目录到 /usr/local/hadoop-3.1.3 |
修改为如下配置:
1 | <configuration> |
2、修改 mapred-site.xml 文件,如果没有这个文件,需要从 mapred-site.xml.template 复制一份。
1 | # 打开 mapred-site.xml 文件 |
1 | <configuration> |
3、启动YARN服务,(需要先执行过 start-dfs.sh):
1 | # 启动YARN |

4、验证是否启动成功
方式一:执行 jps 命令查看 NodeManager 和 ResourceManager 服务是否已经启动:
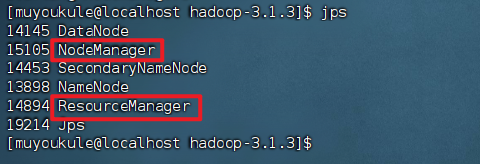
方式二:虚拟机浏览器输入 http://localhost:8088 成功访问到 Web 界面。
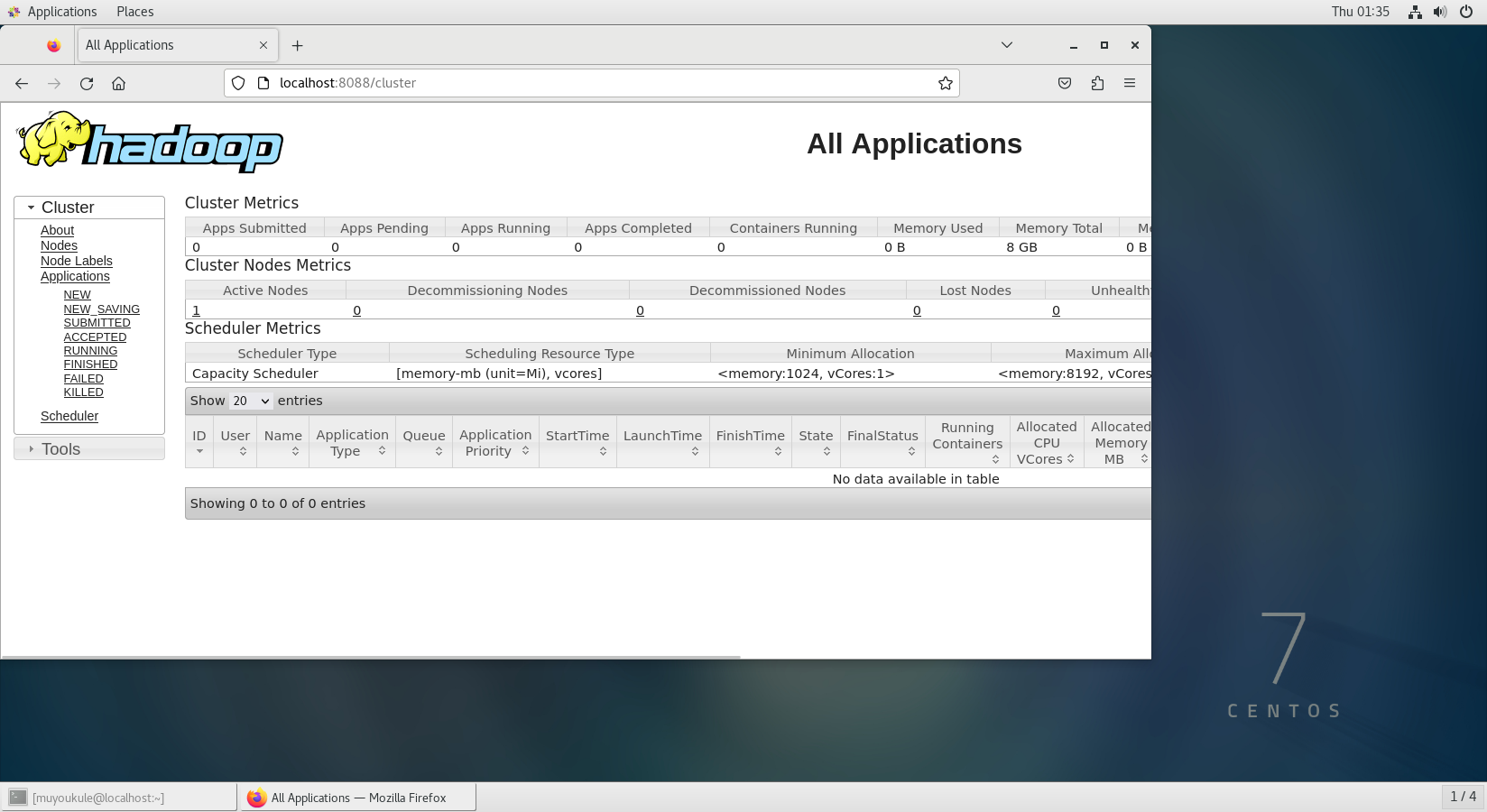
但 YARN 主要是为集群提供更好的资源管理与任务调度,然而这在单机上体现不出价值,反而会使程序跑得稍慢些。因此在单机上是否开启 YARN 就看实际情况了。
不启动 YARN 需重命名 mapred-site.xml
如果不想启动 YARN,务必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用时改回来就行。否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的错误。
1 | # 重命名 |
同样的,关闭 YARN 的脚本如下:
1 | # 关闭 YARN |
至此,你已经掌握 Hadoop 的配置和基本使用了。
2.7 Hadoop 集群配置
伪分布式配置主要用于开发和测试环境,因为它将 NameNode 和 DataNode 放在同一台机器上,可能无法充分利用多节点的并行处理能力。在生产环境中,通常会使用完全分布式配置,以利用集群中多台机器的计算和存储能力。
配置安装集群化软件,首要条件就是要有多台Linux服务器可用。我们可以使用 VMware 提供的克隆功能,基于一台虚拟机去克隆创建多台虚拟机,所以这对电脑配置要求很高(至少有 8G 运行内存和 512G 存储容量)。但是由于我的电脑剩余存储空间容量有限……😭😭😭且在此实验案例教程后续还涉及很多软件的安装,所以我的电脑已经不再支持我配置安装集群化软件。但是如果你对Hadoop 集群配置感兴趣电脑运行内存和剩余存储容量足够大,不妨可以自己在网上找找教程动手试试。😄
3. MySQL
MySQL 是一个开源的关系型数据库管理系统,它使用结构化查询语言(SQL)进行数据库管理。MySQL 具有高可靠性、高性能、易用性和灵活性等特点,能够处理大量数据,并支持多种存储引擎以满足不同应用需求。它广泛应用于各类网站、应用及企业级系统中,是众多开发者和企业的首选数据库解决方案。通过 MySQL,用户可以轻松地创建、查询、更新和删除数据库中的数据,实现高效的数据管理。
3.1 MySQL 下载与安装
关于安装 MySQL的方式有很多这里只示例其中一种:使用 yum 安装。
yum 安装方式自动处理依赖、简化安装过程、提供版本管理,并且易于管理和维护,适合大多数用户。完全可以满足本案例需求。
1、首先打开 MySQL Yum Repository
打开后根据你服务器的配置选择,我服务器是 CentOS7 所以选择 Red Hat Enterprise Linux 7 / Oracle Linux 7 (Architecture Independent), RPM Package ,然后点击 Download 下载进入下载页面,进入页面后鼠标光标定位到 No thanks, just start my download. 右键点击 复制链接 (https://dev.mysql.com/get/mysql80-community-release-el7-11.noarch.rpm)。
.png)
.png)
2、安装前需要对系统进行检查:
RPM(Red-Hat Package Manager)是软件包管理器,是红帽 Linux 用于管理和安装软件的工具。
1 | # 如果当前系统已经安装过 Mysql 数据库安装将失败。CentOS 自带 mariadb,与 Mysql 数据库冲突。 |

3、开始安装:
1 | # 更新密钥 |
4、选择要安装的 MySQL 版本:
添加完 yum 源之后,如果什么都不做直接安装的话,会默认安装最新的 MySQL 版本,也就是 mysql8.0 的最新发行版。大家可以自行进行选择。我这里选择的是 mysql5.7 ,所以要改一下配置(想直接装最新版本的可以跳过这一步):
1 | # 当前 mysql yum 源下哪些子源可用(不同的 mysql 版本使用不同的子仓库 |
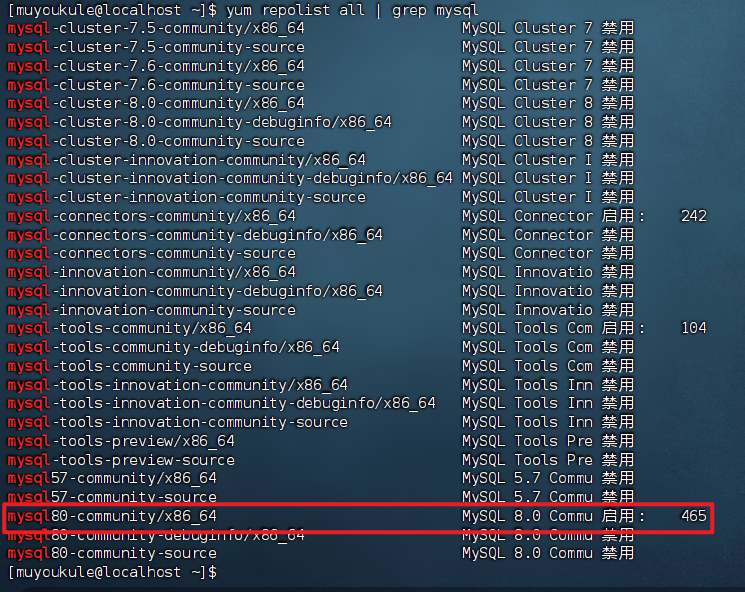
可以看到默认开启的是 mysql8.0 的仓库。
开启 5.7,禁用 8.0 有两种方法,一个是用命令修改 /etc/yum.repos.d/mysql-community.repo 文件。另一个是像下面这样使用命令直接修改这个文件。
1 | # 禁用名为 mysql80-community 的软件仓库 |
然后再执行查看语句,可以看到 mysql 5.7 已经启用了,8.0 已经禁用了。
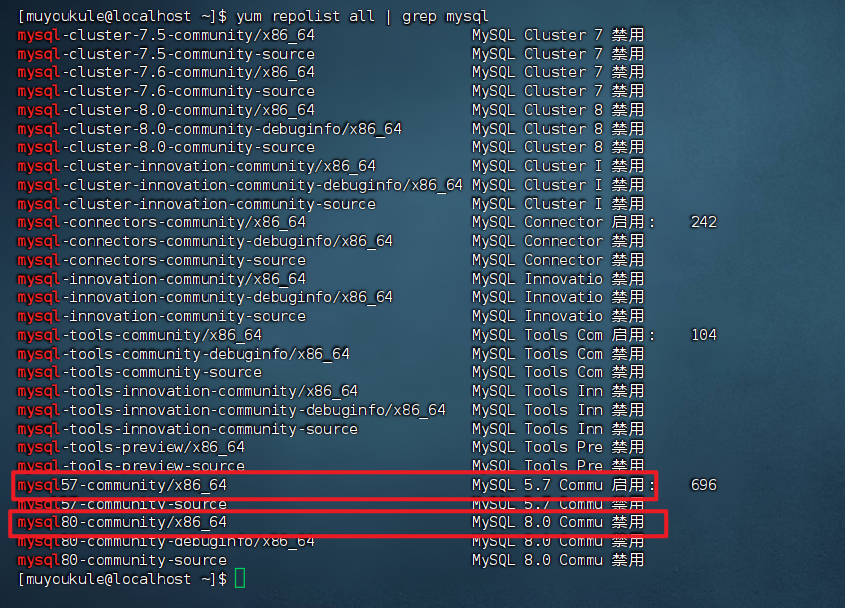
5、安装 MySQL
1 | # yum 安装 mysql-community-server 这个包 |
出现 Active:active(running) 代表 MySQL 启动成功。
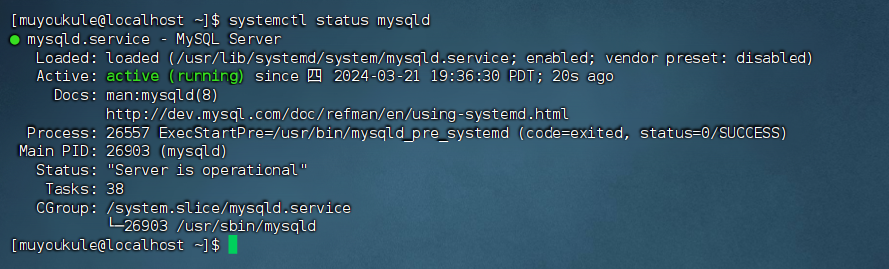
6、登录 MySQL
查看默认密码:第一次启动 MySQL 会在日志文件 /var/log/mysqld.log 中生成 root 用户的一个随机密码。
1 | # 查看密码 |

PS:没有前面的空格,比如我密码的是 fcIVZvOBk9)r 。
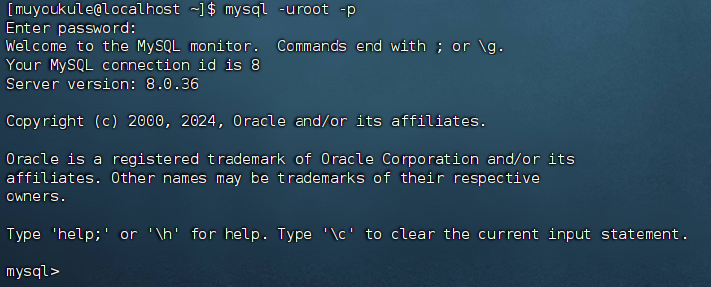
然后执行命令登录 MySQL 数据库服务器,会提示输入密码,输入密码时密码不会显示,输入完直接 Enter 就行。
1 | # 登录到 MySQL 数据库服务器 |
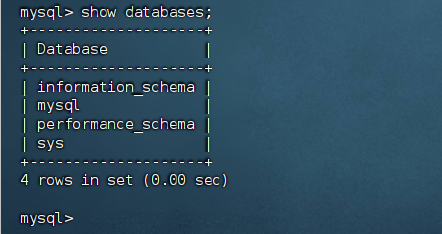
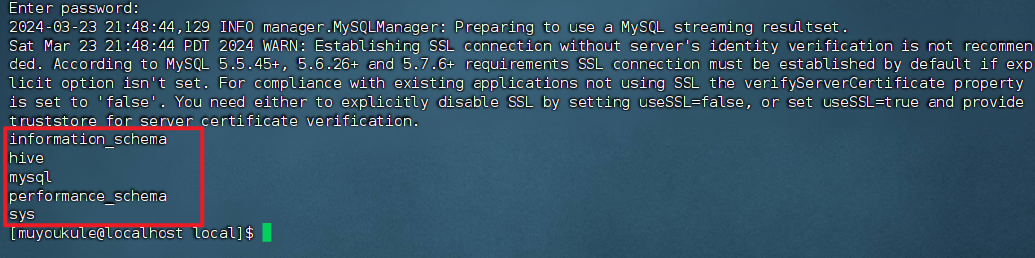
登录到 MySQL 后可以执行以下 SQL 语句查看数据库,与下面一致说明安装成功。
1 | # 列出服务器上的所有数据库 |
退出MySQL:
1 | exit # 或者快捷键 Ctrl + d |
3.2 关于 MySQL 的补充
3.2.1 修改 root 用户密码
如果你觉得 MySQL 自动生成的密码太难记忆的话,可以连接 MySQL 之后进行修改密码。在 Linux 上安装 MySQL 时会自动安装一个校验密码的插件,默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位。修改密码时新密码是否符合当前的策略,不满足则会提示ERROR。
如果你想设置简单密码,需要降低 MySQL 的密码安全级别。
1 | #设置密码安全级别低 |
