0. 前言
今年年初 Java 推出了22版本,但是关我啥事啊?我当然还是爱用 Java 8 咯。那为什么我会如此喜爱 Java 8这个版本呢?那还得从 Java 历代的重要版本说起:
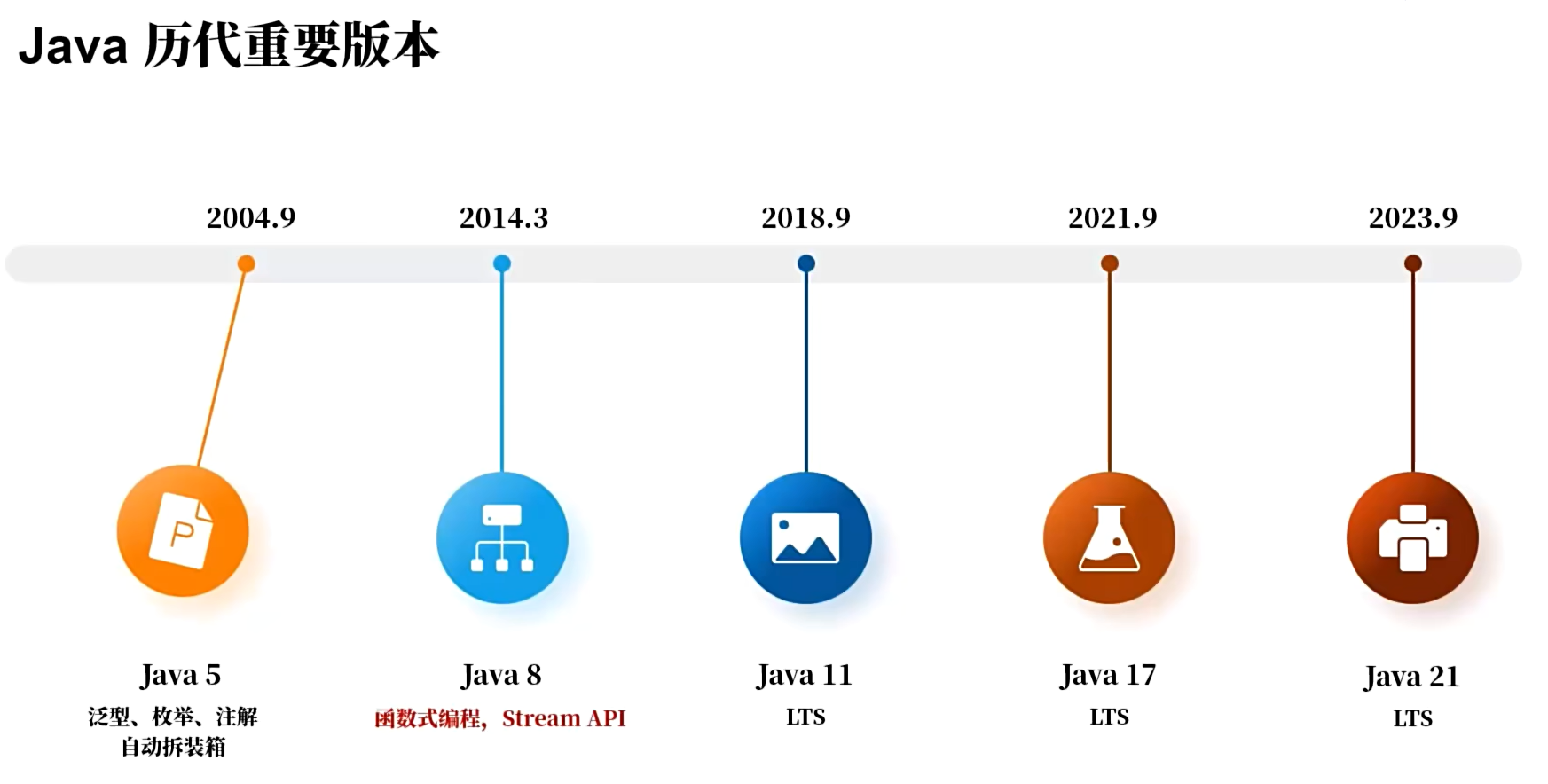
可以看出各个版本的招牌功能:
那函数式编程有什么优点呢?
当然是代码简洁、功能强大、并行处理、链式调用、延时执行咯。总之就俩字 —— “优雅”。
1. 道之伊始
宇宙初开之际,混沌之气笼罩着整个宇宙,一切模糊不清。
然后,盘古开天,女娲造人。
日月乃出、星辰乃现。
山川蜿蜒、江河奔流。
生灵万物,欣欣向荣。
此日月、星辰、山川、江河、生灵万物,
谓之【对象】,皆随时间而化。
然而:日月之行、星汉灿烂,
山川起伏、湖海汇聚,
冥冥中有至理藏其中。
名曰【道】,乃万物遵循之规律,亦谓之【函数】。
它无问东西,亘古不变。
作为设计宇宙洪荒的程序员
- 造日月、筑山川、划江河、开湖海、演化生灵万物、令其生生不息,则必用面向【对象】之手段
- 若定规则、求本源、追纯粹,论不变,则当选【函数】编程之思想
下面就让我们从【函数】开始。
1.1 什么是函数
什么是函数呢?函数即规则,函数 == 道
数学上:
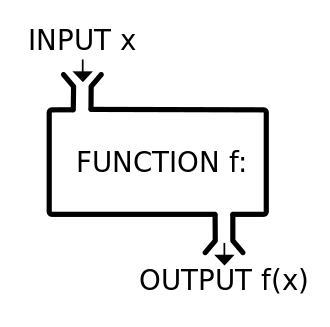
例如:
| INPUT |
f(x) |
OUTPUT |
| 1 |
? |
1 |
| 2 |
? |
4 |
| 3 |
? |
9 |
| 4 |
? |
16 |
| 5 |
? |
25 |
| … |
… |
… |
- f(x) = x^2 是一种规律, input 按照此规律变化为 output
- 很多规律已经由人揭示,例如 e = m * c^2
- 程序设计中更可以自己去制定规律,一旦成为规则的制定者,你就是神
1.2 大道无情
怎样才能成为一个合格的函数?上面提过函数即规则,函数 == 道。那就要先思考那怎样才能成道呢?
成道需要一个先决条件:成到要无情
1.2.1 无情
何为无情?只要输入相同,无论多少次调用,无论什么时间调用,输出相同。
1.2.2 佛祖成道
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class TestMutable {
public static void main(String[] args) {
System.out.println(pray("张三"));
System.out.println(pray("张三"));
System.out.println(pray("张三"));
}
static class Buddha {
String name;
public Buddha(String name) {
this.name = name;
}
}
static Buddha buddha = new Buddha("佛祖");
static String pray(String person) {
return (person + "向[" + buddha.name + "]虔诚祈祷");
}
}
|
以上 pray 的执行结果,除了参数变化外,希望函数的执行规则永远不变
1
2
3
| 张三向[佛祖]虔诚祈祷
张三向[佛祖]虔诚祈祷
张三向[佛祖]虔诚祈祷
|
然而,由于设计上的缺陷,函数引用了外界可变的数据,如果这么使用:
1
2
| buddha.name = "魔王";
System.out.println(pray("张三"));
|
结果就会是:
问题出在哪儿呢?函数的目的是除了参数能变化,其它部分都要不变,这样才能成为规则的一部分。佛祖要成为规则的一部分,也要保持不变。
改正方法:
1
2
3
4
5
6
7
8
9
10
| static class Buddha {
final String name;
public Buddha(String name) {
this.name = name;
}
}
record Buddha(String name) { }
|
- 不是说函数不能引用外界的数据,而是它引用的数据必须也能作为规则的一部分
- 让佛祖不变,佛祖才能成为规则
1.2.3 函数与方法
方法本质上也是函数。不过方法绑定在对象之上,它是对象个人法则。
函数是:函数(对象数据,其它参数)
方法是:对象数据.方法(其它参数)
1.2.4 不变的好处
只有不变,才能在滚滚时间洪流中屹立不倒,成为规则的一部分。
多线程编程中,不变意味着线程安全。
1.2.5 合格的函数无状态
1.3 大道无形
1.3.1 函数化对象
函数本无形,也就是它代表的规则:位置固定、不能传播。
若要有形,让函数的规则能够传播,需要将函数化为对象。
1
2
3
4
5
| public class MyClass {
static int add(int a, int b) {
return a + b;
}
}
|
与
1
2
3
4
5
| interface Lambda {
int calculate(int a, int b);
}
Lambda add = (a, b) -> a + b;
|
区别在哪?