PS:若在执行 set global validate_password_policy = 0; 时提示 You must reset your password using ALTER USER statement before executing this statement. 你可以先设置一个满足默认策略的密码如:@Root123456 ,替换掉默认生成的密码,之后再进行密码安全级别的降低,就可以成功了。
另外:因 mysql 的版本不同调整密码策略的方法也不同,关于更多的密码检查策略请参考官方文档。
在文档中先选择对应版本再搜索:validate_password
.png)
.png)
.png)
上面这个就是密码检查策略了。
3.2.2 创建用户与权限分配
默认的 root 用户只能当前节点 localhost 访问,是无法远程访问的。
我们还需要创建一个新的账户,用于远程访问,或者直接给 root 用户添加权限。
1 | # 授予来自任何主机的 root 用户对所有数据库和所有表的所有权限,并允许其将这些权限授予其他用户。 |
授权后就可以使用在本机使用图形化工具远程访问虚拟机的 MySQL 。(这里使用的是 Navicat )
首先检查防火墙状态,关闭防火墙:
1 | # 查看防火墙状态 |
打开 Navicat 进行操作:
.png)
在 Navicat 上看到的数据库与虚拟机一致,远程连接成功。
.png)
4. HBase
HBase 是一个分布式、面向列的开源数据库,基于 Hadoop 构建,以 BigTable 为设计蓝本,具有高可靠性、高扩展性和高性能,适用于存储和处理海量非结构化及半结构化数据,广泛应用于大数据场景下的数据存储和实时分析。
开启 HBase 需要先开启 Hadoop,而关闭 Hadoop 必须先关闭 HBase,所以总的流程顺序就是:
开启 Hadoop –> 开启 HBase –> 关闭 HBase –> 关闭 Hadoop😀
请一定严格按照顺序进行,否则可能会出现错误,如果不确定是否有开启其中的某个服务,可以使用 jps 命令进行查看进程 id。
4.1 HBase 下载与安装
.png)
.png)
打不开官网?试试清华大学开源软件镜像站下载。不过好像只有新版🤔
下载好之后就可以开始安装了:
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 Hadoop 安装文件到 /usr/local 目录,解压完成后可以进入到 /usr/local 目录查看是否成功。
1 | # 解压缩安装文件到 /usr/local 目录 |
3、配置环境变量,使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
4、重启环境变量配置
1 | source /etc/profile |
5、添加 HBase 权限
输入下面命令,把 hbase 目录权限赋予给 muyoukule 用户:
1 | # 进入 /usr/local 目录 |
6、检查安装结果,出现下面信息代表安装成功
1 | # 查看 hbase 版本信息 |

假如出现 找不到或无法加载主类 org.apache.hadoop.hbase.util.GetJavaProperty 的错误,解决方法:
修改 /usr/local/hbase/conf/hbase-env.sh 配置文件
1 | vim /usr/local/hbase-2.2.2/conf/hbase-env.sh |
到配置文件底部,将 # export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" 前的注释( # 号)删除即可,删除后保存并退出即可。
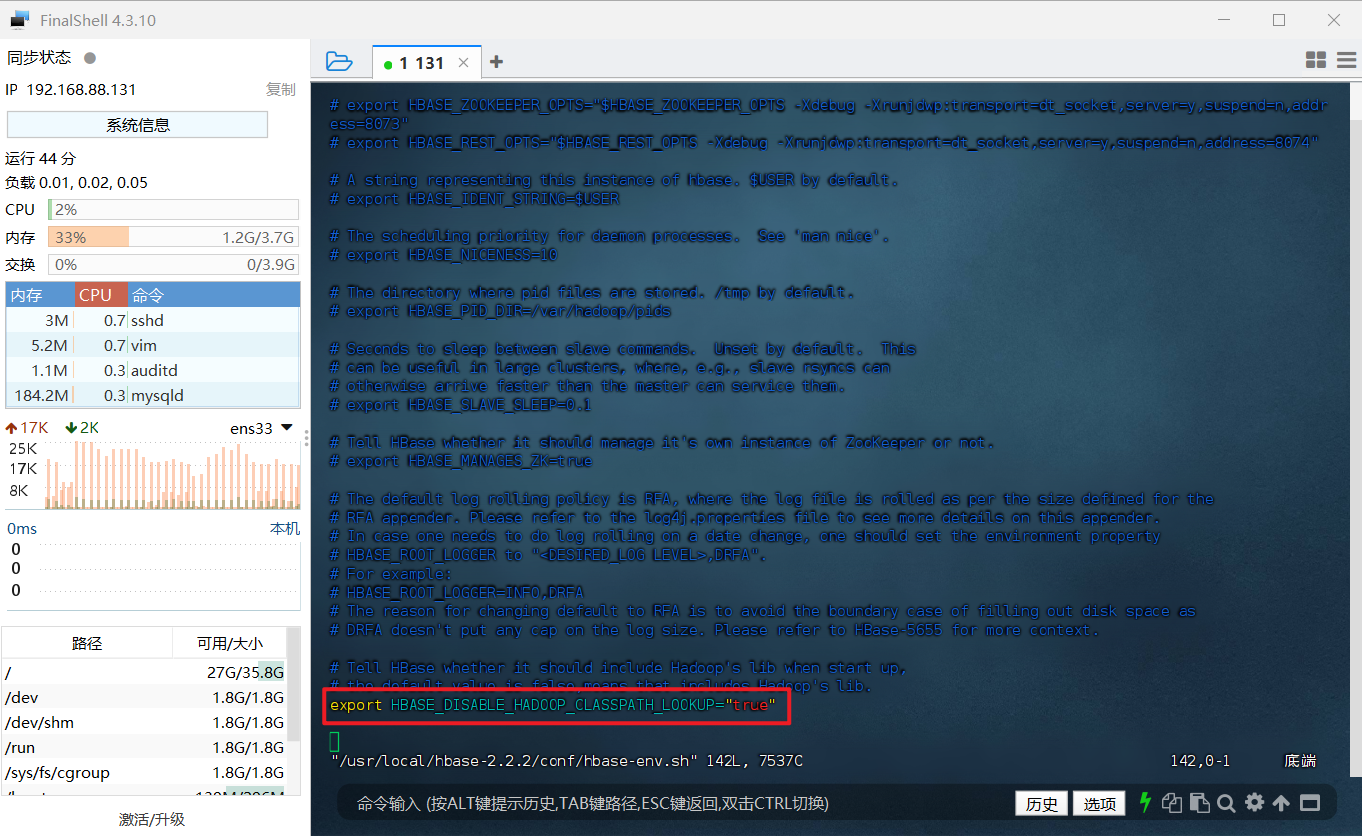
这样,HBase 就安装好了。
4.2 HBase 单机模式配置
HBase单机模式配置时涉及的两个主要配置文件是 hbase-env.sh 和 hbase-site.xml 。这两个文件分别用于设置 HBase 的运行环境和定义 HBase 的核心配置参数。
hbase-env.sh
hbase-env.sh 是一个 shell 脚本文件,它包含了 HBase 启动和运行所需的环境变量设置。在单机模式下配置 HBase 时,需要检查并可能修改以下几个关键的配置项:
JAVA_HOME:这个变量需要指向你安装的 JDK 的目录。确保 HBase 可以找到并使用正确的 Java 版本。HBASE_MANAGES_ZK:这个变量控制 HBase 是否应该管理其自己的 ZooKeeper 实例。在单机模式下,通常将其设置为true,这样 HBase 就会启动它自己的 ZooKeeper 实例。- 其他环境变量:根据具体的系统配置和需求,可能还需要设置其他环境变量。
hbase-site.xml
hbase-site.xml是 HBase 的核心配置文件,其中包含了 HBase 集群的各种参数设置。在单机模式下配置 HBase 时,你需要修改或添加以下关键配置项:
hbase.rootdir:这个参数定义了 HBase 数据的存储位置。在单机模式下,通常将其设置为本地文件系统的某个路径,例如file:///tmp/hbase。这意味着所有的 HBase 数据都将存储在这个指定的本地目录中。hbase.zookeeper.property.dataDir:这个参数指定了 ZooKeeper 使用的数据目录。由于在单机模式下 HBase 通常会管理自己的 ZooKeeper 实例,因此需要设置这个参数来指定 ZooKeeper 数据的存储位置。hbase.cluster.distributed:这个参数控制 HBase 是否以分布式模式运行。在单机模式下,通常将其设置为false。
需要注意的是,对于配置文件的修改,需要手动重启相应的 HBase 服务。更改配置文件后,请运行 stop-hbase.sh 以停止 HBase 服务,配置完成后再运行start-hbase.sh 以启动服务。
配置 hbase-env.sh
在启动HBase前,需设置 JAVA_HOME 环境变量。为方便用户,HBase 允许在 conf/hbase-env.sh 文件中直接设置。用户需找到 Java 安装位置后编辑 conf/hbase-env.sh,取消对 #export JAVA_HOME= 行的注释,并设置为 Java 安装路径。
先查找 Java 安装位置(如果你知道可以忽略)
1 | # 查找 Java 安装位置 |
这里我们找到了不止一个路径,我们需要自行进行判断,我的是 /usr/local/jdk1.8.0_162

1、使用 vim 编辑器打开 hbase-env.sh 文件
1 | vim /usr/local/hbase-2.2.2/conf/hbase-env.sh |
2、配置 Java 的环境变量
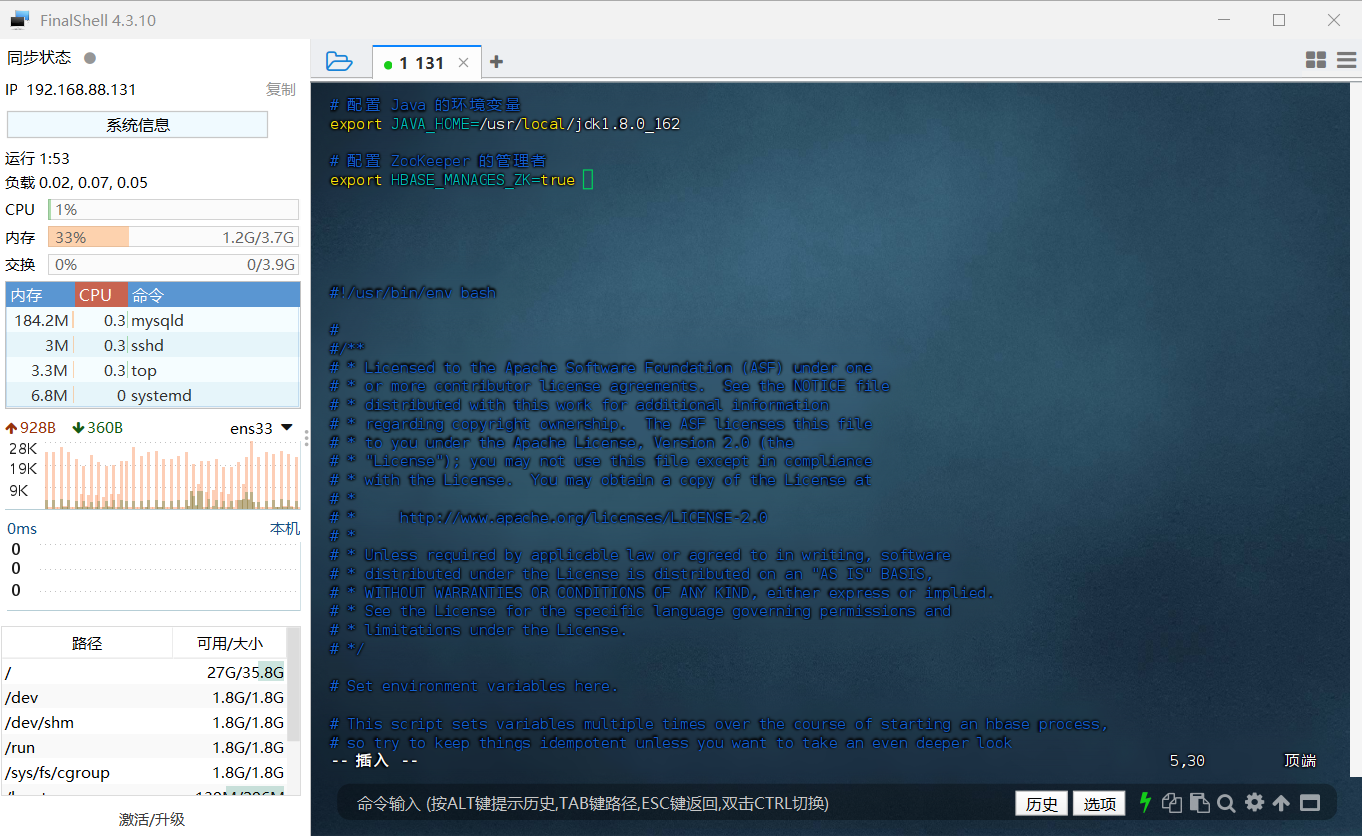
具体作用是告诉 HBase 使用哪一个 jdk,我这里 Java 的安装目录是 /usr/local/jdk1.8.0_162,还需要配置令 ZooKeeper 由 HBase 自己管理,不需要单独的 ZooKeeper,具体需要添加的内容如下:
1 | # 配置 Java 的环境变量 |
因为在 hbase-env.sh 文件中已经存在有 JAVA_HOME、HBASE_MANAGES_ZK 这两个变量,但只是被注释掉了,也就是前面带了 # 号,所以大家可以直接寻找到对应的变量,将前面起注释作用的 # 号删去,然后修改后面的值即可。
PS:vim 编辑器怎样搜索字符串?
- 普通模式下,按下
/键,然后输入你想要搜索的字符串,按下Enter键开始搜索。 - 要查找下一个匹配的字符串,按
n。 - 要查找上一个匹配的字符串,按
N。
但是我很懒不想去找🙄,所以我就直接写在文件顶部了,这个是不影响运行操作的,具体图示如下:
配置 hbase-site.xml
这里我们需要修改文件中的 hbase.rootdir 、hbase.unsafe.stream.capability.enforce 两个参数:
hbase.rootdir 是 HBase 配置中的一个关键参数,用于指定 HBase 数据和元数据的根存储目录。该目录是 HBase 用来存放所有表数据、索引、日志文件以及其他相关信息的核心位置。通过正确配置 hbase.rootdir,可以确保 HBase 数据被存储在一个持久化、可靠且可扩展的存储系统中,从而保障 HBase 的稳定运行和数据的安全性。这里我们给它设置为 HBase 安装目录下的 hbase-tmp 文件夹,对于我的安装目录来说,具体路径在 /usr/local/hbase-2.2.2/hbase-tmp,大家可以根据自己的安装目录进行一定的调整。
hbase.unsafe.stream.capability.enforce:这个配置项用于启用或禁用 TFramedTransport或者TLowDelayTransport的帧大小检查,在默认情况下会启用帧大小检查,用于保证网络连接和数据传输的稳定性,也就是把他的值设置为 true,因为我们现在是伪分布模式,所以不需要保证稳定性,可以选择禁用帧大小检查,从而提升数据传输性能,就是将它的值设置为 flase。当然,也可以不管这个配置项,主要是看个人需求。
1、使用 gedit 编辑器修改其文件内容,具体命令如下
1 | gedit /usr/local/hbase-2.2.2/conf/hbase-site.xml |
将当中的
1 | <configuration> |
修改为下面配置:
1 | <configuration> |
2、测试运行
启动 HBase,并且打开 shell 命令行模式,成功打开后,用户就可以通过输入 shell 命令来使用操作 HBase 数据库了。具体命令如下:
1 | # 启动 HBase |
出现下面图示的样子,就说明 shell 命令行被成功打开了,可以看到,还有 hbase(main) 的字样:

输入 help,可以获取帮助信息,帮助你更好的熟悉使用方法,还可以看见当前 HBase 的版本,如下图所示:

3、输入 exit或者 Ctrl + d 就可以退出该模式,返回终端控制台。
4、停止 HBase 运行,在终端输入下面命令:
1 | # 停止 HBase 运行 |
PS:如果在操作 HBase 的过程中发生错误,可以通过 {HBASE_HOME}目录(/usr/local/hbase-2.2.2)下的 logs 子目录中的日志文件查看错误原因。
4.3 HBase 伪分布式模式配置
HBase伪分布式模式配置时涉及的两个主要配置文件是 hbase-env.sh 和 hbase-site.xml 。这两个文件分别用于设置 HBase 的运行环境和定义 HBase 的核心配置参数。
hbase-env.sh
hbase-env.sh 是一个 shell 脚本文件,它包含了 HBase 启动和运行所需的环境变量设置。在单机模式下配置 HBase 时,需要检查并可能修改以下几个关键的配置项:
JAVA_HOME:这个变量需要指向你安装的 JDK 的目录。确保 HBase 可以找到并使用正确的 Java 版本。HBASE_MANAGES_ZK:这个变量控制 HBase 是否应该管理其自己的 ZooKeeper 实例。在单机模式下,通常将其设置为true,这样 HBase 就会启动它自己的 ZooKeeper 实例。- 其他环境变量:根据具体的系统配置和需求,可能还需要设置其他环境变量。
hbase-site.xml
hbase-site.xml是 HBase 的核心配置文件,其中包含了 HBase 集群的各种参数设置。在单机模式下配置 HBase 时,你需要修改或添加以下关键配置项:
hbase.rootdir:这个参数定义了 HBase 数据的存储位置。在单机模式下,通常将其设置为本地文件系统的某个路径,例如file:///tmp/hbase。这意味着所有的 HBase 数据都将存储在这个指定的本地目录中。hbase.zookeeper.property.dataDir:这个参数指定了 ZooKeeper 使用的数据目录。由于在单机模式下 HBase 通常会管理自己的 ZooKeeper 实例,因此需要设置这个参数来指定 ZooKeeper 数据的存储位置。hbase.cluster.distributed:这个参数控制 HBase 是否以分布式模式运行。在单机模式下,通常将其设置为false。
需要注意的是,对于配置文件的修改,需要手动重启相应的 HBase 服务。更改配置文件后,请运行 stop-hbase.sh 以停止 HBase 服务,配置完成后再运行start-hbase.sh 以启动服务。
配置 hbase-env.sh
在启动HBase前,需设置 JAVA_HOME 环境变量。为方便用户,HBase 允许在 conf/hbase-env.sh 文件中直接设置。用户需找到 Java 安装位置后编辑 conf/hbase-env.sh,取消对 #export JAVA_HOME= 行的注释,并设置为Java安装路径。
先查找 Java 安装位置(如果你知道可以忽略)
1 | # 查找 Java 安装位置 |
这里我们找到了不止一个路径,我们需要自行进行判断,我的是 /usr/local/jdk1.8.0_162
1、使用 vim 编辑器打开 hbase-env.sh 文件
1 | vim /usr/local/hbase-2.2.2/conf/hbase-env.sh |
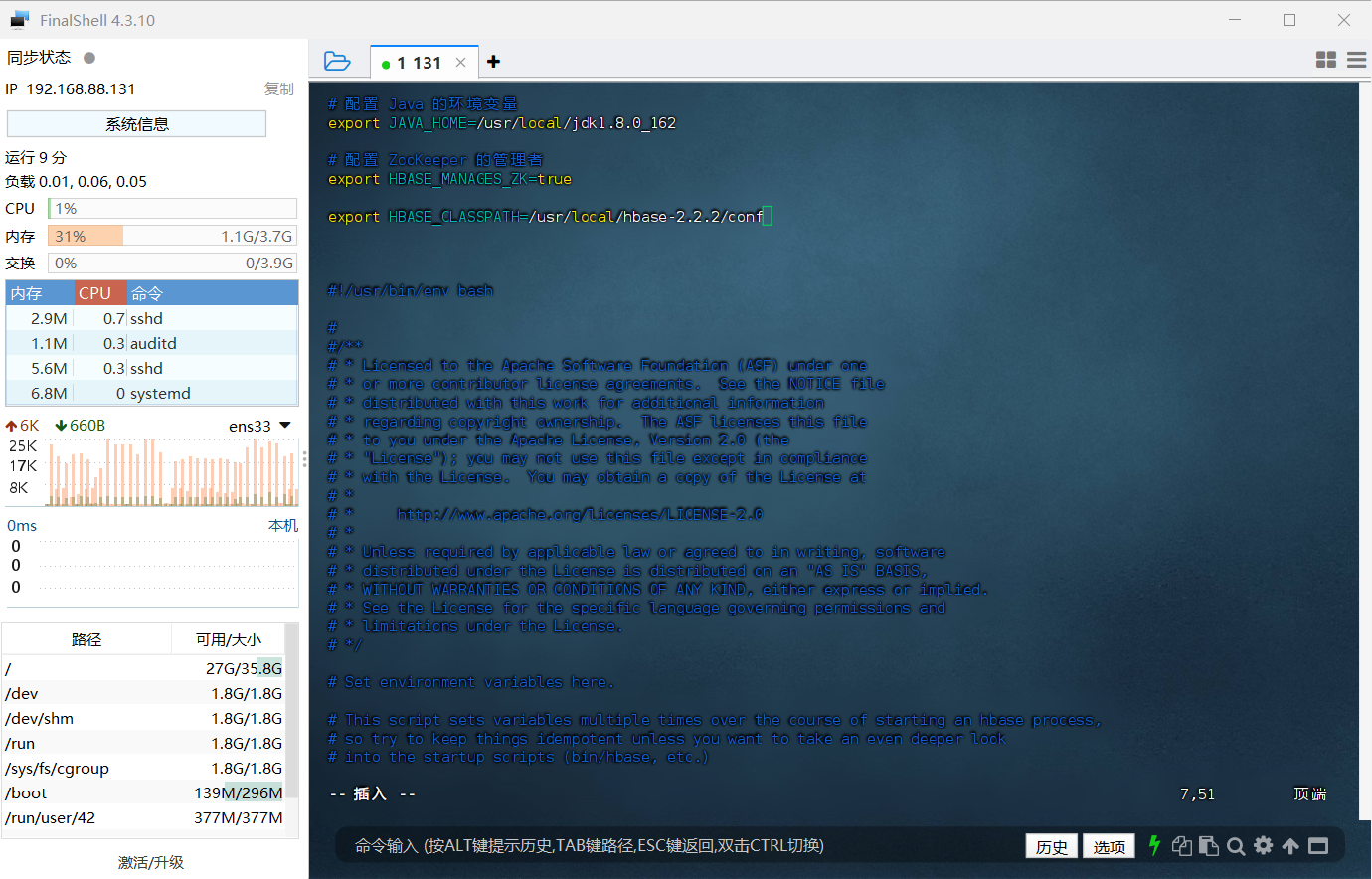
2、配置 JAVA_HOME,具体作用是告诉 HBase 使用哪一个 jdk,我这里 Java 的安装目录是 /usr/local/jdk1.8.0_162;HBASE_MANAGES_ZK 配置令 ZooKeeper 由 HBase 自己管理,不需要单独的 ZooKeeper。HBASE_CLASSPATH 变量可用于确定运行自定义 HBase 操作所需的其他 JAR 文件和目录的优先级。最后是具体需要添加的内容如下:
1 | # 配置 Java 的环境变量 |
因为在 hbase-env.sh 文件中已经存在有 JAVA_HOME、HBASE_MANAGES_ZK、HBASE_CLASSPATH 这三个变量,只是被注释掉了,也就是前面带了 # 号,所以大家可以直接寻找到对应的变量,将前面起注释作用的 # 号删去,然后修改后面的值即可。
PS:vim 编辑器怎样搜索字符串?
- 普通模式下,按下
/键,然后输入你想要搜索的字符串,按下Enter键开始搜索。 - 要查找下一个匹配的字符串,按
n。 - 要查找上一个匹配的字符串,按
N。
但是我很懒不想去找🙄,所以我就直接写在文件顶部了,这个是不影响运行操作的,具体图示如下:
配置 hbase-site.xml
这里我们需要修改文件中的 hbase.rootdir、hbase.cluster.distributed、hbase.unsafe.stream.capability.enforce 三个参数。
hbase.rootdir:举个例子,如果要指定 HDFS 实例的 Namenode 在 nameenode.example.org 上运行的 HDFS 目录 /hbase-2.2.2,端口为 9000,则需要将此值设置为:hdfs://namenode.example.org:9000/hbase-2.2.2,因为我们做的是伪分布,所以这里我们就将它设置在本机的 9000 端口号上。
hbase.cluster.distributed:这个参数用于设置群集将处于的模式。对于分布式模式,值设置为 true,因为我们做的是伪分布模式,所以我们将其值设置为 true。