- 前者是纯粹的一条两数加法规则,它的位置是固定的,要使用它,需要通过 MyClass.add 找到它,然后执行
- 而后者(add 对象)就像长了腿,它的位置是可以变化的,想去哪里就去哪里,哪里要用到这条加法规则,把它传递过去(对象可以传到任意地方去,函数不行)
- 接口的目的是为了将来用它来执行函数对象,此接口中只能有一个方法定义
函数化为对象做个比喻:
- 之前是大家要统一去西天取经
- 现在是每个菩萨、罗汉拿着经书,入世传经
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| public class Test {
interface Lambda {
int calculate(int a, int b);
}
static class Server {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8080);
System.out.println("server start...");
while (true) {
Socket s = ss.accept();
Thread.ofVirtual().start(() -> {
try {
ObjectInputStream is = new ObjectInputStream(s.getInputStream());
Lambda lambda = (Lambda) is.readObject();
int a = ThreadLocalRandom.current().nextInt(10);
int b = ThreadLocalRandom.current().nextInt(10);
System.out.printf("%s %d op %d = %d%n",
s.getRemoteSocketAddress().toString(), a, b, lambda.calculate(a, b));
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
});
}
}
}
static class Client1 {
public static void main(String[] args) throws IOException {
try(Socket s = new Socket("127.0.0.1", 8080)){
Lambda lambda = (Lambda & Serializable) (a, b) -> a + b;
ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());
os.writeObject(lambda);
os.flush();
}
}
}
static class Client2 {
public static void main(String[] args) throws IOException {
try(Socket s = new Socket("127.0.0.1", 8080)){
Lambda lambda = (Lambda & Serializable) (a, b) -> a - b;
ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());
os.writeObject(lambda);
os.flush();
}
}
}
static class Client3 {
public static void main(String[] args) throws IOException {
try(Socket s = new Socket("127.0.0.1", 8080)){
Lambda lambda = (Lambda & Serializable) (a, b) -> a * b;
ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());
os.writeObject(lambda);
os.flush();
}
}
}
}
|
上面的例子做了一些简单的扩展,可以看到不同的客户端可以上传自己的计算规则。
PS:
- 大部分文献都说 Lambda 是匿名函数,但满老师觉得需要在这个说法上进行补充
- 至少在 java 里,虽然 Lambda 表达式本身不需要起名字,但不得提供一个对应接口嘛
1.3.2 行为参数化
已知学生类定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| static class Student {
private String name;
private int age;
private String sex;
public Student(String name, int age, String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public String getSex() {
return sex;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
'}';
}
}
|
针对一组学生集合,筛选出男学生,下面的代码实现如何,评价一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static void main(String[] args) {
List<Student> students = List.of(
new Student("张无忌", 18, "男"),
new Student("杨不悔", 16, "女"),
new Student("周芷若", 19, "女"),
new Student("宋青书", 20, "男")
);
System.out.println(filter(students));
}
static List<Student> filter(List<Student> students) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (student.sex.equals("男")) {
result.add(student);
}
}
return result;
}
|
如果需求再变动一下,要求找到 18 岁以下的学生,上面代码显然不能用了,改动方法如下:
1
2
3
4
5
6
7
8
9
10
11
| static List<Student> filter(List<Student> students) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (student.age <= 18) {
result.add(student);
}
}
return result;
}
System.out.println(filter(students));
|
那么需求如果再要变动,找18岁以下男学生,怎么改?显然上述做法并不太好… 更希望一个方法能处理各种情况,仔细观察以上两个方法,找不同。
不同在于筛选条件部分:student.sex.equals("男") 和 student.age <= 18
既然它们就是不同,那么能否把它作为参数传递进来,这样处理起来不就一致了吗?
1
2
3
4
5
6
7
8
9
| static List<Student> filter(List<Student> students, ???) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (???) {
result.add(student);
}
}
return result;
}
|
它俩要判断的逻辑不同,那这两处不同的逻辑必然要用函数来表示,将来这两个函数都需要用到 student 对象来判断,都应该返回一个 boolean 结果,怎么描述函数的长相呢?
1
2
3
| interface Lambda {
boolean test(Student student);
}
|
方法可以统一成下述代码:
1
2
3
4
5
6
7
8
9
| static List<Student> filter(List<Student> students, Lambda lambda) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (lambda.test(student)) {
result.add(student);
}
}
return result;
}
|
好,最后怎么给它传递不同实现呢?
1
| filter(students, student -> student.sex.equals("男"));
|
以及
1
| filter(students, student -> student.age <= 18);
|
还有新需求也能满足
1
| filter(students, student -> student.sex.equals("男") && student.age <= 18);
|
这样就实现了以不变应万变,而变换即是一个个函数对象,也可以称之为行为参数化
1.3.3 延迟执行
在记录日志时,假设日志级别是 INFO,debug 方法会遇到下面的问题:
本不需要记录日志,但 expensive 方法仍被执行了。
1
2
3
4
5
6
7
8
9
10
11
| static Logger logger = LogManager.getLogger();
public static void main(String[] args) {
System.out.println(logger.getLevel());
logger.debug("{}", expensive());
}
static String expensive() {
System.out.println("执行耗时操作");
return "结果";
}
|
改进方法1:
1
2
3
| if (logger.isDebugEnabled()) {
logger.debug("{}", expensive());
}
|
显然这么做,很多类似代码都要加上这样 if 判断,很不优雅。
改进方法2:
在 debug 方法外再套一个新方法,内部逻辑大概是这样:
1
2
3
4
5
| public void debug(final String msg, final Supplier<?> lambda) {
if (this.isDebugEnabled()) {
this.debug(msg, lambda.get());
}
}
|
调用时这样:
1
| logger.debug("{}", () -> expensive());
|
expensive() 变成了不是立刻执行,在未来 if 条件成立时才执行。
1.3.4 函数对象的不同类型
1
2
3
4
5
| Comparator<Student> c =
(Student s1, Student s2) -> Integer.compare(s1.age, s2.age);
BiFunction<Student, Student, Integer> f =
(Student s1, Student s2) -> Integer.compare(s1.age, s2.age);
|
2. 函数编程语法
2.1 表现形式
在 Java 语言中,Lambda 对象有两种形式:Lambda表达式 与 方法引用
Lambda表达式:功能更全面方法引用:写法更简介
Lambda 对象的类型是由它的行为决定的,如果有一些 Lambda 对象,它们的入参类型、返回值类型都一致,那么它们可以看作是同一类的 Lambda 对象,它们的类型,用 函数式接口 来表示。
2.1.1 匿名内部类
匿名内部类 :是内部类的简化写法。他是一个隐含了名字的内部类。开发中,最常用到的内部类就是匿名内部类了。
匿名内部类必须继承一个父类或者实现一个父接口。格式:
1
2
3
| new 父类名或者接口名() {
重写方法;
};
|
包含了:
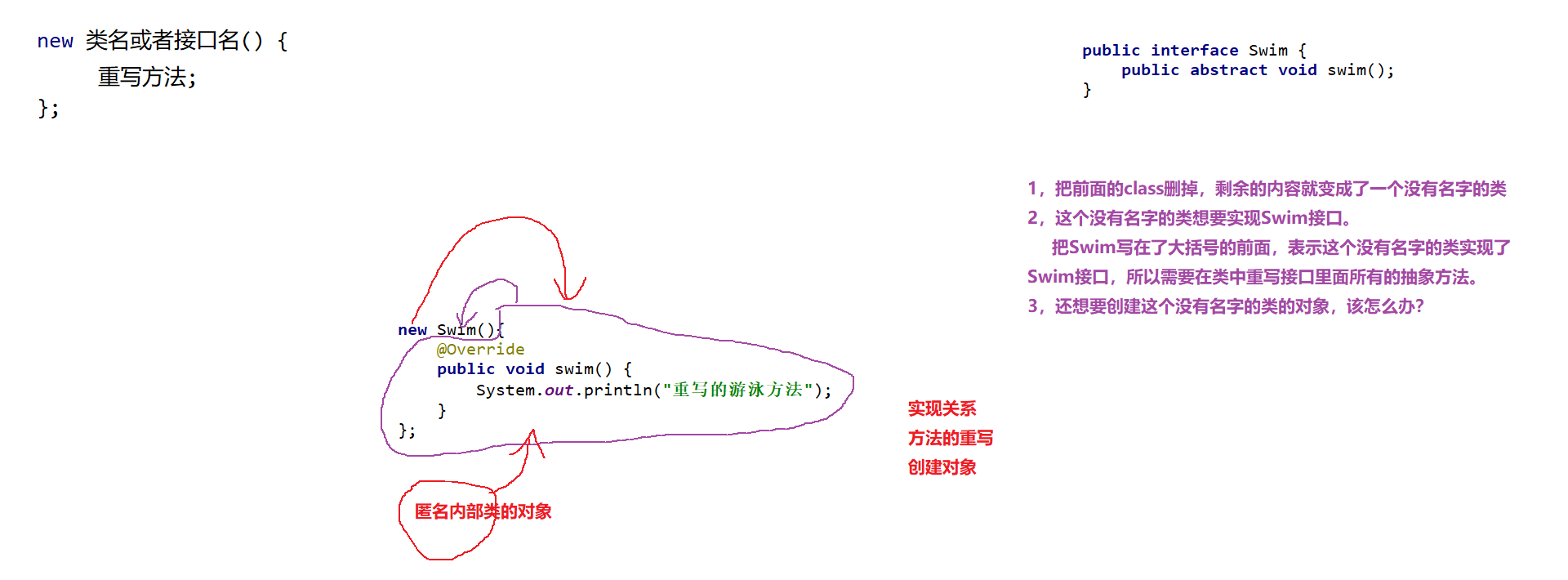
所以从语法上来讲,这个整体其实是匿名内部类的对象。
什么时候用到匿名内部类 ?