hbase.unsafe.stream.capability.enforce:这个配置项用于启用或禁用 TFramedTransport或者TLowDelayTransport的帧大小检查,在默认情况下会启用帧大小检查,用于保证网络连接和数据传输的稳定性,也就是把他的值设置为 true,因为我们现在是伪分布模式,所以不需要保证稳定性,可以选择禁用帧大小检查,从而提升数据传输性能,就是将它的值设置为 flase,另外,此属性可能会减少故障切换选项,所以在启用的时候需要谨慎,所以我们这里禁用它也有这一层原因。
1、使用 gedit 编辑器修改其文件内容,具体命令如下
1 | gedit /usr/local/hbase-2.2.2/conf/hbase-site.xml |
将当中的
1 | <configuration> |
修改为下面配置:
1 | <configuration> |
2、接下来测试运行 HBase
第一步:首先登陆 ssh,之前设置了无密码登陆,因此这里不需要密码;再启动 Hadoop(如果已经启动 Hadoop请跳过此步骤),
命令如下:
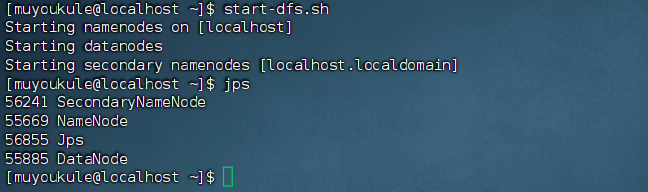
1 | # 登陆 ssh |
输入命令 jps,能看到 NameNode,DataNode 和 SecondaryNameNode 都已经成功启动,表示 hadoop 启动成功:
第二步:再启动 HBase 命令如下:
1 | # 启动 HBase |
启动成功,输入 jps 后就可以看见有 HQuorumPeer、HRegionServer、HMaster,说明都已经成功启动。
- HQuorumPeer:ZooKeeper 中的同步和选主线程,确保集群节点同步并处理领导选举。
- HRegionServer:HBase 中负责处理用户 I/O 请求、管理HRegion和存储数据的节点。
- HMaster:HBase 集群的主服务器,监控 RegionServer、管理元数据更改和负责表的增删改查操作。

第三步:进入 shell 界面:
1 | hbase shell |

输入 exit或者 Ctrl + d 就可以退出该模式,返回终端控制台。
1 | exit # 或者 Ctrl + d |
3、停止 HBase 运行,在终端输入下面命令:
1 | # 停止 HBase 运行 |
PS:如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase-2.2.2)下的logs子目录中的日志文件查看错误原因。
4.4 编程实践
4.4.1 利用Shell命令
先启动 Hadoop 再启动 HBase ,再输入 jps 进行查看。
1 | # 启动 Hadoop 分布式文件系统(HDFS)的守护进程 |
出现以下信息说明启动成功:
1 | HMaster |
然后进入 shell 界面
1 | hbase shell |
HBase中创建表
HBase 中用 create 命令创建表,具体如下:
1 | create 'student','Sname','Ssex','Sage','Sdept','course' |

此时,即创建了一个 student 表,属性有:Sname,Ssex,Sage,Sdept,course。因为 HBase 的表中会有一个系统默认的属性作为行键,无需自行创建,默认为 put 命令操作中表名后第一个数据。创建完 student 表后,可通过 describe 命令查看 student 表的基本信息。
1 | 查看 “student” 表的基本信息 |
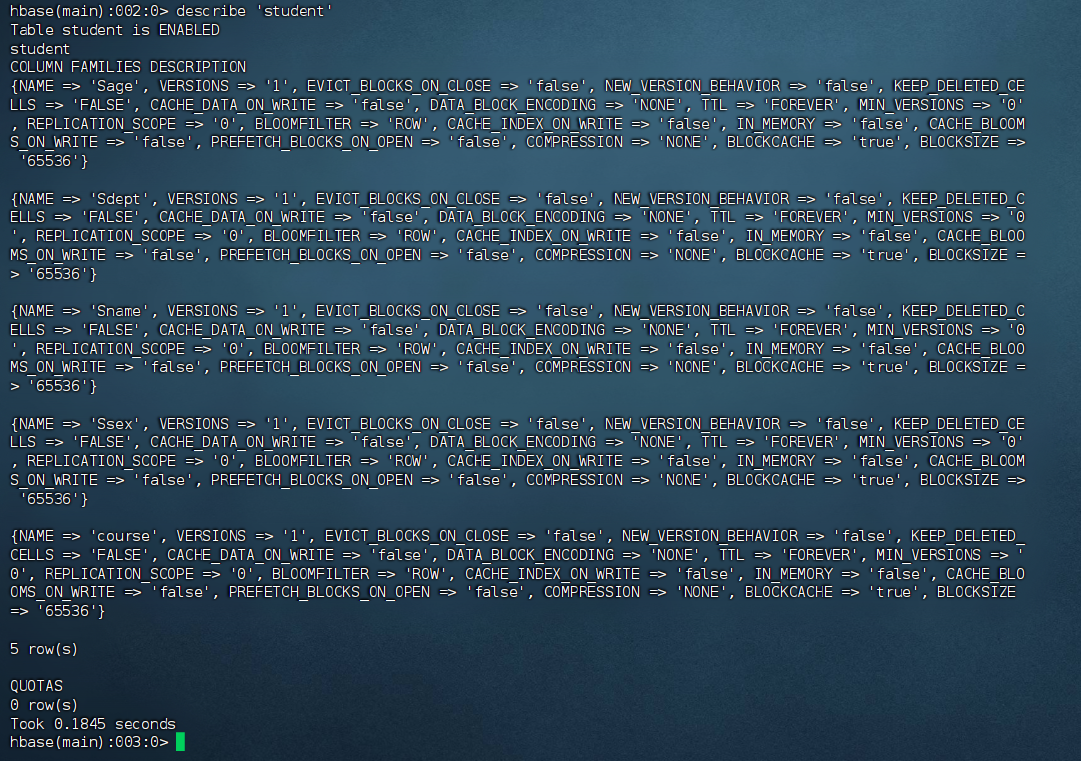
HBase数据库基本操作
本小节主要介绍 HBase 的增、删、改、查操作。在添加数据时,HBase 会自动为添加的数据添加一个时间戳,故在需要修改数据时,只需直接添加数据,HBase 即会生成一个新的版本,从而完成 “改” 操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的几个版本,保存的版本数可以在创建表的时候指定。
添加数据
HBase 中用 put 命令添加数据。
PS:一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用 shell 命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
向 student 表中添加数据:
1 | 为 student 表添加了学号为 95001,名字为 LiYing 的一行数据,其行键为 95001 |
每条命令执行后如添加成功,均返回以下内容:
1 | Took 0.0548 seconds |
添加后执行使用如下命令可以看到刚才添加的 3 条数据:
1 | 检索 student 表中键为 95001 的行的所有数据 |

查看数据
HBase 中有两个用于查看数据的命令:
get命令,用于查看表的某一行数据。scan命令用于查看某个表的全部数据。
get 命令
1 | # 检索 student 表中键为 95001 的行的所有数据 |
scan 命令
1 | 检索 student 表中所有数据 |
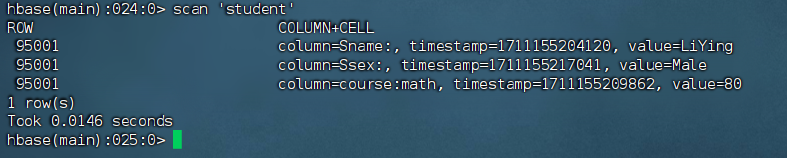
删除数据
在 HBase中 用 delete 以及 deleteall 命令进行删除数据操作,它们的区别是:
delete用于删除一个数据,是put的反向操作;deleteall操作用于删除一行数据。
delete 命令
1 | 删除 student 表中行键为 95001 的行的 Ssex 列的数据。 |
1 | Took 0.0091 seconds |
1 | 检索 student 表中键为 95001 的行的所有数据 |
可以看到 Ssex 列的不见了,删除了 student 表中 95001 行下的 Ssex 列的所有数据。
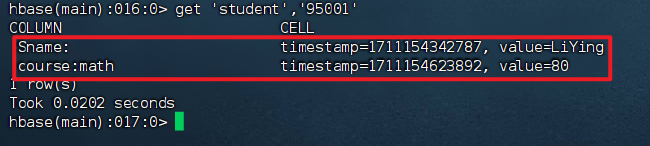
deleteall 命令
1 | 删除 student 表中的 95001 行的全部数据。 |
1 | Took 0.0052 seconds |
1 | 检索 student 表中键为 95001 的行的所有数据 |
可以看到所有列不见了,即删除了 student 表中的 95001 行的全部数据。
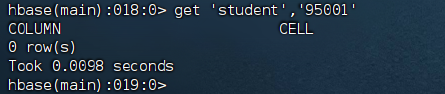
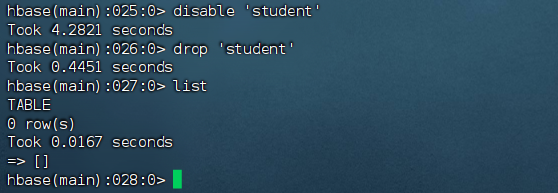
删除表
删除表有两步:
- 先让该表不可用。
- 删除表。
1 | 让该表不可用 |
查询表历史数据
查询表的历史版本,需要两步:
- 创建表并插入/更新数据。
- 查询指定版本的数据。
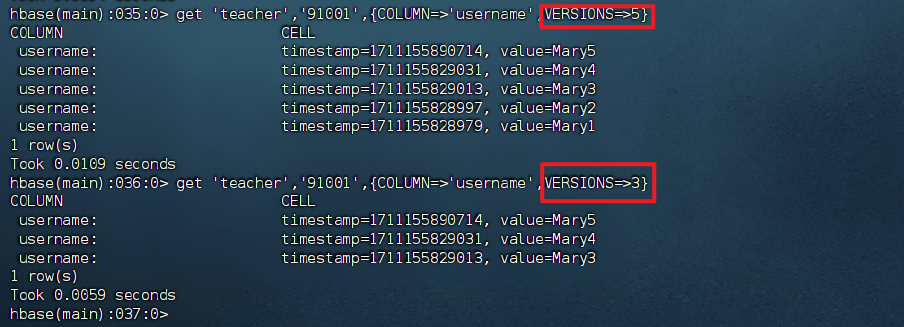
1、创建表指定保存的版本数(假设指定为5)
1 | create 'teacher',{NAME=>'username',VERSIONS=>5} |
1 | Created table teacher |
2、插入数据然后更新数据,使其产生历史版本数据。PS:这里插入数据和更新数据都是用 put 命令
1 | put 'teacher','91001','username','Mary' |
3、查询时,指定查询的历史版本数。默认会查询出最新的数据。(有效取值为1到5)
1 | get 'teacher','91001',{COLUMN=>'username',VERSIONS=>5} |
退出HBase数据库表操作
最后退出数据库操作,输入 exit 命令即可退出。
PS:这里退出 HBase 数据库是退出对数据库表的操作,而不是停止启动 HBase 数据库后台运行。
1 | exit # 或者 Ctrl + d |
4.4.2 Java API 编程实践
本实例采用 IDEA 开发工具。版本:2023.3.6
关于在 Linux 安装使用 IDEA 可以参考下文 Linux 安装使用 IDEA。
关于在 IDEA 中使用 Maven 可以参考下文 IDEA 中使用 Maven。
PS:在开始运行程序之前,需要启动 HDFS 和 HBase 。这很重要!!千万不要忘记了。😓
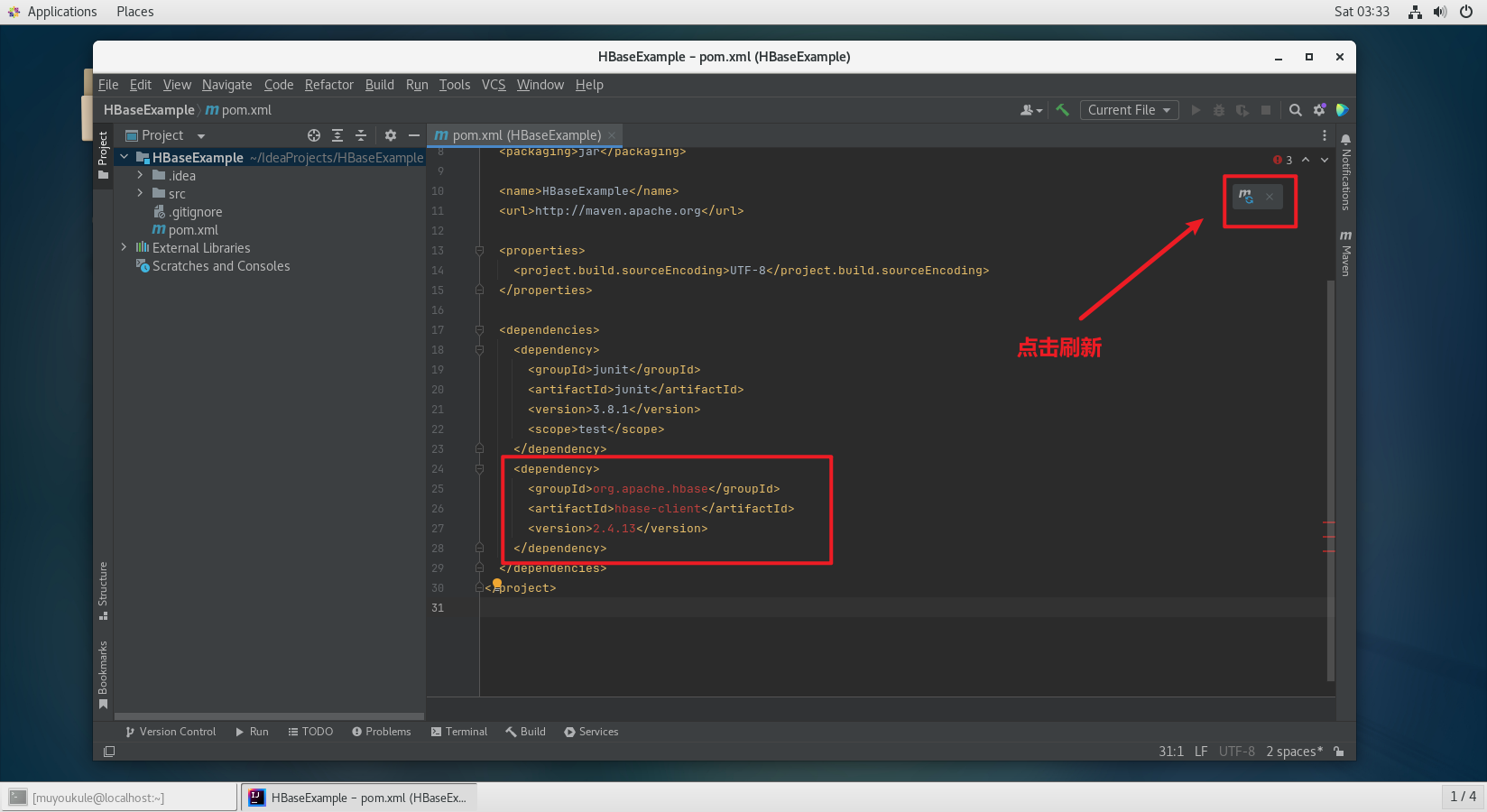