匿名内部类的特点:
- 定义一个没有名字的内部类
- 这个类实现了父类,或者父类接口
- 匿名内部类会创建这个没有名字的类的对象
2.1.2 Lambda表达式
语法:
1
| 参数部分(方法的形参) -> 执行逻辑(方法的方法体)
|
注意点:
- Lambda表达式可以用来简化匿名内部类的书写
- Lambda表达式只能简化函数式接口的匿名内部类方法
- 函数式接口:有且仅有一个抽象方法的接口叫函数式接口,接口方法上可以加上
@FunctionalInterface 注解
@FunctionalInterface 作用:在编译期间检查函数式接口是否有且仅有一个抽象方法,如果不满足会提示错误
Lambda的省略规则:
- 参数类型可以省略不写
- 如果只有一个参数,参数类型可以省略,同时()也可以省略
- 如果Lambda表达式的方法体只有一行,大括号、分号、return可以省略不写(需要同时省略)
例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public class LambdaDemo {
public static void main(String[] args) {
Integer[] arr = {2, 3, 6, 4, 7, 8, 5, 9};
Arrays.sort(arr, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
Arrays.sort(arr, (Integer o1, Integer o2) -> {
return o1 - o2;
}
);
Arrays.sort(arr, (o1, o2) -> o1 - o2);
System.out.println(Arrays.toString(arr));
}
}
|
2.1.3 方法引用
方法引用的条件:
- 引用处需要是函数式接口
- 被引用的方法需要已经存在
- 被引用方法的形参和返回值需要跟抽象方法的形参和返回值保持一致
- 被引用方法的功能需要满足当前的要求
方法引用的分类:
- 引用静态方法
- 引用成员方法
- 引用其他类的成员方法
- 引用本类的成员方法
- 引用父类的成员方法
- 引用构造方法
- 其他调用方式
2.2 函数类型
入参类型、返回值类型都一致的话,可以看作同一类的对象。
常见函数接口:

函数接口的命名规律:
| 名称 |
含义 |
| Consumer |
有参、无返回值 |
| Function |
有参、有返回值 |
| Predicate |
有参、返回boolean |
| Supplier |
无参、有返回值 |
| Operator |
有参、有返回值,并且类型一样 |
| 前缀 |
含义 |
| Unary |
一元的意思,表示一个参数 |
| Bi 或 Binary |
二元的意思,表示两个参数 |
| Ternary |
三元 |
| Quatenary |
四元 |
| … |
… |
方法引用也是类似,入参类型、返回值类型都一致的话,可以看作同一类的对象,也是用函数式接口表示。
2.3 几种方法引用
2.3.1 类名::静态方法名
如何理解:
- 函数对象的逻辑部分是:调用此静态方法
- 因此这个静态方法需要什么参数,函数对象也提供相应的参数即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class Type2Test {
public static void main(String[] args) {
Stream.of(
new Student("张无忌", "男"),
new Student("周芷若", "女"),
new Student("宋青书", "男")
)
.filter(Type2Test::isMale)
.forEach(student -> System.out.println(student));
}
static boolean isMale(Student student) {
return student.sex.equals("男");
}
record Student(String name, String sex) {
}
}
|
filter 这个高阶函数接收的函数类型(Predicate)是:一个 T 类型的入参,一个 boolean 的返回值,因此我们只需要给它提供一个相符合的 Lambda 对象即可- isMale 这个静态方法有入参 Student 对应
T,有返回值 boolean 也能对应上,所以可以直接使用
输出:
1
2
| Student[name=张无忌, sex=男]
Student[name=宋青书, sex=男]
|
2.3.2 类名::非静态方法名
如何理解:
- 函数对象的逻辑部分是:调用此非静态方法
- 因此这个函数对象需要提供一个额外的对象参数,以便能够调用此非静态方法
- 非静态方法的剩余参数,与函数对象的剩余参数一一对应
例1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class Type3Test {
public static void main(String[] args) {
highOrder(Student::hello);
}
static void highOrder(Type3 lambda) {
System.out.println(lambda.transfer(new Student("张三"), "你好"));
}
interface Type3 {
String transfer(Student stu, String message);
}
static class Student {
String name;
public Student(String name) {
this.name = name;
}
public String hello(String message) {
return this.name + " say: " + message;
}
}
}
|
上例中函数类型的
- 参数1 对应着 hello 方法所属类型 Student
- 参数2 对应着 hello 方法自己的参数 String
- 返回值对应着 hello 方法自己的返回值 String
输出:
例2:改写之前根据性别过滤的需求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class Type2Test {
public static void main(String[] args) {
Stream.of(
new Student("张无忌", "男"),
new Student("周芷若", "女"),
new Student("宋青书", "男")
)
.filter(Student::isMale)
.forEach(student -> System.out.println(student));
}
record Student(String name, String sex) {
boolean isMale() {
return this.sex.equals("男");
}
}
}
|
filter 这个高阶函数接收的函数类型(Predicate)是:一个 T 类型的入参,一个 boolean 的返回值,因此我们只需要给它提供一个相符合的 Lambda 对象即可- 它的入参1
T 对应着 isMale 非静态方法的所属类型 Student
- 它没有其它参数,isMale 方法也没有参数
- 返回值都是 boolean
输出:
1
2
| Student[name=张无忌, sex=男]
Student[name=宋青书, sex=男]
|
例3:将学生对象仅保留学生的姓名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class Type2Test {
public static void main(String[] args) {
Stream.of(
new Student("张无忌", "男"),
new Student("周芷若", "女"),
new Student("宋青书", "男")
)
.map(Student::name)
.forEach(student -> System.out.println(student));
}
record Student(String name, String sex) {
boolean isMale() {
return this.sex.equals("男");
}
}
}
|
- map 这个高阶函数接收的函数类型是(Function)是:一个
T 类型的参数,一个 R 类型的返回值
- 它的入参1
T 对应着 name 非静态方法的所属类型 Student
- 它没有剩余参数,name 方法也没有参数
- 它的返回值 R 对应着 name 方法的返回值 String
输出:
2.3.3 对象::非静态方法名
如何理解:
- 函数对象的逻辑部分是:调用此非静态方法
- 因为对象已提供,所以不必作为函数对象参数的一部分
- 非静态方法的剩余参数,与函数对象的剩余参数一一对应
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class Type4Test {
public static void main(String[] args) {
Util util = new Util();
Stream.of(
new Student("张无忌", "男"),
new Student("周芷若", "女"),
new Student("宋青书", "男")
)
.filter(util::isMale)
.map(util::getName)
.forEach(student -> System.out.println(student));
}
record Student(String name, String sex) {
boolean isMale() {
return this.sex.equals("男");
}
}
static class Util {
boolean isMale(Student student) {
return student.sex.equals("男");
}
String getName(Student student) {
return student.name();
}
}
}
|
其实较为典型的一个应用就是 System.out 对象中的非静态方法,最后的输出可以修改为:
1
| .forEach(System.out::println);
|
这是因为:
- forEach 这个高阶函数接收的函数类型(Consumer)是一个
T 类型参数,void 无返回值
- 而 System.out 对象中有非静态方法 void println(Object x) 与之一致,因此可以将此方法化为 Lambda 对象给 forEach 使用
2.3.4 类名::new
对于构造方法,也有专门的语法把它们转换为 Lambda 对象。
函数类型应满足:
- 参数部分与构造方法参数一致
- 返回值类型与构造方法所在类一致
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| public class Type5Test {
static class Student {
private final String name;
private final int age;
public Student() {
this.name = "某人";
this.age = 18;
}
public Student(String name) {
this.name = name;
this.age = 18;
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
interface Type51 {
Student create();
}
interface Type52 {
Student create(String name);
}
interface Type53 {
Student create(String name, int age);
}
public static void main(String[] args) {
hiOrder((Type51) Student::new);
hiOrder((Type52) Student::new);
hiOrder((Type53) Student::new);
}
static void hiOrder(Type51 creator) {
System.out.println(creator.create());
}
static void hiOrder(Type52 creator) {
System.out.println(creator.create("张三"));
}
static void hiOrder(Type53 creator) {
System.out.println(creator.create("李四", 20));
}
}
|
2.3.5 this::非静态方法名
算是 类名::非静态方法名 形式的特例,只能用在类内部:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public class Type6Test {
public static void main(String[] args) {
Util util = new UtilExt();
util.hiOrder(Stream.of(
new Student("张无忌", "男"),
new Student("周芷若", "女"),
new Student("宋青书", "男")
));
}
record Student(String name, String sex) {
}
static class Util {
boolean isMale(Student student) {
return student.sex.equals("男");
}
boolean isFemale(Student student) {
return student.sex.equals("女");
}
void hiOrder(Stream<Student> stream) {
stream
.filter(this::isMale)
.forEach(System.out::println);
}
}
}
|
2.3.6 super::非静态方法名
算是 类名::非静态方法名 形式的特例,只能用在类内部(用在要用 super 区分重载方法时):
1
2
3
4
5
6
7
8
9
10
11
12
| public class Type6Test {
static class UtilExt extends Util {
void hiOrder(Stream<Student> stream) {
stream
.filter(super::isFemale)
.forEach(System.out::println);
}
}
}
|
2.3.7 特例
对于无返回值的函数接口,例如 Consumer 和 Runnable,它们可以配合有返回值的函数对象使用(函数接口和方法引用之间,可以差一个返回值),例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class ExceptionTest {
public static void main(String[] args) {
Runnable task1 = ExceptionTest::print1;
Runnable task2 = ExceptionTest::print2;
}
static void print1() {
System.out.println("task1 running...");
}
static int print2() {
System.out.println("task2 running...");
return 1;
}
}
|
可以看到 Runnable 接口不需要返回值,而实际的函数对象多出的返回值也不影响使用。
2.4 闭包(Closure)
何为闭包?闭包就是函数对象与外界变量绑定在一起,形成的整体。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class ClosureTest1 {
interface Lambda {
int add(int y);
}
public static void main(String[] args) {
int x = 10;
highOrder(y -> x + y);
}
static void highOrder(Lambda lambda) {
System.out.println(lambda.add(20));
}
}
|
- 代码中的 $y \rightarrow x + y$ 和 $x = 10$,就形成了一个闭包
- 可以想象成,函数对象有个背包,背包里可以装变量随身携带,将来函数对象甭管传递到多远的地方,包里总装着个 $x = 10$
- 有个限制,局部变量 x 必须是
final 或 effective final 的,effective final 意思就是,虽然没有用 final 修饰,但就像是用 final 修饰了一样,不能重新赋值,否则就语法错误。
- 意味着闭包变量,在装进包里的那一刻,就不能变化了
- 道理也简单,为了保证函数的不变性,防止破坏成道
- 闭包是一种给函数执行提供数据的手段,函数执行既可以使用函数入参,还可以使用闭包变量
例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class ClosureTest2 {
public static void main(String[] args) throws IOException {
List<Runnable> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
int k = i + 1;
Runnable task
= () -> System.out.println(Thread.currentThread()+":执行任务" + k);
list.add(task);
}
ExecutorService service = Executors.newVirtualThreadPerTaskExecutor();
for (Runnable task : list) {
service.submit(task);
}
System.in.read();
}
}
|
2.5 柯里化(Carrying)
柯里化的作用是让函数对象分步执行(本质上是利用多个函数对象和闭包)。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class Carrying1Test {
public static void main(String[] args) {
highOrder(a -> b -> a + b);
}
static void highOrder(Step1 step1) {
Step2 step2 = step1.exec(10);
System.out.println(step2.exec(20));
System.out.println(step2.exec(50));
}
interface Step1 {
Step2 exec(int a);
}
interface Step2 {
int exec(int b);
}
}
|
代码中:
a -> ... 是第一个函数对象,它的返回结果 b -> ... 是第二个函数对象,由第二个函数对象返回最终结果- 后者与前面的参数 a 构成了闭包
- step1.exec(10) 确定了 a 的值是 10,返回第二个函数对象 step2,a 被放入了 step2 对象的背包记下来了
- step2.exec(20) 确定了 b 的值是 20,此时可以执行 a + b 的操作,得到结果 30
- step2.exec(50) 分析过程类似
2.6 高阶函数(Higher-Order Functions)
所谓高阶,就是指它是其他函数对象的使用者。
作用:
- 将通用、复杂的逻辑隐含在高阶函数中
- 将易变、未定的逻辑放在外部的函数对象中
1、内循环
2、遍历二叉树
3、简单流
4、简单流-化简
5、简单流-收集
2.7 等价的 lambda 表达式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| static class Student {
private String name;
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}
|
Math::random
()->Math.random()
Math::sqrt
(double number)->Math.sqrt(number)
Student::getName
(Student stu)->stu.getName()
Student::setName
(Student stu, String newName) -> stu.setName(newName)
Student::hashCode
(Student stu) -> stu.hashCode()
Student::equals
(Student stu, Object o) -> stu.equals(o)
假设已有对象 Student stu = new Student("张三");
stu::getName
()->stu.getName()
stu::setName
(String newName)->stu.setName(newName)
Student::new
(String name)->new Student(name)
3. Stream API
3.1 Stream流的思想
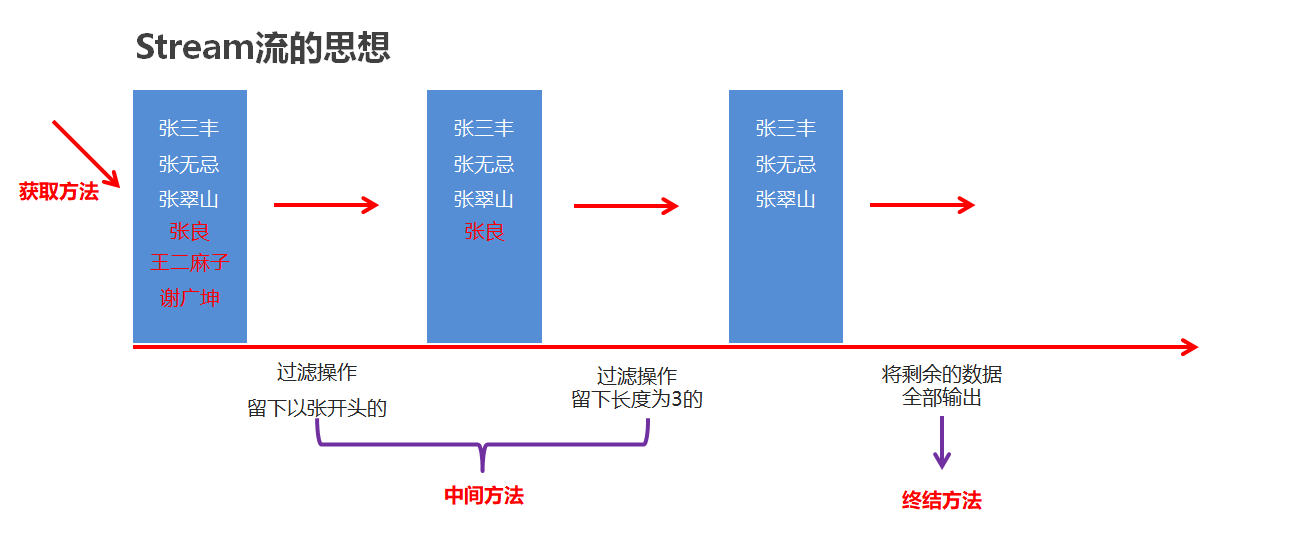
3.2 Stream流作用
结合Lambda表达式,简化集合、数组操作。
3.3 流的三类方法
- 获取Stream流
- 中间方法
- 流水线上的操作
- 一次操作完毕之后,还可以继续进行其他操作
- 终结方法
- 一个Stream流只能有一个终结方法
- 是流水线上的最后一个操作
3.4 Stream使用步骤
- 先得到一条Stream流(流水线),再把数据放上去。
- 使用中间方法对流水线上的数据进行操作。
- 使用终结方法对流水线上的数据进行操作。
生成Stream流的方式
| 获取方式 |
方法名 |
说明 |
| 单列集合 |
default Stream stream() |
Collection中的默认方法 |
| 双列集合 |
无 |
无法直接使用stream流 |
| 数组 |
public static Stream stream(T[] array) |
Arrays工具类中的静态方法 |
| 一堆零散数据 |
public static Stream of(T… values) |
Stream接口中的静态方法 |
PS:Stream接口中静态方法 of 的细节
方法的形参是一个可变参数,可以传递一堆零散的数据,也可以传递数组,但是数组必须是引用数据类型的,如果传递基本数据类型,是会把整个数组当做一个元素,放到Stream当中。
Stream流中间操作方法
概念:中间操作的意思是,执行完此方法之后,Stream流依然可以继续执行其他操作
常见方法:
| 方法名 |
说明 |
| Stream filter(Predicate predicate) |
用于对流中的数据进行过滤 |
| Stream limit(long maxSize) |
返回此流中的元素组成的流,截取前指定参数个数的数据 |
| Stream skip(long n) |
跳过指定参数个数的数据,返回由该流的剩余元素组成的流 |
| static Stream concat(Stream a, Stream b) |
合并a和b两个流为一个流 |
| Stream distinct() |
返回由该流的不同元素(根据Object.equals(Object) )组成的流 |
PS:
- 中间方法,返回新的Stream流,原来的Stream流只能使用一次,建议使用链式编程。
- 修改Stream流中的数据,不会影响原来集合或数组的数据。
Stream流终结操作方法
概念:终结操作的意思是,执行完此方法之后,Stream流将不能再执行其他操作
常用方法:
| 方法名 |
说明 |
| void forEach(Consumer action) |
遍历、打印 |
| long count() |
统计 |
| toArray() |
把结果收集到数组中 |
| collect(Collector collector) |
把结果收集到集合中 |
工具类Collectors提供了具体的集合收集方式:
| 方法名 |
说明 |
| public static Collector toList() |
把元素收集到List集合中 |
| public static Collector toSet() |
把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper,Function valueMapper) |
把元素收集到Map集合中 |
PS:终结操作只能执行一次
3.5 过滤
1
2
3
4
5
6
7
8
9
10
| record Fruit(String cname, String name, String category, String color) { }
Stream.of(
new Fruit("草莓", "Strawberry", "浆果", "红色"),
new Fruit("桑葚", "Mulberry", "浆果", "紫色"),
new Fruit("杨梅", "Waxberry", "浆果", "红色"),
new Fruit("核桃", "Walnut", "坚果", "棕色"),
new Fruit("草莓", "Peanut", "坚果", "棕色"),
new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")
)
|
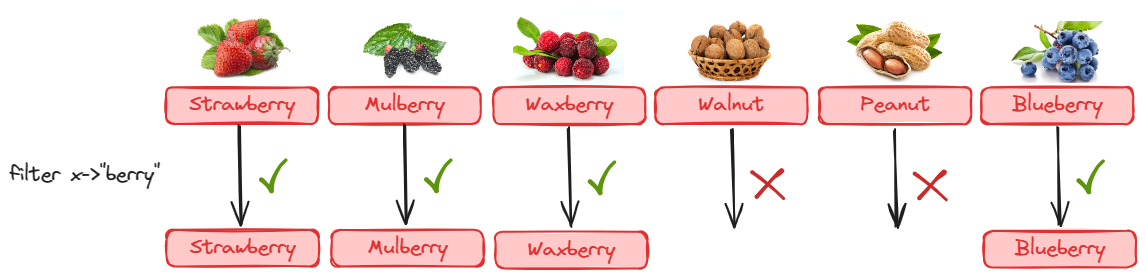
找到所有浆果:
1
| .filter(f -> f.category.equals("浆果"))
|
找到蓝色的浆果:
方法1:
1
| .filter(f -> f.category().equals("浆果") && f.color().equals("蓝色"))
|
方法2:让每个 lambda 只做一件事,两次 filter 相对于并且关系
1
2
| .filter(f -> f.category.equals("浆果"))
.filter(f -> f.color().equals("蓝色"))
|
方法3:让每个 lambda 只做一件事,不过比方法2强的地方可以 or,and,nagate 运算
1
| .filter(((Predicate<Fruit>) f -> f.category.equals("浆果")).and(f -> f.color().equals("蓝色")))
|
3.6 映射
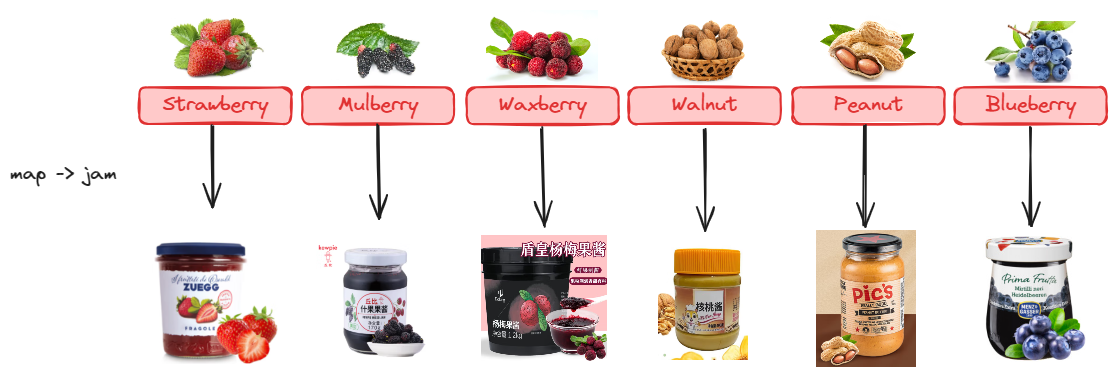
1
| .map(f -> f.cname() + "酱")
|
3.7 降维
例1:
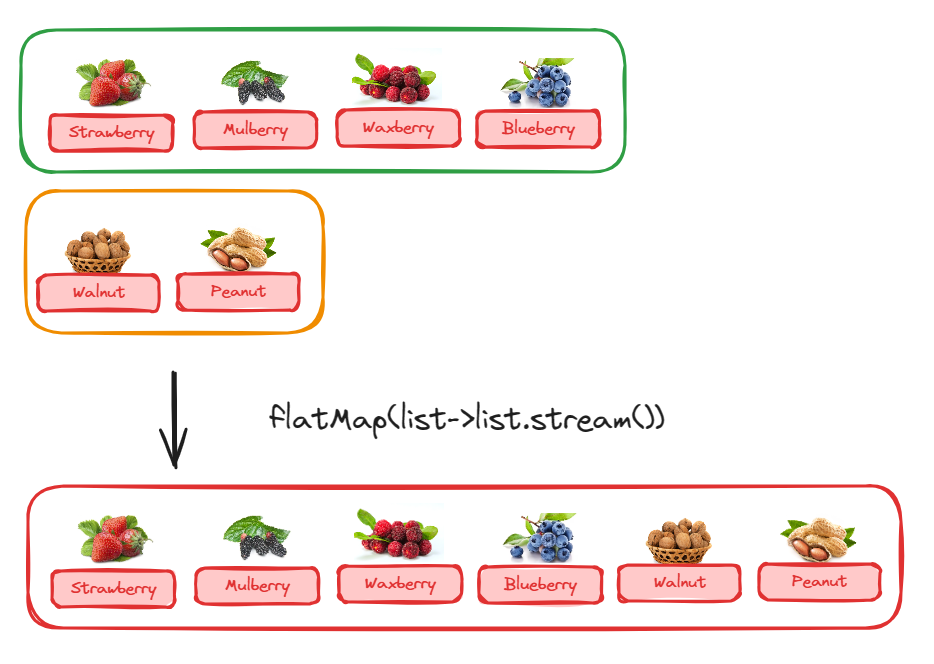
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| record Fruit(String cname, String name, String category, String color) { }
Stream.of(
List.of(
new Fruit("草莓", "Strawberry", "浆果", "红色"),
new Fruit("桑葚", "Mulberry", "浆果", "紫色"),
new Fruit("杨梅", "Waxberry", "浆果", "红色"),
new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")
),
List.of(
new Fruit("核桃", "Walnut", "坚果", "棕色"),
new Fruit("草莓", "Peanut", "坚果", "棕色")
)
)
.flatMap(Collection::stream)
|
这样把坚果和浆果两个集合变成了含六个元素的水果流。
例2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| Stream.of(
new Order(1, List.of(
new Item(6499, 1, "HUAWEI MateBook 14s"),
new Item(6999, 1, "HUAWEI Mate 60 Pro"),
new Item(1488, 1, "HUAWEI WATCH GT 4")
)),
new Order(1, List.of(
new Item(8999, 1, "Apple MacBook Air 13"),
new Item(7999, 1, "Apple iPhone 15 Pro"),
new Item(2999, 1, "Apple Watch Series 9")
))
)
.flatMap(order -> order.items().stream())
|
这样把一个有两个元素的订单流,变成了一个有六个元素的商品流。
3.8 构建
根据已有的数组构建流
根据已有的 Collection 构建流(包括 List,Set 等)
把一个对象变成流
把多个对象变成流
如果是多个数组对象变成流:
数组必须是引用数据类型的,如果传递基本数据类型,是会把整个数组当做一个元素,放到Stream当中。
1
2
3
4
5
6
| int[] arr1 = {1,2,3,4,5,6,7,8,9,10};
String[] arr2 = {"a","b","c"};
Stream.of(arr1).forEach(System.out::println);
System.out.println("-----------");
Stream.of(arr2).forEach(System.out::println);
|
可以看到,如果传递基本数据类型,是会把整个数组当做一个元素,放到Stream当中,打印出来的是一个地址值:
1
2
3
4
5
| [I@446cdf90
-----------
a
b
c
|
3.9 拼接
两个流拼接
1
| Stream.concat(Stream.of("a","b","c"), Stream.of("d"))
|
3.10 截取
1
2
3
| Stream.concat(Stream.of("a", "b", "c"), Stream.of("d"))
.skip(1)
.limit(2)
|
- skip 是跳过几个元素
- limit 是限制处理的元素个数
1
2
| Stream.concat(Stream.of(1, 2, 3), Stream.of(4, 5, 1, 2))
.takeWhile(x -> x < 3)
|
1
2