1、创建一个 Maven 项目,项目名为 HBaseExample
修改 pom.xml 文件,导入 HBase 的 Java API 的依赖包。PS:记得刷新依赖。😄
1 | <dependency> |
2、操作之前请确保没有 student 表:
1 | #打开 shell 命令行模式 |
3、编写 ExampleForHBase.java
PS:注意修改一下 configuration.set("hbase.rootdir", "hdfs://localhost:9000/hbase-2.2.2") 与 Hbase 配置文件的内容一致。😀
1 | package com.muyoukule; |
最终编写好的项目结构和代码如下:
.png)
.png)
项目空白处右键 Run 开始运行程序,程序运行成功以后,会在运行结果中出现 69:
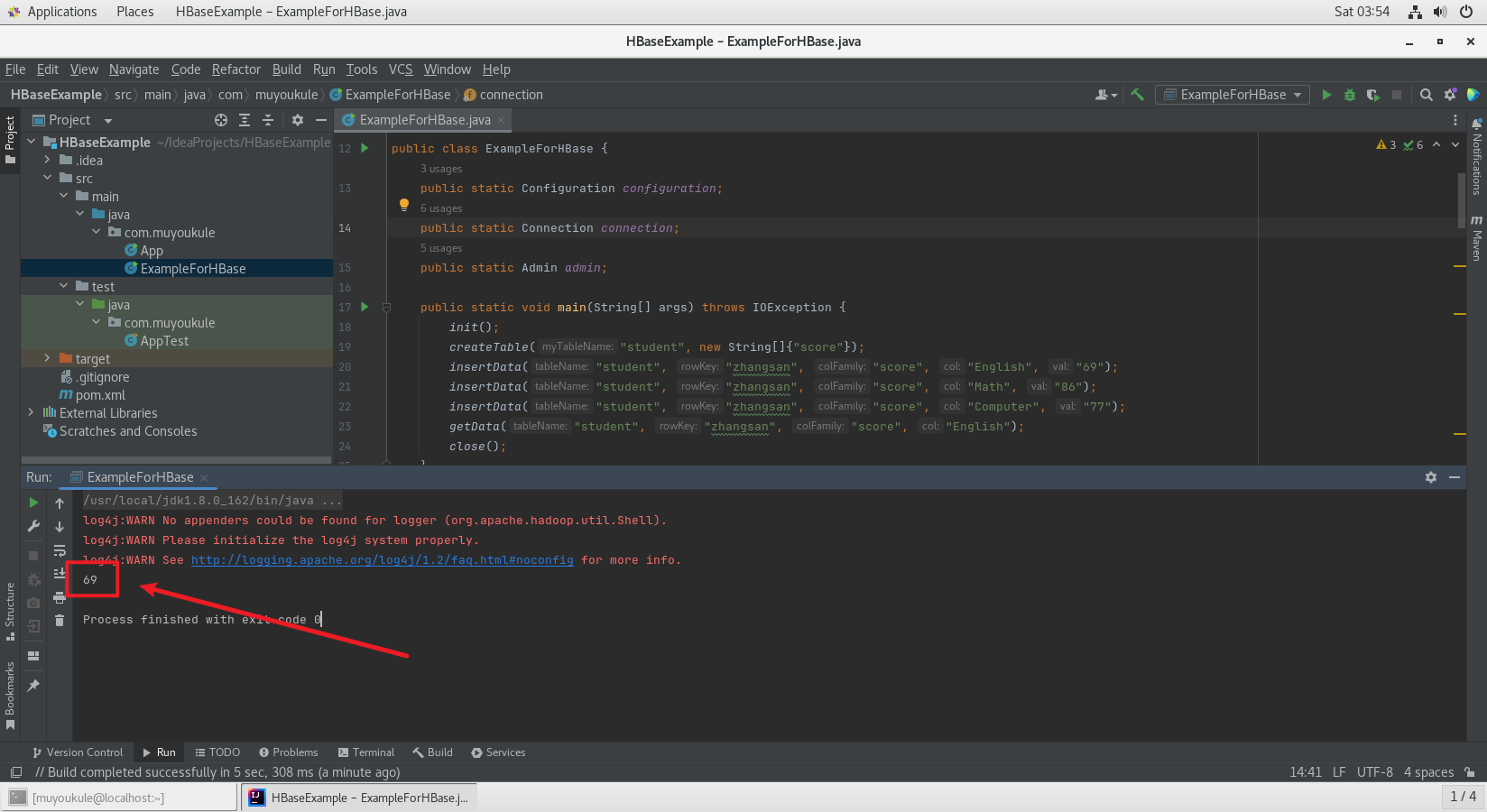
打印出来的 69 上面是日志的警告信息,可以忽略。
这时,可以到 HBase Shell 交互式环境中,使用如下命令查看 student 表是否创建成功:
1 | 列出所有的表 |
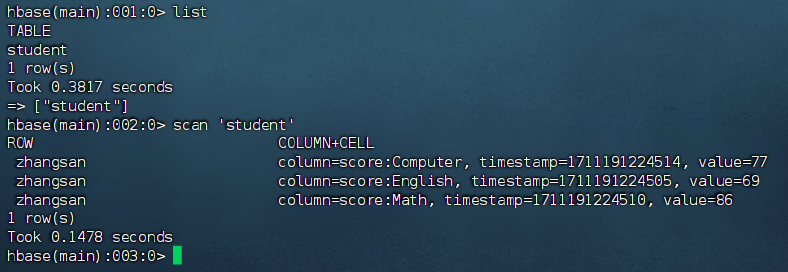
至此使用 Java 代码操作 HBase 成功!!!!
5. Hive
官方介绍:Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale. Hive Metastore(HMS) provides a central repository of metadata that can easily be analyzed to make informed, data driven decisions, and therefore it is a critical component of many data lake architectures. Hive is built on top of Apache Hadoop and supports storage on S3, adls, gs etc though hdfs. Hive allows users to read, write, and manage petabytes of data using SQL.
5.1 Hive 下载与安装
.png)
.png)
打不开官网?试试清华大学开源软件镜像站下载😀
下载好之后就可以开始安装了:
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 Hive 安装文件到 /usr/local 目录,并对解压缩之后的文件进行重命名,授权
1 | # 解压缩 Hive 安装文件到 /usr/local 目录 |
3、配置环境变量,使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
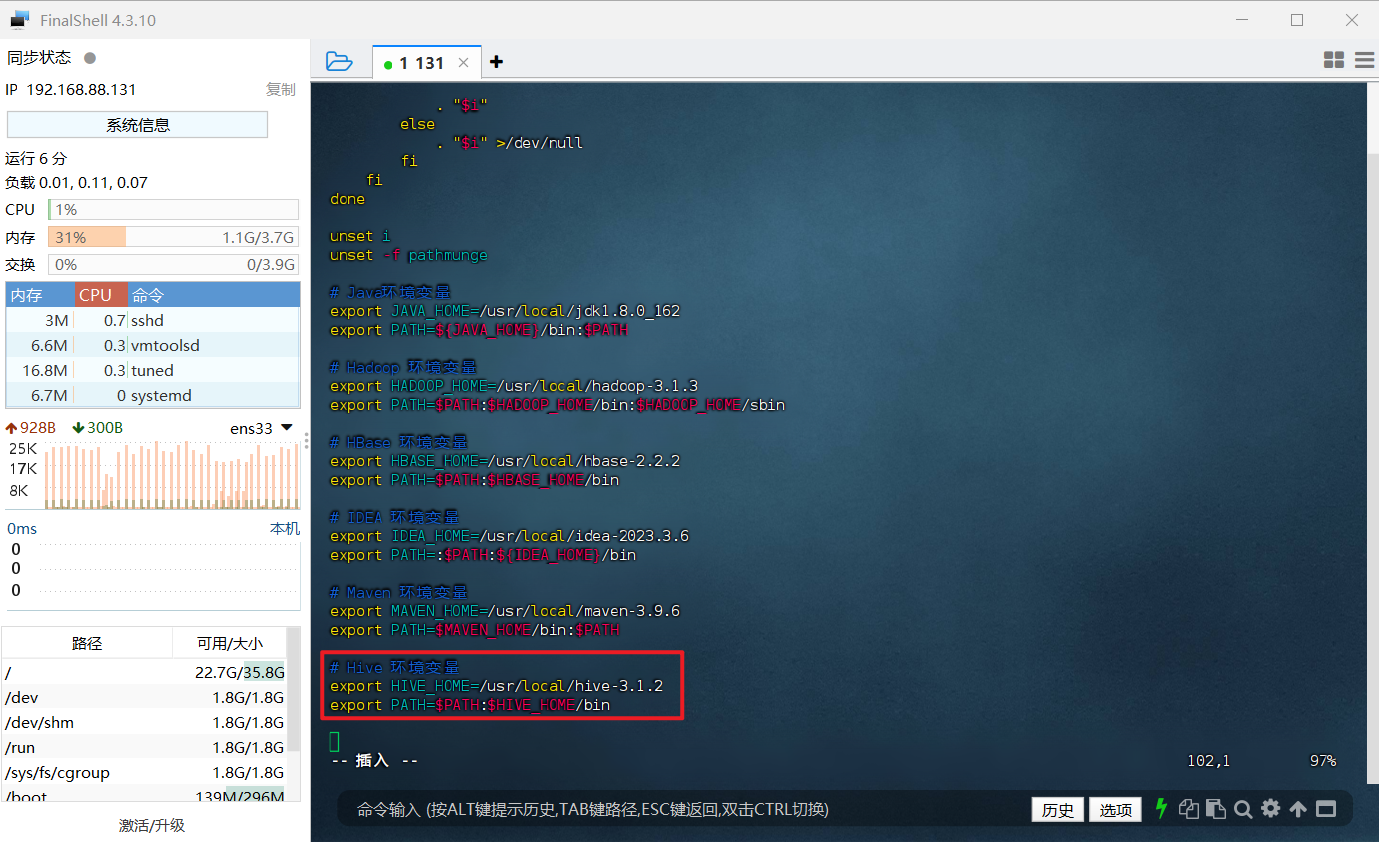
4、重启环境变量配置
1 | source /etc/profile |
5、修改/usr/local/hive-3.1.2/conf下的 hive-site.xml(注意自己的路径)
1 | cd /usr/local/hive-3.1.2/conf |
6、使用 gedit 编辑器新建一个配置文件 hive-site.xml
1 | # 直接操作虚拟机使用 gedit 修改配置文件 |
7、在 hive-site.xml 中添加如下配置信息:
1 |
|
添加后保存并退出即可。
5.2 配置 MySQL
这里我们采用 MySQL 数据库保存 Hive 的元数据,而不是采用 Hive 自带的 derby 来存储元数据。
下载 mysql jdbc 包
打开默认是最新版,也可以点击 Archives 选择历史版本。
选择历史版本后点击 Download 进行下载:
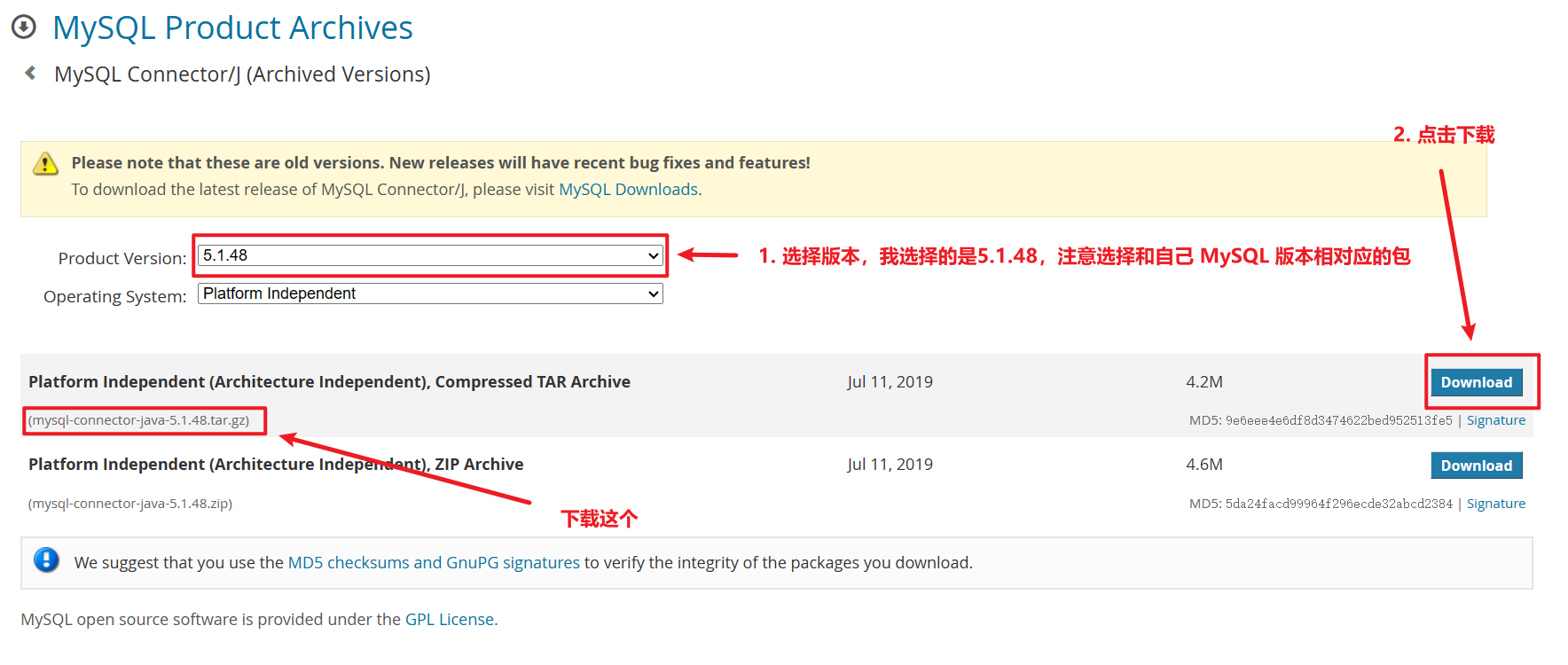
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩文件到 /usr/local 目录,并对将 mysql-connector-java-5.1.40-bin.jar 拷贝到 hive 的 lib 目录下
1 | # 解压缩文件到 /usr/local 目录 |
3、启动并登陆 mysql shell
1 | # 启动mysql服务 |
4、新建 Hive 数据库
1 | # 这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据 |
5、配置 MySQL 允许 Hive 接入
1 | # 将所有数据库的所有表的所有权限赋给hive用户,后面的 root 是配置hive-site.xml中配置的连接密码 |
6、启动 Hive(启动 Hive 之前,请先启动 Hadoop )
1 | #启动Hadoop |
假如在启动时报错:
1 | org.datanucleus.store.rdbms.exceptions.MissingTableException: Required table missing : "`VERSION`" in Catalog "" Schema "". DataNucleus requires this table to perform its persistence operations. Either your MetaData is incorrect, or you need to enable "datanucleus.schema.autoCreateTables" |

解决方法:
先退出 Hive,再执行命令:
1 | # 退出 Hive |
看到如下内容即代表初始化完毕:

初始化后再次使用 hive 启动 Hive,可以看到成功启动:
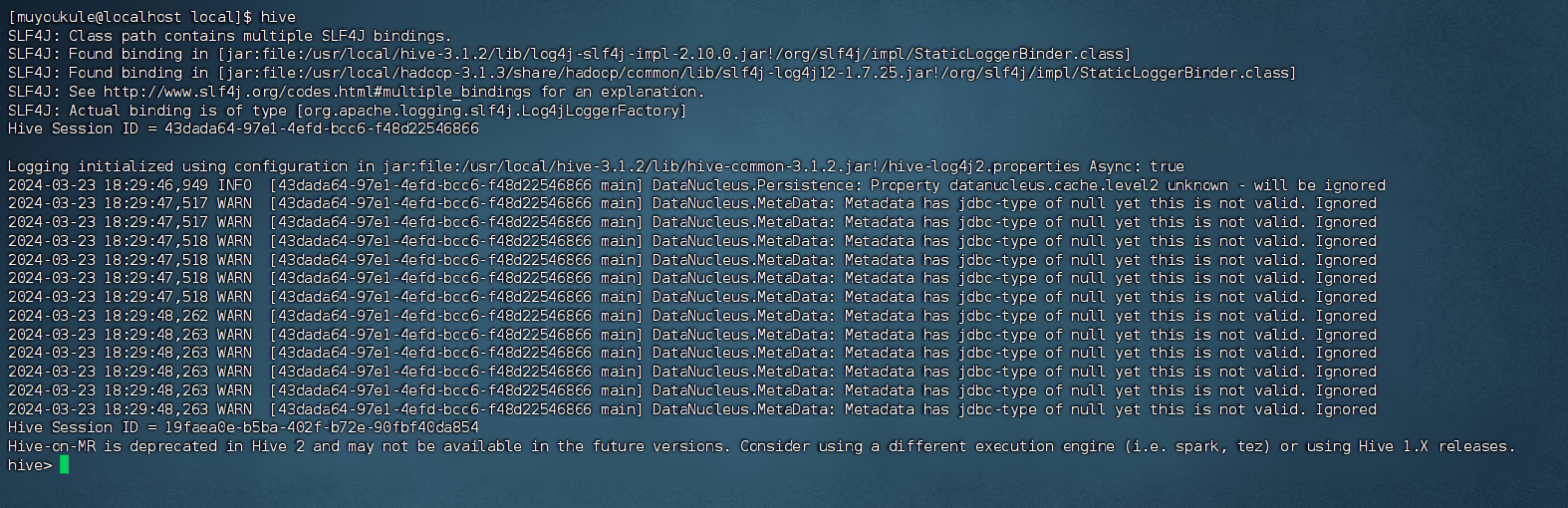
启动进入 Hive 的交互式执行环境以后,会出现如下命令提示符:
1 | hive> |
可以在里面输入 SQL 语句,如果要退出 Hive 交互式执行环境,可以输入如下命令:
1 | exit; # 或者 Ctrl + d |
6. Sqoop
Sqoop 是一款开源工具,专注于在 Hadoop(Hive)与传统数据库(如 MySQL、PostgreSQL 等)之间高效传输大批量数据。它可以将关系型数据库中的数据导入到 Hadoop 的 HDFS、Hive、HBase 等数据存储系统中,也可以从 Hadoop 的文件系统中导出数据到关系型数据库中。Sqoop 的核心设计思想是利用MapReduce加快数据传输速度,实现批处理方式进行数据传输。
6.1 Sqoop下载与安装
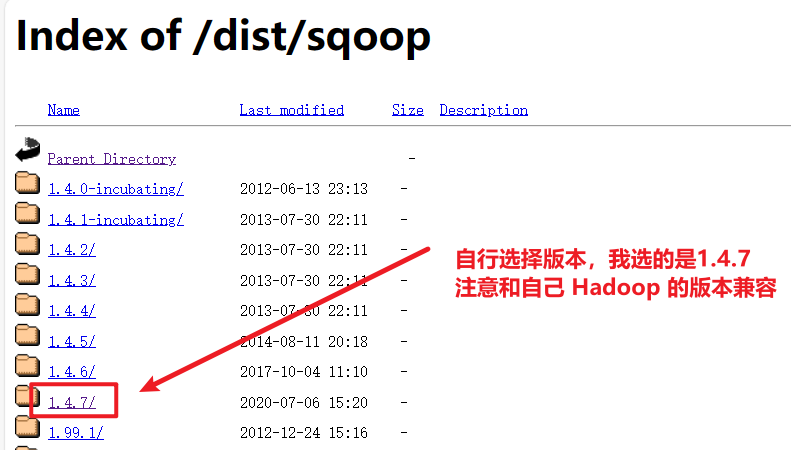
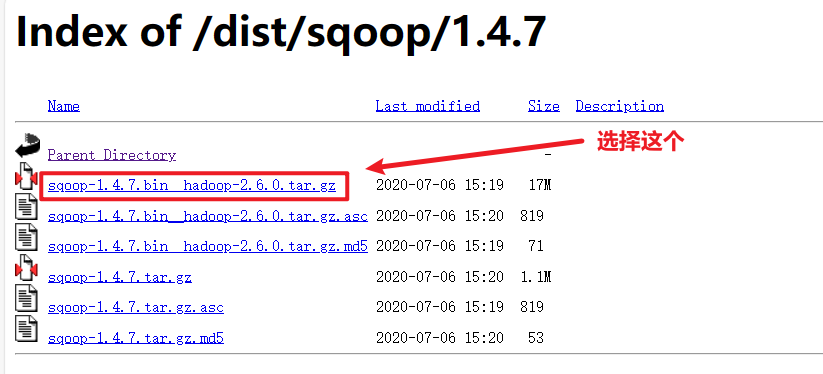
下载好之后就可以开始安装了:
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 Sqoop 安装文件到 /usr/local 目录,并对解压缩之后的文件进行重命名,授权
1 | # 解压缩 Sqoop 安装文件到 /usr/local 目录 |
3、修改配置文件 sqoop-env.sh
进入到 conf 文件夹,找到 sqoop-env-template.sh,修改其名称为 sqoop-env.sh 。然后编辑 sqoop-env.sh 文件,设置HADOOP_COMMON_HOME,HADOOP_MAPRED_HOME,HIVE_HOME 等环境变量。
1 | # 将 sqoop-env-template.sh 复制一份并命名为 sqoop-env.sh |
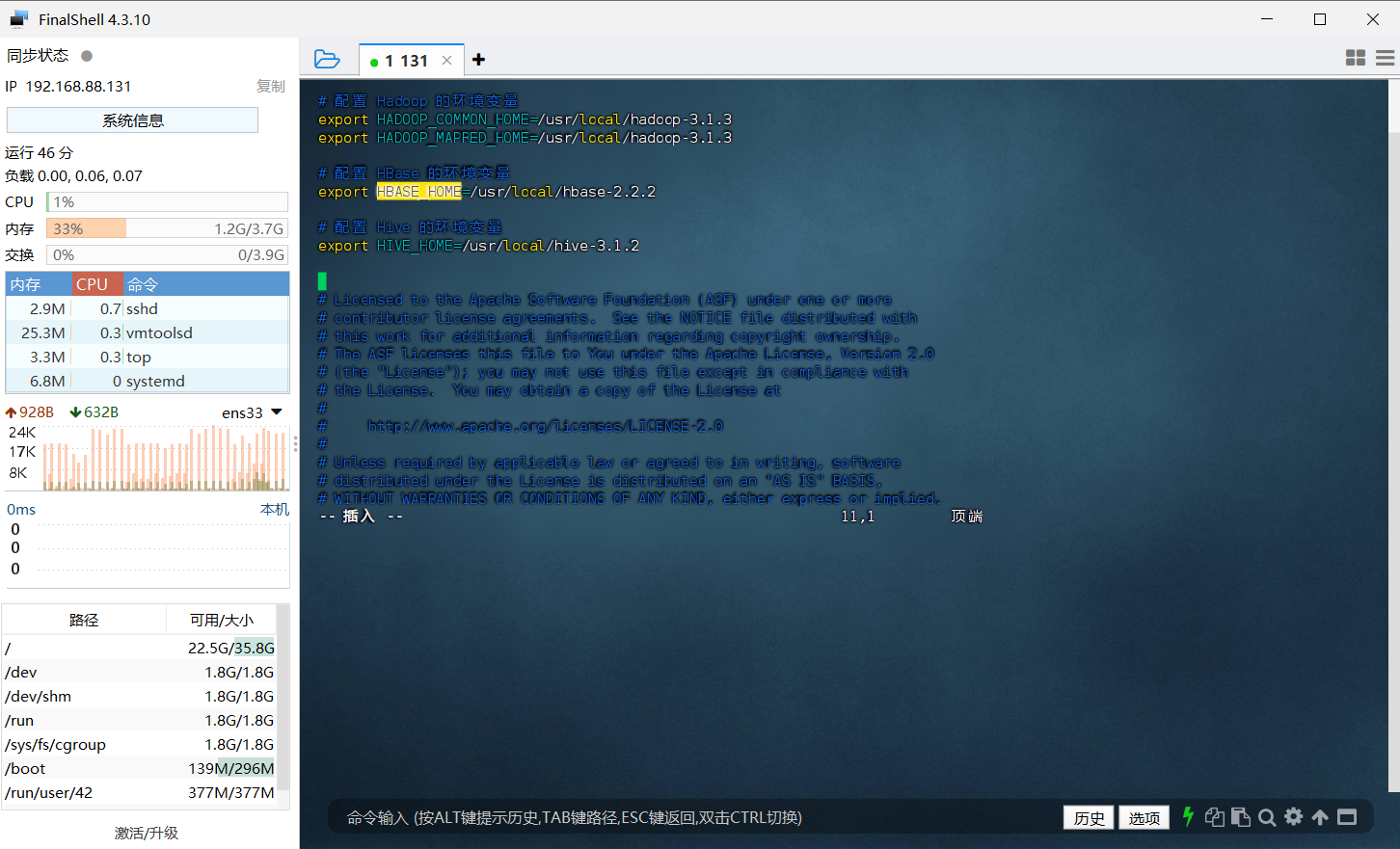
修改 sqoop-env.sh 的如下信息
1 | # 配置 Hadoop 的环境变量 |
因为在 sqoop-env.sh 文件中已经存在有如上这几个变量,只是被注释掉了,也就是前面带了 # 号,所以大家可以直接寻找到对应的变量,将前面起注释作用的 # 号删去,然后修改后面的值即可。
PS:vim 编辑器怎样搜索字符串?
- 普通模式下,按下
/键,然后输入你想要搜索的字符串,按下Enter键开始搜索。 - 要查找下一个匹配的字符串,按
n。 - 要查找上一个匹配的字符串,按
N。
但是我很懒不想去找🙄,所以我就直接写在文件顶部了,这个是不影响运行操作的,具体图示如下:
4、配置环境变量,使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
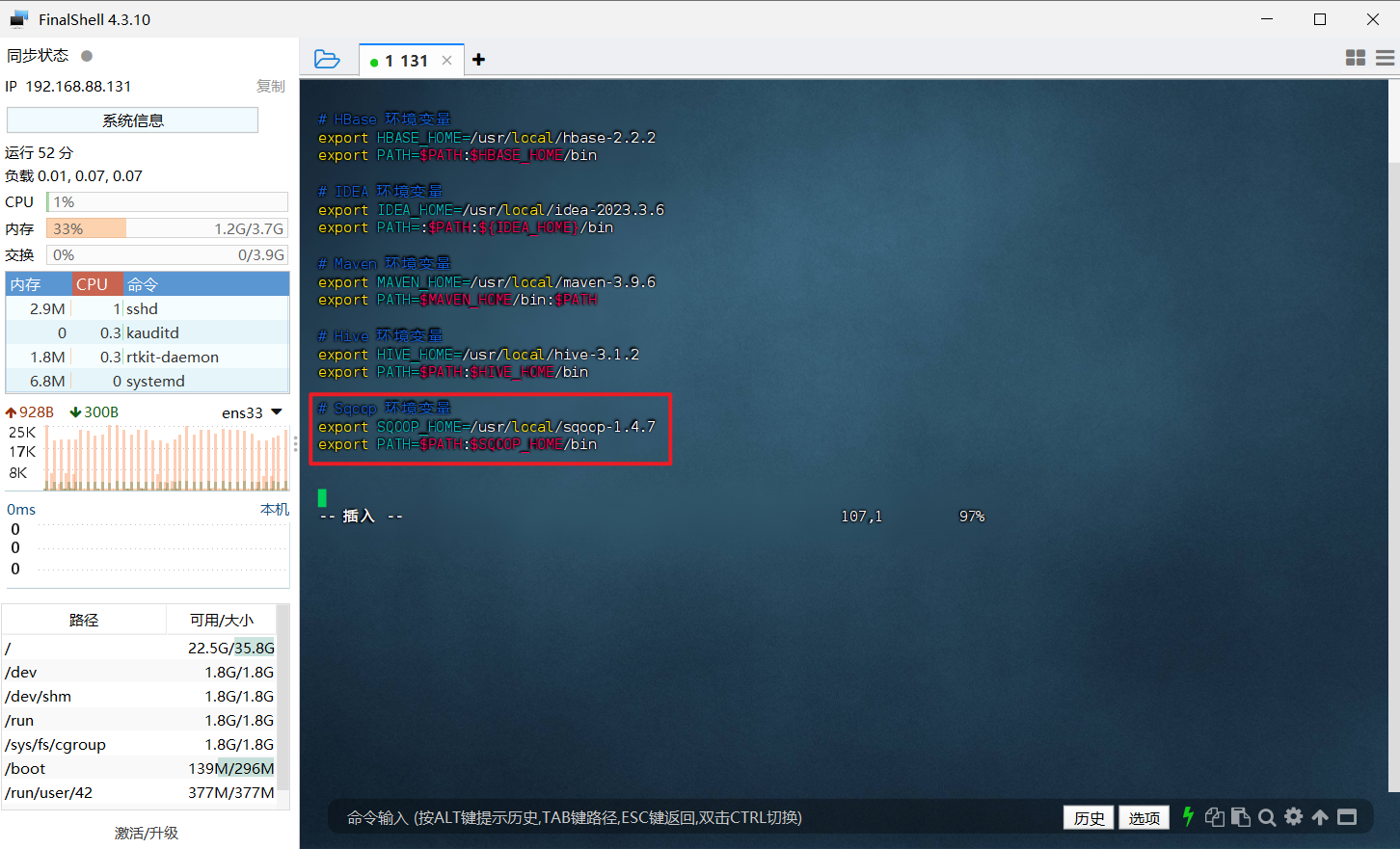
5、重启环境变量配置
1 | source /etc/profile |
6、检查安装结果,出现下面信息代表安装成功
1 | # 查看 Sqoop 版本信息 |
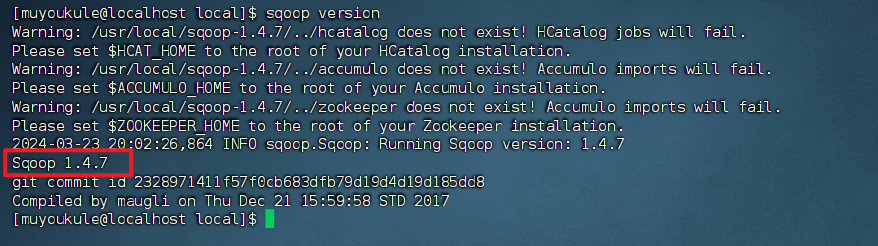
上面的警告是因为一些组件(HCatalog、Accumulo和Zookeeper)导致的,我们后续不会用到这些组件所以不用管它。
这样,Sqoop 就安装好了。
6.2 配置 MySQL
1、添加 MySQL 驱动
将 MySQL 的 JDBC 驱动包(例如 mysql-connector-java-5.1.40-bin.jar )添加到 Sqoop 的 lib 目录下。PS:你的 MySQL 驱动要和你的数据库版本兼容。
1 | # 进入到 /usr/local 目录 |
2、测试与 MySQL 的连接
首先请确保 MySQL 服务已经启动了,如果没有启动,请执行下面命令启动:
1 | #检查 MySQL 服务状态 |
3、然后就可以测试 Sqoop 与 MySQL 之间的连接是否成功:
1 | sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P |
如果出现错误:
1 | WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. |
首先检查在配置 jdbc 连接的 URL是是否加了 useSSL=false 参数。如果没加,将它加上后再次测试;如果加了也报这个错误则依次:
1 | 登入数据库 |
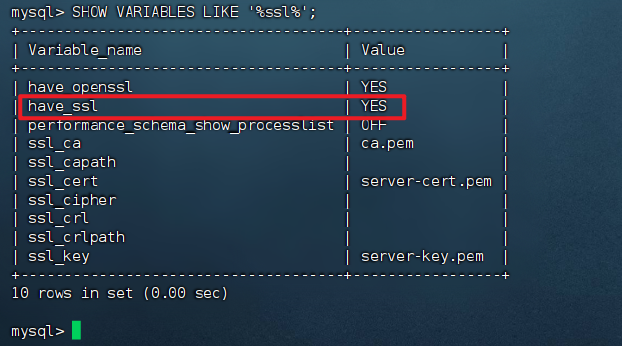
看到 have_ssl 的值为 YES,表示已开启 SSL。( have_openssl 表示是否支持SSL)。需要将 SSL 关闭:
1 | # 修改 MySQL 配置文件,目录根据安装时自行查找 |
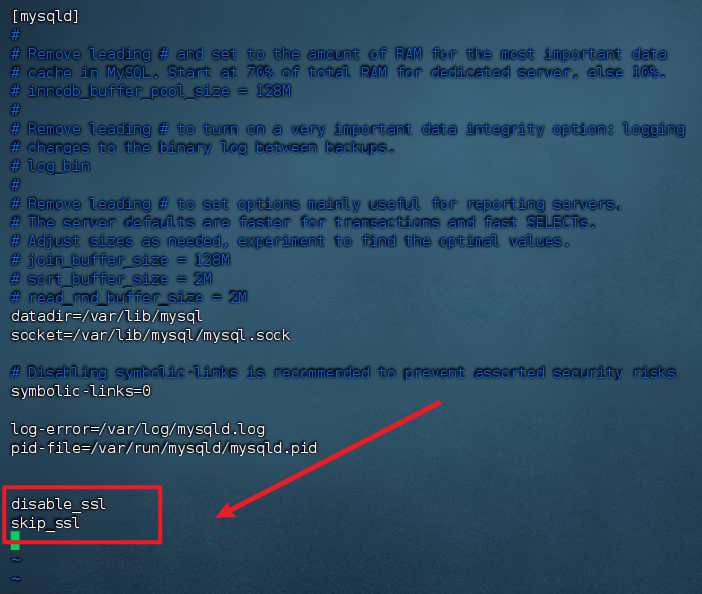
重启后再次测试 ,MySQL 的数据库列表显示在屏幕上表示连接成功:
1 | sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P |
Linux 安装使用 IDEA
我这里使用的是 IDEA 2023.3.6 版本和 CentOS7 系统 其他版本和系统仅作参考。
PS:Linux 中安装使用 IDEA 必须直接操作虚拟机,不能在远程连接工具操作,否则会打不开 IDEA。😅
我这里下载的是免费社区版,社区版功能少虽然少,但是在这里够用。但是如果你有特定需求,需要更多的高级功能和定制选项,建议选择收费企业版😐,当然破解码网上都可以找到,安装步骤是一样的,大家有需求可以自行去网上查找相关教程。
IDEA 的下载
我这里是在本机上下载安装包然后上传到虚拟机,当然你也可以直接在 Linux 中打开 Firefox 浏览器进行下载。
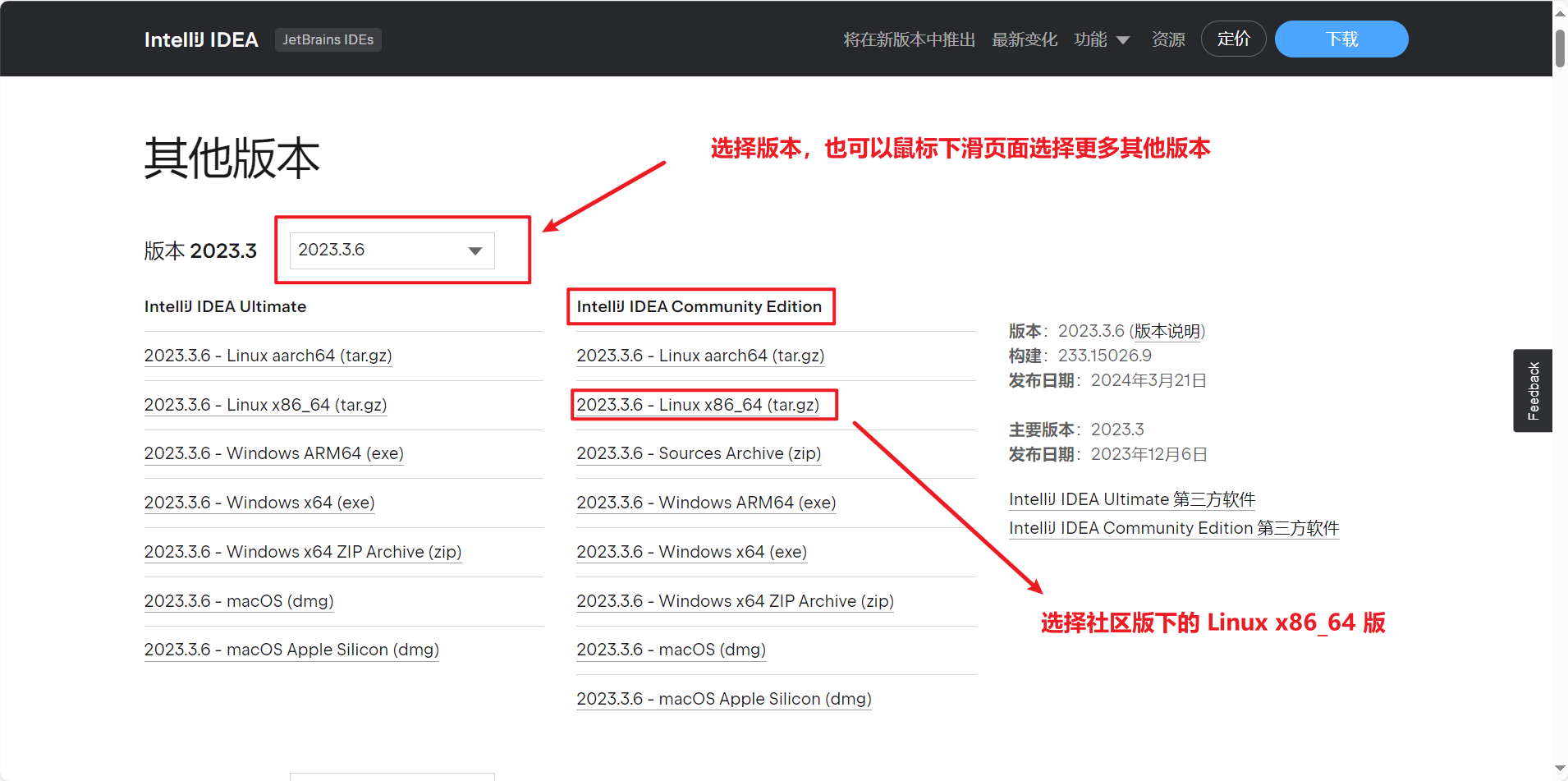
IDEA 的安装
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 IDEA 安装文件到 /usr/local 目录,并对解压缩之后的文件进行重命名
1 | # 解压缩 IDEA 安装文件到 /usr/local 目录 |
可以看到 bin 目录下有个 idea.sh 文件:
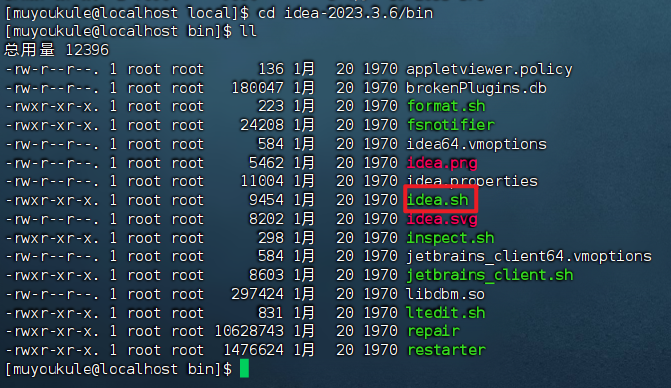
3、运行 idea.sh 文件进行安装:
1 | ./idea.sh |
假如你觉得每次通过 ./idea.sh 指令启动 IDEA 要进入到 IDEA 的环境目录很麻烦,你也可以为 IDEA 配置环境变量(不觉得麻烦的可以跳过此步骤😄):
1、使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
2、重启环境变量配置
1 | source /etc/profile |
3、之后我们就可以在任意目录下输入 idea.sh 启动 IDEA 图形化界面了
1 | # 启动 IDEA 图形化界面 |
第一次启动 IDEA 图形化界面后会依次弹出以下界面,按照如下步骤操作即可:
1、打钩并点击 Continue
.png)
2、出现 “Date Sharing” 窗口,点击 Don't Send
.png)
3、前面步骤操作完后,会出现 IDEA 界面
.png)
至此 IDEA 安装完成!!是不是超级简单!!!😀
IDEA 的使用
1、点击 New Project 新建项目
.png)
2、修改项目名称,选择 JDK( IDEA 会识别到系统下安装过的 JDK 作为默认项),如果没有 JDK,需要点击 Download JDK 进行下载
.png)
2、IDEA 提示 Untrusted Server’s certificate ,证书不可用( Server’s certificate is not trusted ),不用管,点击 Accept
.png)
4、IDEA 默认会创建一个示例项目,等待右下角 JDK 加载完成后在项目空白处右键点击 Run
.png)
.png)
5、之后看见控制台成功输出结果,成功!!!
.png)
至此,IDEA 新建项目成功!就可以进行 Java 代码的编写了!!!
Maven
Maven是一个强大的项目管理工具,主要服务于Java项目。它通过对项目构建过程的标准化和自动化,实现了依赖管理的简化,从而极大地提升了开发效率,并确保了项目的高质量输出。Maven的核心功能包括项目构建、依赖管理和项目信息管理,为开发者提供了一个统一、高效的平台来管理复杂的Java项目。如果你想了解更多关于 Maven 的知识请上网查阅,这里只做简单介绍。
这里我们主要使用到了依赖管理功能:采用 pom.xml 来导入依赖,可以自动下载 jar,以及其所依赖 jar,无需手动下载,拷贝 jar 到项目中。简单理解就是找 jar 包太麻烦了,我懒得自己找,让 Maven 帮我找。😏
Maven 下载
直接点击下载最新版或者下载以前的版本
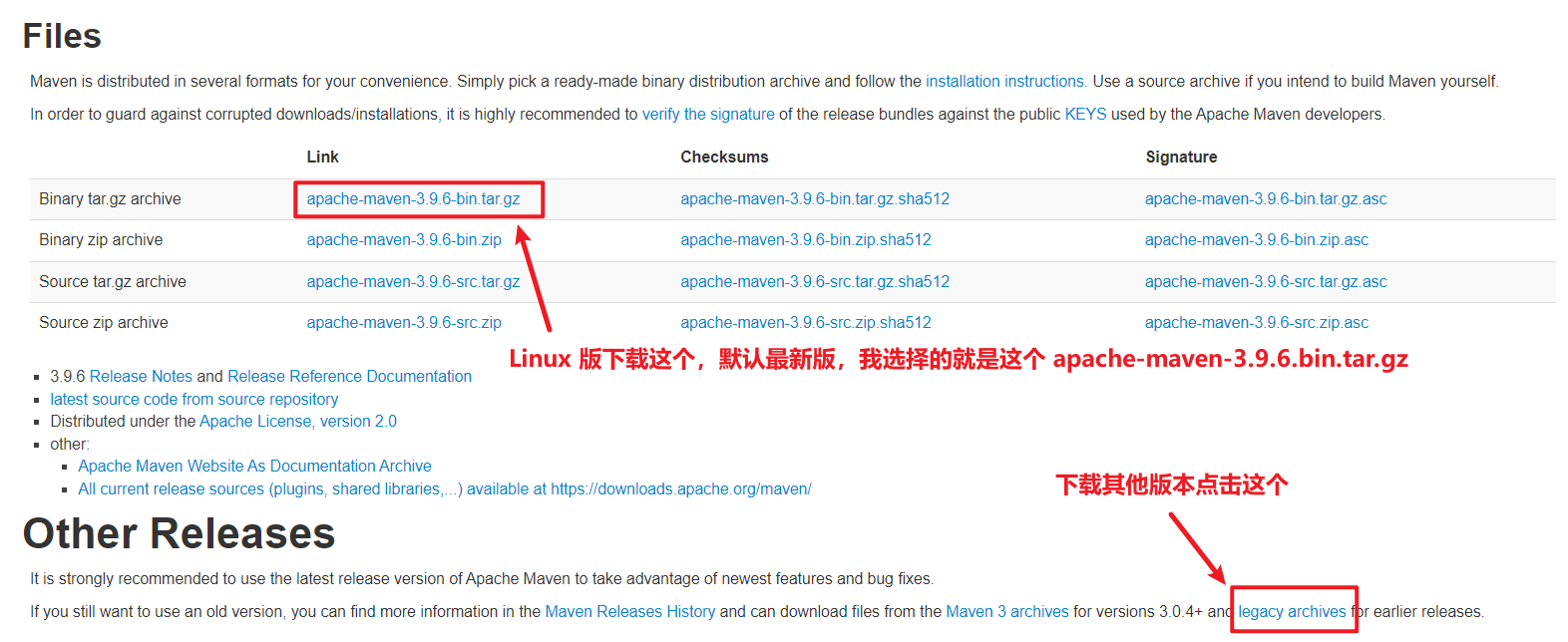
点击 legacy archives 进入页面自行选择相应版本即可。
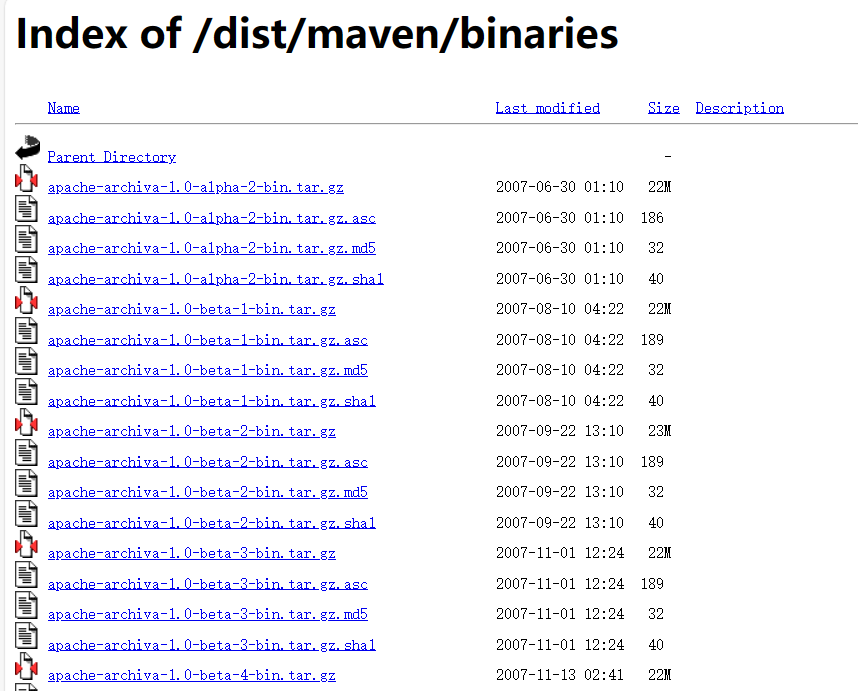
打不开官网?试试清华大学开源软件镜像站下载。
Maven 安装
1、执行以下命令,选择文件上传到 Linux 的 / 目录(具体请参考上文 FinalShell 文件上传)
1 | cd / |
2、解压缩 Maven 安装文件到 /usr/local 目录,并对解压缩之后的文件进行重命名
1 | # 解压缩 Maven 安装文件到 /usr/local 目录 |
3、配置环境变量,使用 vim 编辑器修改 /etc/profile 文件,在文件最后添加环境变量。
1 | # 修改 /etc/profile 文件 |
4、重启环境变量配置
1 | source /etc/profile |
5、检查安装结果,出现下面信息代表安装成功
1 | # 查看 Maven 版本信息 |

这样,Maven 就安装好了。
Maven 仓库配置
怎么理解 Maven 仓库?