| Stream.concat(Stream.of(1, 2, 3), Stream.of(4, 5, 1, 2))
.dropWhile(x -> x < 3)
|
3.11 生成
生成从 0 ~ 9 的数字
1
2
3
| IntStream.range(0, 10)
IntStream.rangeClosed(0, 9)
|
如果想订制,可以用 iterate 方法,例如下面生成奇数序列:
1
2
| IntStream.iterate(1, x -> x + 2)
IntStream.iterate(1, x -> x + 2).limit(10)
|
- 参数1 是初始值
- 参数2 是一个特殊 Function,即参数类型与返回值相同,它会根据上一个元素 x 的值计算出当前元素
- 需要用 limit 限制元素个数
也可以用 iterate 的重载方法:
1
| IntStream.iterate(1, x -> x < 10, x -> x + 2)
|
- 参数1 是初始值
- 参数2 用来限制元素个数,一旦不满足此条件,流就结束
- 参数3 相当于上个方法的参数2
iterate 的特点是根据上一个元素计算当前元素,如果不需要依赖上一个元素,可以改用 generate 方法。
例如下面是生成 5 个随机 int:
1
| Stream.generate(()-> ThreadLocalRandom.current().nextInt()).limit(5)
|
不过如果只是生成随机数的话,有更简单的办法
1
| ThreadLocalRandom.current().ints(5)
|
如果要指定上下限,例如下面是生成从 0~9 的100个随机数
1
| ThreadLocalRandom.current().ints(100, 0, 10)
|
3.12 查找与判断
查找
下面的代码找到流中任意(Any)一个偶数
1
2
3
4
5
6
| int[] array = {1, 3, 5, 4, 7, 6, 9};
Arrays.stream(array)
.filter(x -> (x & 1) == 0)
.findAny()
.ifPresent(System.out::println);
|
- 注意 findAny 返回的是
OptionalInt 对象,因为可能流中不存在偶数
- 对于
OptionalInt 对象,一般需要用 ifPresent 或 orElse(提供默认值)来处理
与 findAny 比较类似的是 firstFirst,它俩的区别?
- findAny 是找在流中任意位置的元素,不需要考虑顺序,对于上例返回 6 也是可以的
- findFirst 是找第一个出现在元素,需要考虑顺序,对于上例只能返回 4
- findAny 在顺序流中与 findFirst 表现相同,区别在于并行流下会更快
判断
判断流中是否存在任意一个偶数:
1
| Arrays.stream(array).anyMatch(x -> (x & 1) == 0)
|
判断流是否全部是偶数:
1
| Arrays.stream(array).allMatch(x -> (x & 1) == 0)
|
- 同样,它返回的是 boolean 值,可以直接用来判断
判断流是否全部不是偶数:
1
| Arrays.stream(array).noneMatch(x -> (x & 1) == 0)
|
- noneMatch 与 allMatch 含义恰好相反
3.13 排序与去重
去重
1
2
| IntStream.of(1, 2, 3, 1, 2, 3, 3, 4, 5)
.distinct()
|
排序
已知有数据
1
2
3
4
5
6
7
8
9
10
11
12
13
| record Hero(String name, int strength) { }
Stream.of(
new Hero("独孤求败", 100),
new Hero("令狐冲", 90),
new Hero("风清扬", 98),
new Hero("东方不败", 98),
new Hero("方证", 92),
new Hero("任我行", 92),
new Hero("冲虚", 90),
new Hero("向问天", 88),
new Hero("不戒", 88)
)
|
要求,首先按 strength 武力排序(逆序),武力相同的,按姓名长度排序(正序)
仅用 lambda 来解
1
2
3
4
| .sorted((a,b)-> {
int res = Integer.compare(b.strength(), a.strength());
return (res == 0) ? Integer.compare(a.nameLength(), b.nameLength()) : res;
})
|
方法引用改写
1
2
3
4
5
| .sorted(
Comparator.comparingInt(Hero::strength)
.reversed()
.thenComparingInt(Hero::nameLength)
)
|
其中:
comparingInt 接收一个 key 提取器(说明按对象中哪部分来比较),返回一个比较器reversed 返回一个顺序相反的比较器thenComparingInt 接收一个 key 提取器,返回一个新比较器,新比较器在原有比较器结果相等时执行新的比较逻辑
增加一个辅助方法:
1
2
3
4
5
| record Hero(String name, int strength) {
int nameLength() {
return this.name.length();
}
}
|
原理:
1
2
3
4
5
6
7
8
| .sorted((e, f) -> {
int res =
((Comparator<Hero>) (c, d) ->
((Comparator<Hero>) (a, b) -> Integer.compare(a.strength(), b.strength()))
.compare(d, c))
.compare(e, f);
return (res == 0) ? Integer.compare(e.nameLength(), f.nameLength()) : res;
})
|
如果不好看,改成下面的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| .sorted(step3(step2(step1())))
static Comparator<Hero> step1() {
return (a, b) -> Integer.compare(a.strength(), b.strength());
}
static Comparator<Hero> step2(Comparator<Hero> step1) {
return (c, d) -> step1.compare(d, c);
}
static Comparator<Hero> step3(Comparator<Hero> step2) {
return (e, f) -> {
int res = step2.compare(e, f);
return (res == 0) ? Integer.compare(e.nameLength(), f.nameLength()) : res;
};
}
|
3.14 化简
化简:两两合并,只剩一个
适合:最大值、最小值、求和、求个数…
1
| .reduce(init, (p,x) -> r);
|
init 代表初始值,返回值是一个Optional对象,当不给初始值时,流中没有元素对象的时候返回一个Optional.empty(p,x) -> r 是一个 BinaryOperator,作用是根据上次化简结果 p 和当前元素 x,得到本次化简结果 r
这样两两化简,可以将流中的所有元素合并成一个结果。
3.15 收集
1
| .collect( supplier, accumulator, combiner);
|
- supplier 是描述如何创建收集容器 c :
()-> c
- accumulator 是描述如何向容器 c 添加元素 x:
(c, x) -> void
- combiner 是描述如何合并两个容器:
(c1, c2) -> void
- 串行流下不需要合并容器
- 并行流如果用的是并发容器,也不需要合并
3.16 收集器
通过上面的收集可以看出,不管收集容器的种类有多少种,在收集时都需要三个参数,可以将这三个参数用一个整体来表示,这个整体就叫Collector收集器。JDK给我们提供了一个收集器工具类Collectors,工具类中的静态方法就是用来创建各种不同类型的收集器。
1
| .collect(Collectors.toList());
|
类似,Collectors 类中还提供了很多现成的收集器:
1
2
3
4
| Collectors.toSet()
Collectors.joining()
Collectors.joining(",")
Collectors.toMap(x -> x, x -> 1)
|
3.17 下游收集器
做 groupingBy 分组收集时,组内可能需要进一步的数据收集,称为下游收集器。
一些专门和 groupingBy 配合使用的下游处理器:
| 下游收集器 |
说明 |
| mapping(x->y, dc) |
将 x 转换为 y ,用下游收集器 dc 收集 |
| flatMapping(x->substream, dc) |
将 x 转换为 substream ,用下游收集器 dc 收集 |
| filtering(x->boolean, dc) |
过滤后,用下游收集器 dc 收集 |
| counting() |
求个数 |
| minBy((a,b)->int) |
求最小 |
| maxBy((a,b)->int) |
求最大 |
| summingInt(x->int) |
转 int 后求和 |
| averagingDouble(x->double) |
转 double 后求平均 |
| reducing(init,(p,x)->r) |
init 初始值,用上次结果 p 和当前元素 x 生成本次结果 r |
PS:调用静态方法可以使用 import static 语法省略类名
未省略 Collectors:
1
| stream.collect(Collectors.groupingBy(h -> h.name().length(), Collectors.mapping(h -> h.strength(), Collectors.toList())));
|
使用 import static 语法省略 Collectors:
1
2
3
4
5
6
7
| import static java.util.stream.Collectors.groupingBy;
import static java.util.stream.Collectors.mapping;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.*;
stream.collect(groupingBy(h -> h.name().length(), mapping(h -> h.strength(), toList())));
|
3.18 基本流
基本类型流指 IntStream、LongStream 和 DoubleStream,它们在做数值计算时有更好的性能。
转换成基本流:
- mapToInt
- mapToLong
- mapToDouble
- flatMapToInt
- flatMapToLong
- flatMapToDouble
- mapMultiToInt
- mapMultiToLong
- mapMultiToDouble
基本流转对象流:
3.19 并行
在 Java 中,串行流和并行流是针对流操作的两种不同处理方式:
串行流(Sequential Stream):
- 串行流是流元素按顺序依次处理的流。
- 在串行流中,操作是单线程执行的,每个元素依次经过流水线上的各个阶段处理。
- 适用于简单的数据处理场景,数据量不大且处理时间短的情况下。
并行流(Parallel Stream):
- 并行流是流元素并行处理的流。
- 在并行流中,操作会并发执行,流会被拆分为多个子任务,这些子任务可以在多个线程上同时处理。
- 适用于大规模数据处理、复杂计算或需要并行处理的场景。
并行流例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| Stream.of(1, 2, 3, 4)
.parallel()
.collect(Collector.of(
() -> {
System.out.printf("%-12s %s%n",simple(),"create");
return new ArrayList<Integer>();
},
(list, x) -> {
List<Integer> old = new ArrayList<>(list);
list.add(x);
System.out.printf("%-12s %s.add(%d)=>%s%n",simple(), old, x, list);
},
(list1, list2) -> {
List<Integer> old = new ArrayList<>(list1);
list1.addAll(list2);
System.out.printf("%-12s %s.add(%s)=>%s%n", simple(),old, list2, list1);
return list1;
},
list -> list,
Collector.Characteristics.IDENTITY_FINISH
));
|
3.20 效率
数组求和
其中
- primitive 用 loop 循环对 int 求和
- intStream 用 IntStream 对 int 求和
- boxed 用 loop 循环对 Integer 求和
- stream 用 Stream 对 Integer 求和
元素个数 100
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| T01Sum.primitive |
avgt |
5 |
25.424 |
± 0.782 |
ns/op |
| T01Sum.intStream |
avgt |
5 |
47.482 |
± 1.145 |
ns/op |
| T01Sum.boxed |
avgt |
5 |
72.457 |
± 4.136 |
ns/op |
| T01Sum.stream |
avgt |
5 |
465.141 |
± 4.891 |
ns/op |
元素个数 1000
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| T01Sum.primitive |
avgt |
5 |
270.556 |
± 1.277 |
ns/op |
| T01Sum.intStream |
avgt |
5 |
292.467 |
± 10.987 |
ns/op |
| T01Sum.boxed |
avgt |
5 |
583.929 |
± 57.338 |
ns/op |
| T01Sum.stream |
avgt |
5 |
5948.294 |
± 2209.211 |
ns/op |
元素个数 10000
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| T01Sum.primitive |
avgt |
5 |
2681.651 |
± 12.614 |
ns/op |
| T01Sum.intStream |
avgt |
5 |
2718.408 |
± 52.418 |
ns/op |
| T01Sum.boxed |
avgt |
5 |
6391.285 |
± 358.154 |
ns/op |
| T01Sum.stream |
avgt |
5 |
44414.884 |
± 3213.055 |
ns/op |
结论:
- 做数值计算,优先挑选基本流(IntStream 等)在数据量较大时,它的性能已经非常接近普通 for 循环
- 做数值计算,应当避免普通流(Stream)性能与其它几种相比,慢一个数量级
求最大值
其中(原始数据都是 int,没有包装类)
- custom 自定义多线程并行求最大值
- parallel 并行流求最大值
- sequence 串行流求最大值
- primitive loop 循环求最大值
元素个数 100
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| T02Parallel.custom |
avgt |
5 |
39619.796 |
± 1263.036 |
ns/op |
| T02Parallel.parallel |
avgt |
5 |
6754.239 |
± 79.894 |
ns/op |
| T02Parallel.primitive |
avgt |
5 |
29.538 |
± 3.056 |
ns/op |
| T02Parallel.sequence |
avgt |
5 |
80.170 |
± 1.940 |
ns/op |
元素个数 10000
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| T02Parallel.custom |
avgt |
5 |
41656.093 |
± 1537.237 |
ns/op |
| T02Parallel.parallel |
avgt |
5 |
11218.573 |
± 1994.863 |
ns/op |
| T02Parallel.primitive |
avgt |
5 |
2217.562 |
± 80.981 |
ns/op |
| T02Parallel.sequence |
avgt |
5 |
5682.482 |
± 264.645 |
ns/op |
元素个数 1000000
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| T02Parallel.custom |
avgt |
5 |
194984.564 |
± 25794.484 |
ns/op |
| T02Parallel.parallel |
avgt |
5 |
298940.794 |
± 31944.959 |
ns/op |
| T02Parallel.primitive |
avgt |
5 |
325178.873 |
± 81314.981 |
ns/op |
| T02Parallel.sequence |
avgt |
5 |
618274.062 |
± 5867.812 |
ns/op |
结论:
- 并行流相对自己用多线程实现分而治之更简洁
- 并行流只有在数据量非常大时,才能充分发力,数据量少,还不如用串行流
并行(发)收集
元素个数 100
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| loop1 |
avgt |
5 |
1312.389 |
± 90.683 |
ns/op |
| loop2 |
avgt |
5 |
1776.391 |
± 255.271 |
ns/op |
| sequence |
avgt |
5 |
1727.739 |
± 28.821 |
ns/op |
| parallelNoConcurrent |
avgt |
5 |
27654.004 |
± 496.970 |
ns/op |
| parallelConcurrent |
avgt |
5 |
16320.113 |
± 344.766 |
ns/op |
元素个数 10000
| Benchmark |
Mode |
Cnt |
Score (ns/op) |
Error (ns/op) |
Units |
| loop1 |
avgt |
5 |
211526.546 |
± 13549.703 |
ns/op |
| loop2 |
avgt |
5 |
203794.146 |
± 3525.972 |
ns/op |
| sequence |
avgt |
5 |
237688.651 |
± 7593.483 |
ns/op |
| parallelNoConcurrent |
avgt |
5 |
527203.976 |
± 3496.107 |
ns/op |
| parallelConcurrent |
avgt |
5 |
369630.728 |
± 20549.731 |
ns/op |
元素个数 1000000
| Benchmark |
Mode |
Cnt |
Score (ms/op) |
Error (ms/op) |
Units |
| loop1 |
avgt |
5 |
69.154 |
± 3.456 |
ms/op |
| loop2 |
avgt |
5 |
83.815 |
± 2.307 |
ms/op |
| sequence |
avgt |
5 |
103.585 |
± 0.834 |
ns/op |
| parallelNoConcurrent |
avgt |
5 |
167.032 |
± 15.406 |
ms/op |
| parallelConcurrent |
avgt |
5 |
52.326 |
± 1.501 |
ms/op |
结论:
- sequence 是一个容器单线程收集,数据量少时性能占优
- parallelNoConcurrent 是多个容器多线程并行收集,时间应该花费在合并容器上,性能最差
- parallelConcurrent 是一个容器多线程并发收集,在数据量大时性能较优
MethodHandle 性能
正常方法调用、反射、MethodHandle、Lambda 的性能对比
| Benchmark |
Mode |
Cnt |
Score |
Error |
Units |
| Sample2.lambda |
thrpt |
5 |
389307532.881 |
± 332213073.039 |
ops/s |
| Sample2.method |
thrpt |
5 |
157556577.611 |
± 4048306.620 |
ops/s |
| Sample2.origin |
thrpt |
5 |
413287866.949 |
± 65182730.966 |
ops/s |
| Sample2.reflection |
thrpt |
5 |
91640751.456 |
± 37969233.369 |
ops/s |
4. 实际应用
4.1 数据统计分析
每月的销售量
结果应为
1
2
3
4
5
6
7
8
9
10
11
12
| 1970-01 订单数1307
2020-01 订单数14270
2020-02 订单数17995
2020-03 订单数18688
2020-04 订单数11868
2020-05 订单数40334
2020-06 订单数41364
2020-07 订单数76418
2020-08 订单数100007
2020-09 订单数70484
2020-10 订单数104063
2020-11 订单数66060
|
1
2
3
4
5
6
7
| lines.skip(1)
.map(l -> l.split(","))
.collect(groupingBy(a -> YearMonth.from(formatter.parse(a[TIME])),
TreeMap::new, counting()))
.forEach((k, v) -> {
System.out.println(k + " 订单数 " + v);
});
|
销量最高的月份
结果应为
1
2
3
4
5
6
7
8
9
10
11
12
| 1970-01 订单数1307
2020-01 订单数14270
2020-02 订单数17995
2020-03 订单数18688
2020-04 订单数11868
2020-05 订单数40334
2020-06 订单数41364
2020-07 订单数76418
2020-08 订单数100007
2020-09 订单数70484
2020-10 订单数104063 *
2020-11 订单数66060
|
1
2
3
4
5
6
7
8
| lines.skip(1)
.map(l -> l.split(","))
.collect(groupingBy(a -> YearMonth.from(formatter.parse(a[TIME])), counting()))
.entrySet()
.stream()
.max(Comparator.comparingLong(Map.Entry::getValue))
.orElse(null);
|
求销量最高的商品
结果应为
1
| 1515966223517846928=2746
|
1
2
3
4
5
6
7
| lines.skip(1)
.map(l -> l.split(","))
.collect(groupingBy(a -> a[PRODUCT_ID], counting()))
.entrySet()
.stream()
.max(Comparator.comparingLong(Map.Entry::getValue))
.orElse(null);
|
下单最多的前10用户
结果应为
1
2
3
4
5
6
7
8
9
10
| 1.515915625512423e+18 订单数1092
1.5159156255121183e+18 订单数1073
1.515915625512378e+18 订单数1040
1.515915625512377e+18 订单数1028
1.5159156255136955e+18 订单数1002
1.515915625512422e+18 订单数957
1.515915625513446e+18 订单数957
1.515915625513447e+18 订单数928
1.515915625514598e+18 订单数885
1.5159156255147195e+18 订单数869
|
1
2
3
4
5
6
7
8
9
| lines.skip(1)
.map(l -> l.split(","))
.collect(groupingBy(a -> a[USER_ID], counting()))
.entrySet()
.stream()
.sorted(Map.Entry.<String, Long>comparingByValue().reversed())
.limit(10).forEach(e -> {
System.out.println(e.getKey() + " 订单数 " + e.getValue());
});
|
或者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| static class MyQueue<E> extends PriorityQueue<E> {
private int max;
public MyQueue(Comparator<? super E> comparator, int max) {
super(comparator);
this.max = max;
}
@Override
public boolean offer(E e) {
boolean r = super.offer(e);
if (this.size() > max) {
this.poll();
}
return r;
}
}
lines.skip(1)
.map(l -> l.split(","))
.collect(groupingBy(a -> a[USER_ID], counting()))
.entrySet()
.stream()
.parallel()
.collect(
() -> new MyQueue<>(Map.Entry.comparingByValue(), 10),
MyQueue::offer,
AbstractQueue::addAll
);
|
每个地区下单最多的用户
结果应为:
1
2
3
4
5
6
7
8
9
10
11
| 上海=Optional[1.5159156255127636e+18=634]
广东=Optional[1.515915625512377e+18=1028]
天津=Optional[1.5159156255120858e+18=530]
四川=Optional[1.5159156255121551e+18=572]
浙江=Optional[1.5159156255121183e+18=564]
重庆=Optional[1.515915625512764e+18=632]
湖北=Optional[1.5159156255121183e+18=509]
湖南=Optional[1.5159156255120548e+18=545]
江苏=Optional[1.5159156255122386e+18=551]
海南=Optional[1.5159156255121178e+18=556]
北京=Optional[1.5159156255128172e+18=584]
|
1
2
3
4
5
6
7
8
9
10
| lines.skip(1)
.map(line -> line.split(","))
.collect(groupingBy(array -> array[USER_REGION],
groupingBy(array -> array[USER_ID], counting())))
.entrySet().stream()
.map(e -> Map.entry(
e.getKey(),
e.getValue().entrySet().stream().max(Map.Entry.comparingByValue())
))
.forEach(System.out::println);
|
每个地区下单最多的前3用户
结果应为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| 上海
--------------------------
1.5159156255127636e+18=634
1.515915625512118e+18=583
1.515915625512422e+18=561
广东
--------------------------
1.515915625512377e+18=1028
1.5159156255121544e+18=572
1.5159156255120845e+18=571
天津
--------------------------
1.5159156255120858e+18=530
1.5159156255122383e+18=504
1.5159156255123333e+18=481
四川
--------------------------
1.5159156255121551e+18=572
1.5159156255123768e+18=568
1.515915625512055e+18=552
浙江
--------------------------
1.5159156255121183e+18=564
1.515915625513058e+18=520
1.515915625512423e+18=513
重庆
--------------------------