Maven 仓库主要用于管理项目的依赖和插件。它是 Maven 的核心概念之一,对于 Maven 项目的构建和管理起着至关重要的作用。
具体来说,Maven 仓库可以分为本地仓库、中央仓库和远程仓库。本地仓库位于用户的本地机器上,用于存储项目所需的依赖(jar包)和插件。当 Maven 构建项目时,它首先会在本地仓库中查找所需的依赖和插件。如果本地仓库中没有,Maven 会尝试从中央仓库或远程仓库中下载。
中央仓库是 Maven 的官方仓库,其中包含了大量开源的 Java 库和插件。它位于 Maven 的服务器上,是 Maven 社区共享资源的地方。通过中央仓库,Maven用户可以方便地获取到各种开源项目的依赖和插件。
除了中央仓库外,还有一些其他的远程仓库,它们可能由第三方提供,用于存储特定的依赖和插件。这些远程仓库可以作为中央仓库的补充,使得Maven用户可以获取到更多的资源。
配置本地仓库
1、新建存放仓库的文件夹(本地仓库)
1 | # 在 /usr/local/ 下创建 名为 maven_repo 的本地仓库 |
2、打开 setting.xml 文件(注意自己存放的路径)
1 | # 直接操作虚拟机使用 gedit 修改 maven 配置文件 |
3、添加路径(注意自己存放的路径)
1 | <localRepository>/usr/local/maven_repo</localRepository> |
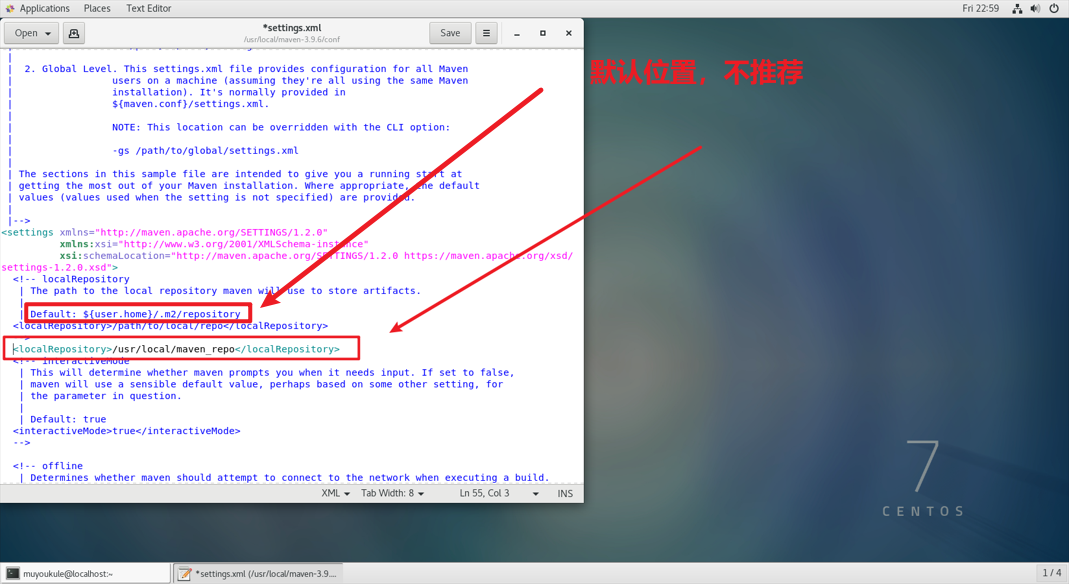
配置远程仓库
也可以不配置,但是下载依赖速度就会很慢。😂
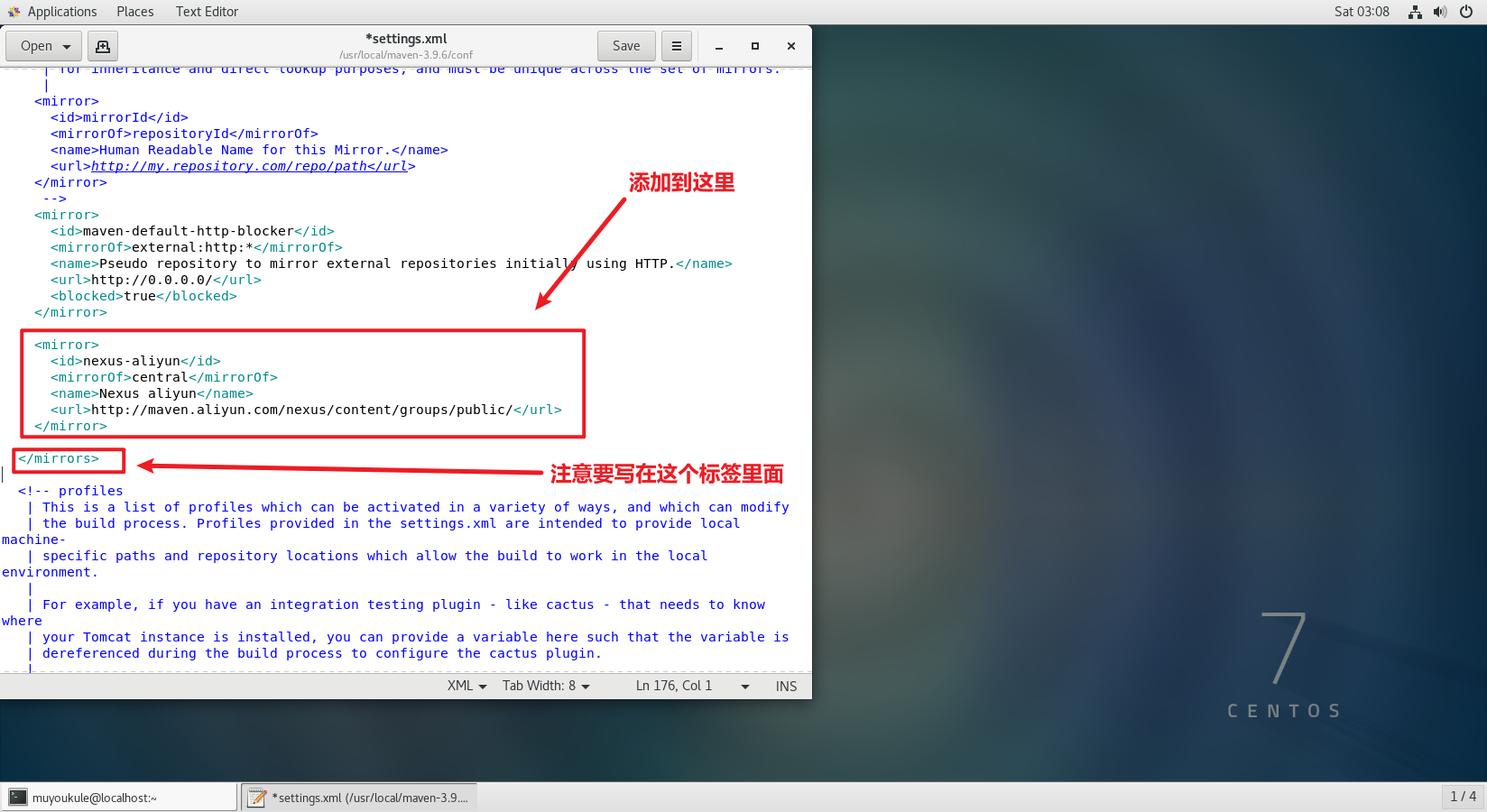
在 settings.xml 中添加阿里云的镜像资源。(注意添加的位置)
1 | <mirror> |
Maven 命令
以下是 Maven 的常用命令:
mvn clean:清理构建产生的文件。mvn compile:编译项目的源代码。mvn test:运行项目的单元测试。mvn package:打包项目,生成 JAR 或 WAR 文件。mvn install:将项目安装到本地 Maven 仓库。mvn deploy:将项目发布到远程仓库。mvn site:生成项目文档和报告。mvn archetype:generate或mvn archetype:create:基于原型创建新的 Maven 项目。mvn version或mvn -v:显示 Maven 版本信息和环境配置。
IDEA 中使用 Maven
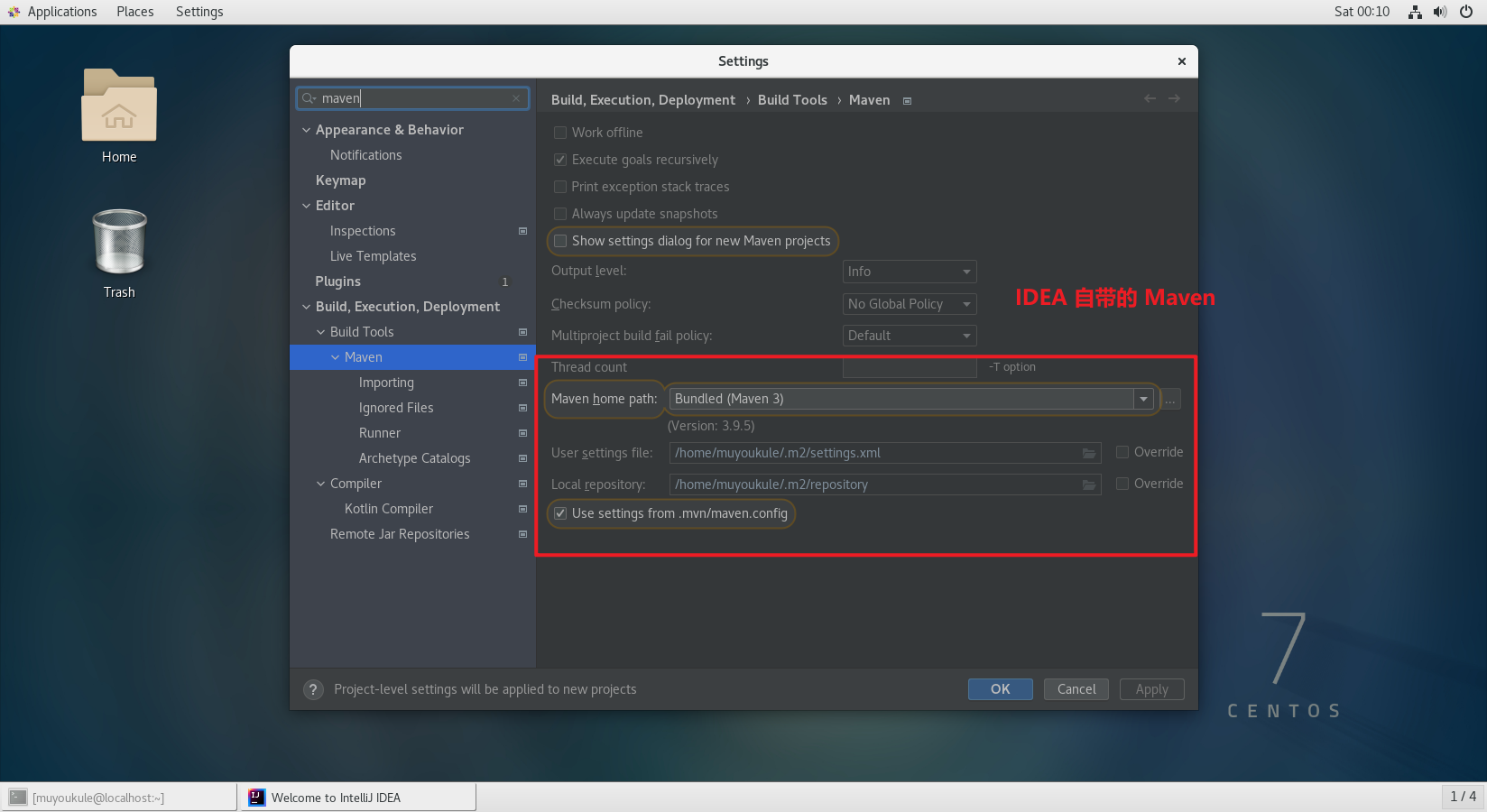