1.515915625512764e+18=632
1.5159156255121188e+18=572
1.515915625512085e+18=562
湖北
--------------------------
1.5159156255121183e+18=509
1.515915625512818e+18=508
1.5159156255148017e+18=386
湖南
--------------------------
1.5159156255120548e+18=545
1.5159156255120855e+18=543
1.5159156255134449e+18=511
江苏
--------------------------
1.5159156255122386e+18=551
1.5159156255122842e+18=541
1.5159156255120842e+18=499
海南
--------------------------
1.5159156255121178e+18=556
1.5159156255128174e+18=547
1.5159156255122022e+18=545
北京
--------------------------
1.5159156255128172e+18=584
1.515915625512423e+18=579
1.5159156255123786e+18=558
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| lines.skip(1)
.map(l -> l.split(","))
.collect(groupingBy(a -> a[USER_REGION], groupingBy(a -> a[USER_ID], counting())))
.entrySet()
.stream()
.map(e ->
Map.entry(
e.getKey(),
e.getValue().entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue().reversed())
.limit(3)
.toList()
)
).forEach(e -> {
System.out.println(e.getKey());
System.out.println("--------------------------");
e.getValue().forEach(System.out::println);
});
|
按类别统计销量
结果应为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
| accessories.bag 订单数 3063
accessories.umbrella 订单数 33
apparel.costume 订单数 2
apparel.glove 订单数 1942
apparel.shirt 订单数 235
apparel.shoes 订单数 2
apparel.sock 订单数 21
apparel.trousers 订单数 99
apparel.tshirt 订单数 372
appliances.environment.air_conditioner 订单数 7379
appliances.environment.air_heater 订单数 2599
appliances.environment.climate 订单数 101
appliances.environment.fan 订单数 3855
appliances.environment.vacuum 订单数 15971
appliances.environment.water_heater 订单数 3644
appliances.iron 订单数 8249
appliances.ironing_board 订单数 2128
appliances.kitchen.blender 订单数 8672
appliances.kitchen.coffee_grinder 订单数 811
appliances.kitchen.coffee_machine 订单数 1250
appliances.kitchen.dishwasher 订单数 2663
appliances.kitchen.fryer 订单数 97
appliances.kitchen.grill 订单数 1579
appliances.kitchen.hood 订单数 9045
appliances.kitchen.juicer 订单数 1187
appliances.kitchen.kettle 订单数 12740
appliances.kitchen.meat_grinder 订单数 4520
appliances.kitchen.microwave 订单数 7615
appliances.kitchen.mixer 订单数 2610
appliances.kitchen.oven 订单数 4000
appliances.kitchen.refrigerators 订单数 20259
appliances.kitchen.steam_cooker 订单数 464
appliances.kitchen.toster 订单数 1381
appliances.kitchen.washer 订单数 14563
appliances.personal.hair_cutter 订单数 2716
appliances.personal.massager 订单数 1724
appliances.personal.scales 订单数 6727
appliances.sewing_machine 订单数 1576
appliances.steam_cleaner 订单数 119
auto.accessories.alarm 订单数 252
auto.accessories.anti_freeze 订单数 109
auto.accessories.compressor 订单数 276
auto.accessories.player 订单数 117
auto.accessories.radar 订单数 80
auto.accessories.videoregister 订单数 533
computers.components.cdrw 订单数 158
computers.components.cooler 订单数 3377
computers.components.cpu 订单数 4147
computers.components.hdd 订单数 5054
computers.components.memory 订单数 1597
computers.components.motherboard 订单数 860
computers.components.power_supply 订单数 986
computers.components.sound_card 订单数 26
computers.components.videocards 订单数 1190
computers.desktop 订单数 1041
computers.ebooks 订单数 397
computers.gaming 订单数 164
computers.network.router 订单数 6473
computers.notebook 订单数 25866
computers.peripherals.camera 订单数 1041
computers.peripherals.joystick 订单数 1192
computers.peripherals.keyboard 订单数 3803
computers.peripherals.monitor 订单数 3272
computers.peripherals.mouse 订单数 12664
computers.peripherals.printer 订单数 3458
computers.peripherals.scanner 订单数 74
construction.components.faucet 订单数 133
construction.tools.drill 订单数 622
construction.tools.generator 订单数 46
construction.tools.heater 订单数 348
construction.tools.light 订单数 10
construction.tools.pump 订单数 65
construction.tools.saw 订单数 169
construction.tools.screw 订单数 2408
construction.tools.welding 订单数 183
country_yard.cultivator 订单数 33
country_yard.lawn_mower 订单数 111
country_yard.watering 订单数 5
country_yard.weather_station 订单数 53
electronics.audio.acoustic 订单数 438
electronics.audio.dictaphone 订单数 12
electronics.audio.headphone 订单数 20084
electronics.audio.microphone 订单数 1062
electronics.audio.subwoofer 订单数 70
electronics.calculator 订单数 35
electronics.camera.photo 订单数 348
electronics.camera.video 订单数 133
electronics.clocks 订单数 6474
electronics.smartphone 订单数 102365
electronics.tablet 订单数 6395
electronics.telephone 订单数 2437
electronics.video.projector 订单数 114
electronics.video.tv 订单数 17618
furniture.bathroom.bath 订单数 232
furniture.bathroom.toilet 订单数 44
furniture.bedroom.bed 订单数 451
furniture.bedroom.blanket 订单数 68
furniture.bedroom.pillow 订单数 1882
furniture.kitchen.chair 订单数 3084
furniture.kitchen.table 订单数 11260
furniture.living_room.cabinet 订单数 3117
furniture.living_room.chair 订单数 1439
furniture.living_room.shelving 订单数 2572
furniture.living_room.sofa 订单数 401
furniture.universal.light 订单数 22
kids.bottles 订单数 63
kids.carriage 订单数 41
kids.dolls 订单数 379
kids.fmcg.diapers 订单数 11
kids.skates 订单数 1159
kids.swing 订单数 8
kids.toys 订单数 643
medicine.tools.tonometer 订单数 1106
sport.bicycle 订单数 569
sport.diving 订单数 10
sport.ski 订单数 17
sport.snowboard 订单数 3
sport.tennis 订单数 87
sport.trainer 订单数 210
stationery.battery 订单数 5210
stationery.cartrige 订单数 2473
stationery.paper 订单数 1085
stationery.stapler 订单数 97
|
1
2
3
4
5
6
7
| lines.skip(1)
.map(l -> l.split(","))
.filter(a -> !a[CATEGORY_CODE].isEmpty())
.collect(groupingBy(a -> a[CATEGORY_CODE], TreeMap::new, counting()))
.forEach((k, v) -> {
System.out.println(k + " 订单数 " + v);
});
|
按一级类别统计销量
结果应为
1
2
3
4
5
6
7
8
9
10
11
12
13
| accessories 订单数 3096
apparel 订单数 2673
appliances 订单数 150244
auto 订单数 1367
computers 订单数 76840
construction 订单数 3984
country_yard 订单数 202
electronics 订单数 157585
furniture 订单数 24572
kids 订单数 2304
medicine 订单数 1106
sport 订单数 896
stationery 订单数 8865
|
1
2
3
4
5
6
7
| lines.skip(1)
.map(l -> l.split(","))
.filter(a -> !a[CATEGORY_CODE].isEmpty())
.collect(groupingBy(TestData::firstCategory, TreeMap::new, counting()))
.forEach((k, v) -> {
System.out.println(k + " 订单数 " + v);
});
|
1
2
3
4
5
| static String firstCategory(String[] a) {
String category = a[CATEGORY_CODE];
int dot = category.indexOf(".");
return category.substring(0, dot);
}
|
按价格区间统计销量
- p <100
- 100<= p <500
- 500<=p<1000
- 1000<=p
结果应为
1
2
3
4
| [0,100)=291624
[1000,∞)=14514
[500,1000)=52857
[100,500)=203863
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| static String priceRange(Double price) {
if (price < 100) {
return "[0,100)";
} else if (price >= 100 && price < 500) {
return "[100,500)";
} else if (price >= 500 && price < 1000) {
return "[500,1000)";
} else {
return "[1000,∞)";
}
}
lines.skip(1)
.map(line -> line.split(","))
.map(array -> Double.parseDouble(array[PRICE]))
.collect(groupingBy(TestData::priceRange, counting()))
|
不同年龄段女性所下不同类别订单
- a < 18
- 18 <= a < 30
- 30 <= a < 50
- 50 <= a
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| [0,18) accessories 81
[0,18) apparel 60
[0,18) appliances 4326
[0,18) computers 1984
...