PS:IDEA 中自带 Maven,如果你没有下载Apache Maven,直接创建 Maven 项目也行。
IDEA 中自带的 Maven
配置自己下载的 Maven
PS:配置 Maven 之前一定要做的设置!!这很重要!这很重要!这很重要 * 3 !!!!否则 Maven 下载依赖会失败,会爆红!!!! 😣😣😣
1 | # 把 Maven 本地仓库目录权限赋予给 muyoukule 用户 |
如果你打开有项目先将它关闭,在 Customize 下点击 All settings
在左上角搜索 maven,找到如下界面进行配置
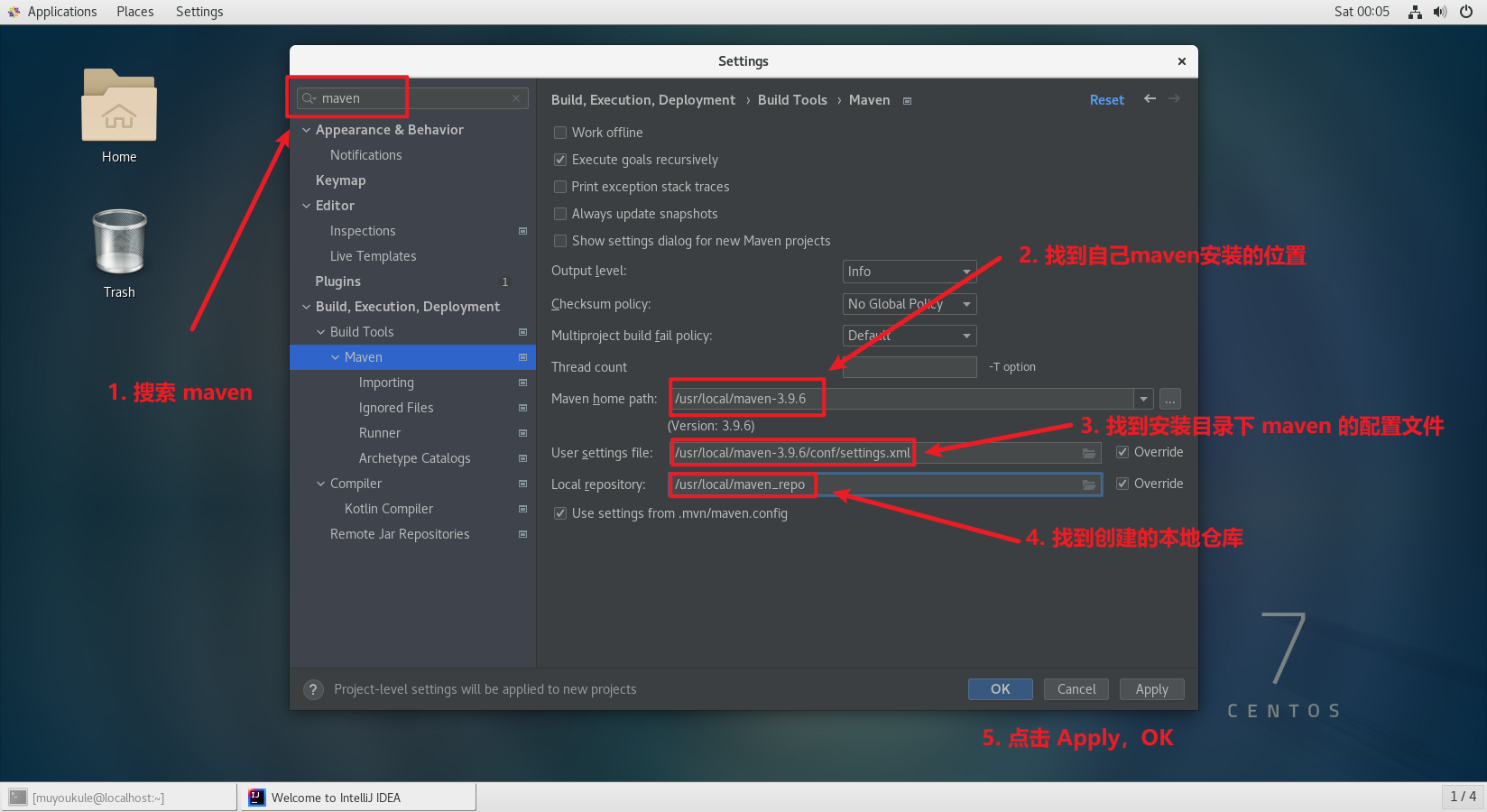
配置好了就可以创建 Maven 项目了。
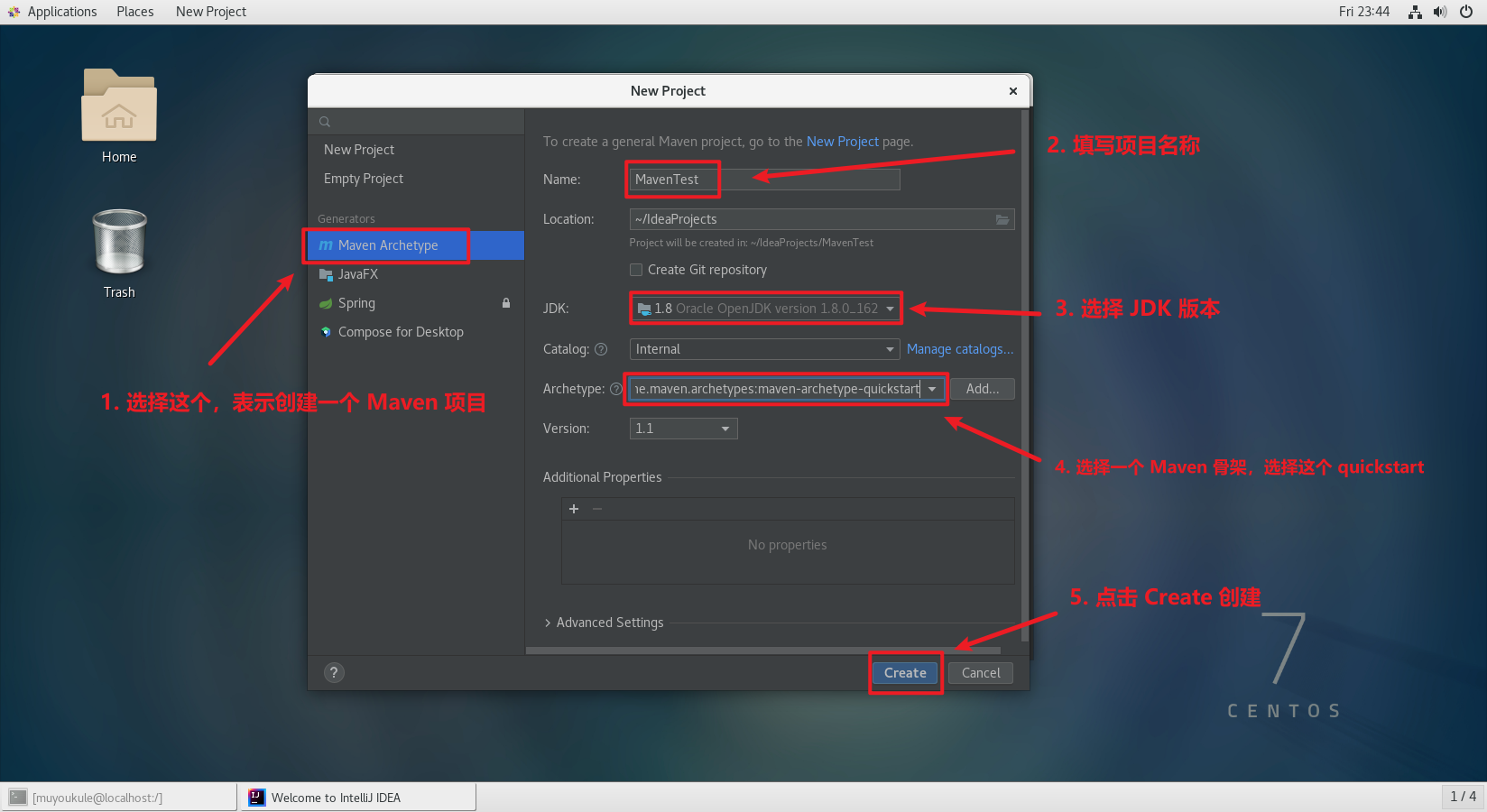
第一次创建 Maven 项目需要耐心等待,因为第一次创建 Maven 项目本地仓库为空,所有依赖都要去远程仓库下载。
PS:每次创建完项目后记得要再次检查一下 Maven 配置是否成功!!!!😫😫😫
IDEA 左上角点击 File –> Settings 进行检查。因为有些 IDEA 版本很垃圾有 BUG,在 Customize 点击 All settings 下配置 Maven 时失效。所以每次创建完项目一定要对 Maven 配置进行检查!!
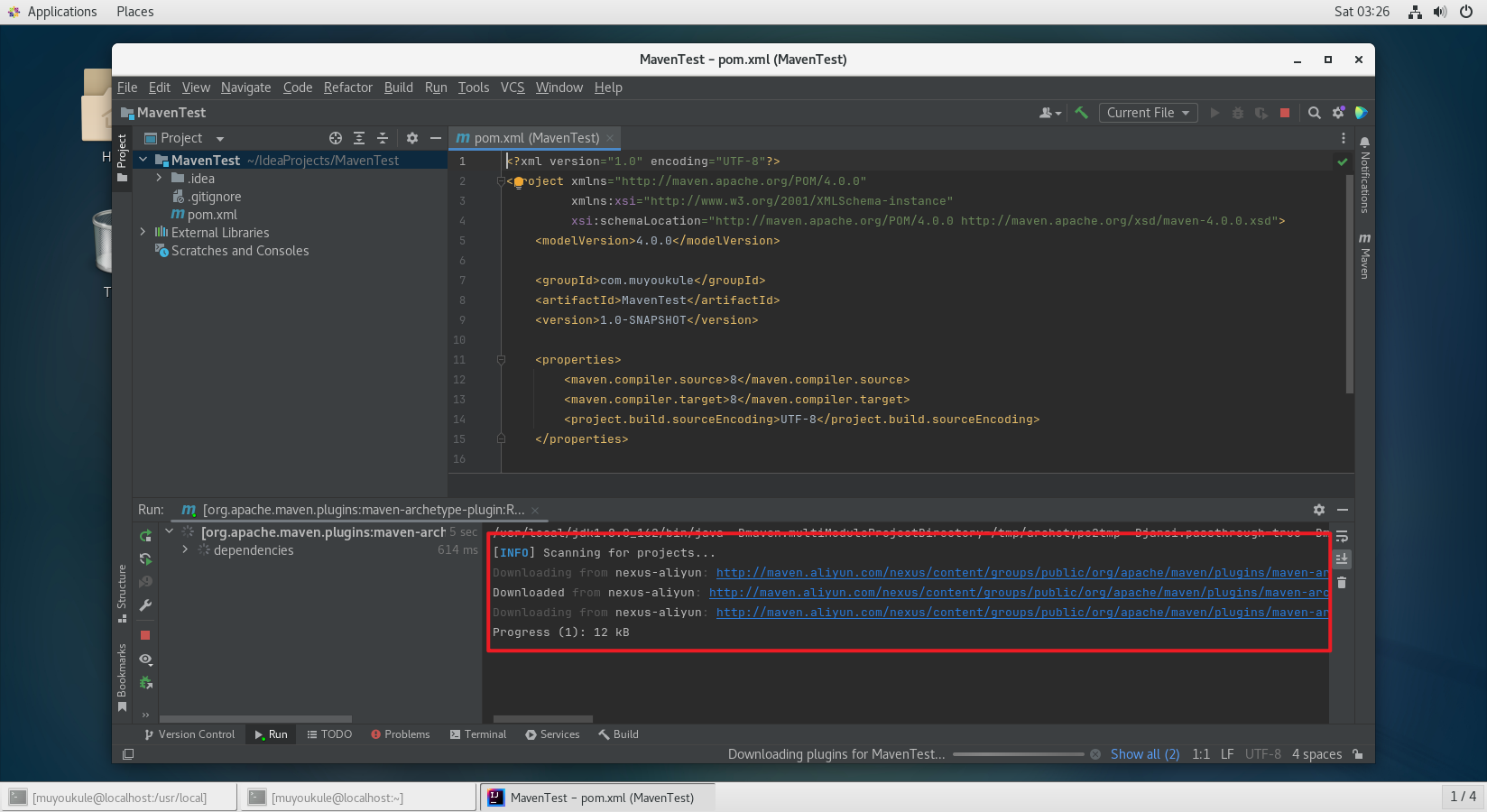
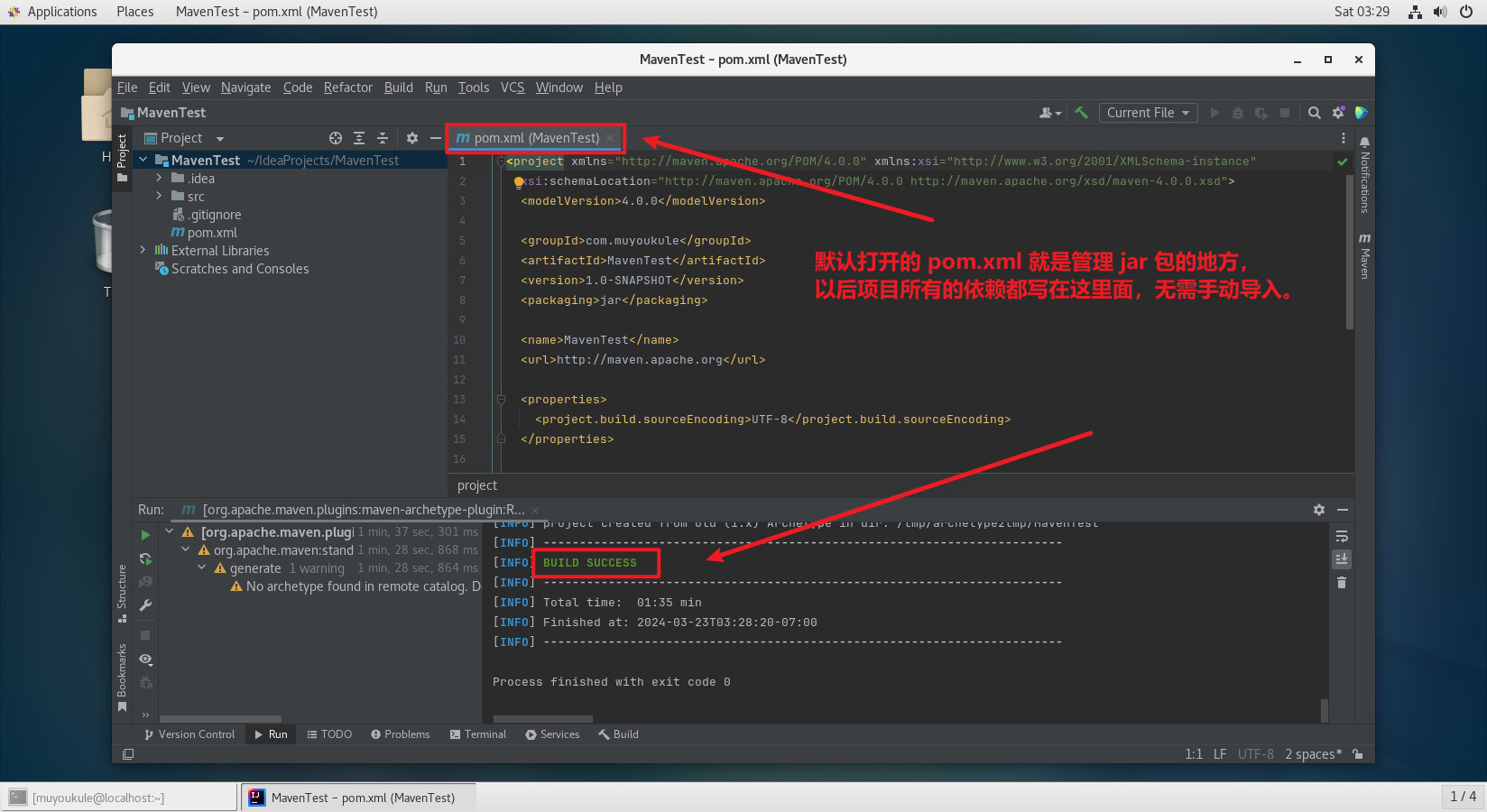
出现 BUILE SUCCESS 表示依赖加载成功,默认打开的 pom.xml 就是管理 jar 包的地方,以后项目所有的依赖都写在这里面,无需手动导入。
创建的 Maven 项目在右侧会出现 Maven 按钮,点开后会看到有 Lifecycle(生命周期)、Plugins(插件)和 Dependencies(依赖)。其中在 Dependencies 里看到已经有一个 junit 依赖,这是创建项目时自动添加,用来做单元测试的,其中不难发现它与 pom.xml 文件里 <dependencies></dependencies> 下的:
1 | <dependency> |
相对应,这是 Maven 引入外部依赖的方式,后续我们使用到的其他依赖也是使用这种形式引入项目。
需要注意的是引入依赖后需要点击以下刷新按钮,在 Dependencies 中看到了相应的依赖才可以进行使用。
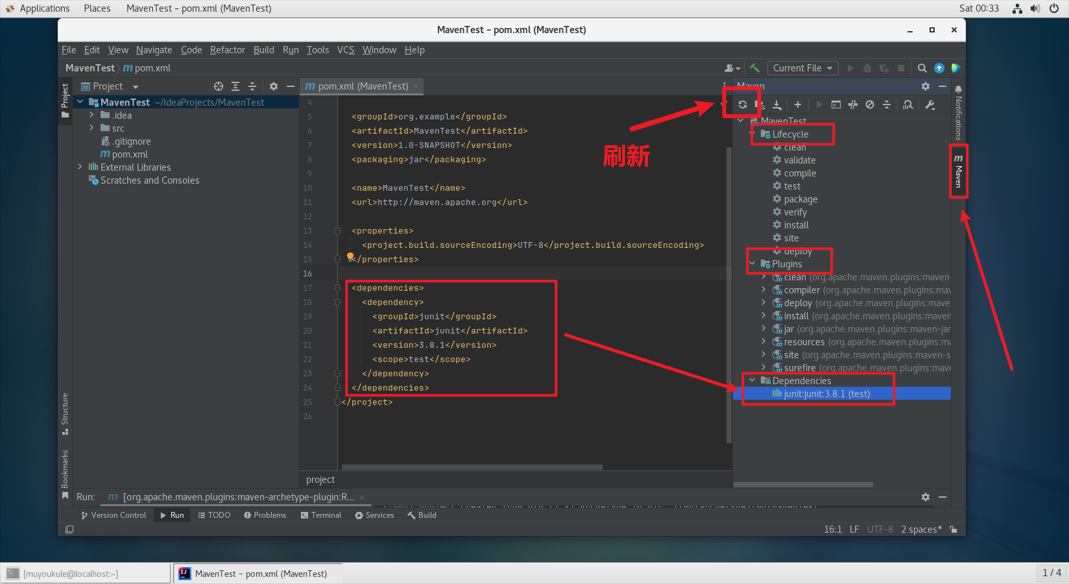
至此,IDEA 新建 Maven 项目成功!就可以进行代码的编写了!!!