[18,30) accessories 491
[18,30) apparel 488
[18,30) appliances 25240
[18,30) computers 13076
...
[30,50) accessories 890
[30,50) apparel 893
[30,50) appliances 42755
[30,50) computers 21490
...
[50,∞) accessories 41
[50,∞) apparel 41
[50,∞) appliances 2255
[50,∞) computers 1109
...
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| static String ageRange(String[] array) {
int age = Double.valueOf(array[USER_AGE]).intValue();
if (age < 18) {
return "[0,18)";
} else if (age < 30) {
return "[18,30)";
} else if (age < 50) {
return "[30,50)";
} else {
return "[50,∞)";
}
}
lines.skip(1)
.map(line -> line.split(","))
.filter(array -> !array[CATEGORY_CODE].isEmpty())
.filter(array -> array[USER_SEX].equals("女"))
.collect(groupingBy(TestData::ageRange,
groupingBy(TestData::firstCategory, TreeMap::new, counting())))
|
4.2 异步处理
要让一段逻辑异步:
- 需要有独立线程
- 逻辑需要封装至函数对象,才能让此逻辑不是立刻执行,而是在新线程中的未来某刻执行
例 1: 使用ExecutorService
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static Logger logger = LoggerFactory.getLogger("Test");
public static void main(String[] args) {
try (ExecutorService service = Executors.newFixedThreadPool(2)) {
logger.info("开始统计");
service.submit(() -> monthlySalesReport(map->map.entrySet().forEach(e->logger.info(e.toString()))));
logger.info("执行其它操作");
}
}
private static void monthlySalesReport(Consumer<Map<YearMonth, Long>> consumer) {
try (Stream<String> lines = Files.lines(Path.of("./data.txt"))) {
Map<YearMonth, Long> collect = lines.skip(1)
.map(line -> line.split(","))
.collect(groupingBy(array -> YearMonth.from(formatter.parse(array[TIME])), TreeMap::new, counting()));
consumer.accept(collect);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
|
缺点:
例 2: 使用CompletableFuture
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static Logger logger = LoggerFactory.getLogger("Test");
public static void main(String[] args) throws InterruptedException {
logger.info("开始统计");
CompletableFuture
.supplyAsync(() -> monthlySalesReport())
.thenAccept(map -> map.entrySet().forEach(e -> logger.info(e.toString())));
logger.info("执行其它操作");
Thread.sleep(10000);
}
private static Map<YearMonth, Long> monthlySalesReport() {
try (Stream<String> lines = Files.lines(Path.of("./data.txt"))) {
Map<YearMonth, Long> collect = lines.skip(1)
.map(line -> line.split(","))
.collect(groupingBy(array -> YearMonth.from(formatter.parse(array[TIME])), TreeMap::new, counting()));
return collect;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
|
4.3 框架设计
- 什么是框架?
- 半成品软件,帮助开发者快速构建应用程序
- 框架提供的都是固定不变的、已知的、可以重用的代码
- 而那些每个应用不同的业务逻辑,变化的、未知的部分,则在框架外由开发者自己实现
4.3.1 将未知交给子类
Spring 延迟创建 bean
1
2
3
4
5
6
7
8
9
10
11
| classDiagram
class DefaultSingletonBeanRegistry {
- singletonObjects: Map
+ getSingleton(name, factory)
}
class AbstractAutowireCapableBeanFactory {
# createBean(name, definition, args)
}
DefaultSingletonBeanRegistry <|-- AbstractAutowireCapableBeanFactory
|
Spring 中的很多类有非常复杂的继承关系,并且它们分工明确,职责是划分好的。例如:
DefaultSingletonBeanRegistry 是父类,它有个职责是缓存单例 bean,用下面方法实现
1
| public Object getSingleton(String beanName, ObjectFactory<?> factory)
|
但如何创建 bean,这个父类是不知道的,创建 bean 是子类 AbstractAutowireCapableBeanFactory 的职责
1
2
3
| Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
...
}
|
父类中 getSingleton 的内部就要使用 singletonFactory 函数对象来获得创建好的对象
1
2
3
4
5
6
7
8
9
| public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
...
Object singletonObject = this.singletonObjects.get(beanName);
if(singletonObject == null) {
...
singletonObject = singletonFactory.getObject();
addSingleton(beanName, singletonObject);
}
}
|
最后子类创建单例 bean 时,会把 ObjectFactory 这个函数对象传进去,创建其它 scope bean,不需要用 getSingleton 缓存
1
2
3
4
5
6
7
8
9
10
| protected <T> T doGetBean(...) {
...
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
...
return createBean(beanName, mbd, args);
});
}
...
}
|
4.3.2 将未知交给用户
JdbcTemplate
数据表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| create table student (
id int primary key auto_increment,
name varchar(16),
sex char(1)
);
insert into student values
(1, '赵一伤', '男'),
(2, '钱二败', '男'),
(3, '孙三毁', '男'),
(4, '李四摧', '男'),
(5, '周五输', '男'),
(6, '吴六破', '男'),
(7, '郑七灭', '男'),
(8, '王八衰', '男');
|
spring 中 JdbcTemplate 代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class TestJdbc {
public static void main(String[] args) {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root");
JdbcTemplate template = new JdbcTemplate(dataSource);
String sql = "select id,name,sex from student";
template.query(sql, (rs, index) -> {
int id = rs.getInt("id");
String name = rs.getString("name");
String sex = rs.getString("sex");
return new Student(id, name, sex);
}).forEach(System.out::println);
}
record Student(int id, String name, String sex) {
}
}
|
- 对 query 来讲,建立数据库连接,创建 Statement 对象,执行查询这些步骤都是固定的
- 而结果要如何用 java 对象封装,这对框架代码是未知的,用
RowMapper 接口代表,将来它的 lambda 实现将结果转换成需要的 java 对象
ApplicationListener
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class MyEvent extends ApplicationEvent {
public MyEvent(Object source) {
super(source);
}
}
@SpringBootApplication
public class TestExtend {
public static void main(String[] args) {
ConfigurableApplicationContext context
= SpringApplication.run(TestExtend.class, args);
context.publishEvent(new MyEvent("context"));
}
@Bean
public ApplicationListener<MyEvent> myListener() {
return (event -> System.out.println("收到事件:" + event));
}
@RestController
static class MyController {
@Autowired
private ApplicationContext context;
@GetMapping("/hello")
public String hello() {
context.publishEvent(new MyEvent("controller"));
return "hello";
}
}
}
|
- 对 spring 来讲,它并不知道如何处理事件
- 因此可以提供一个类型为 ApplicationListener 的 lambda 对象
4.3.3 延迟拼接条件
MybatisPlus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @SpringBootApplication
@MapperScan
public class TestMyBatisPlus {
public static void main(String[] args) {
ConfigurableApplicationContext context
= SpringApplication.run(TestMyBatisPlus.class, args);
StudentMapper mapper = context.getBean(StudentMapper.class);
test(mapper, List.of("赵一伤"));
}
static void test(StudentMapper mapper, List<String> names) {
LambdaQueryWrapper<Student> query = new LambdaQueryWrapper<>();
query.in(!names.isEmpty(), Student::getName, names);
System.out.println(mapper.selectList(query));
}
}
|
比较典型的用法有两处:
第一,在调用 in 等方法添加条件时,第一个参数是 boolean 为 true 才会拼接 SQL 条件,否则不拼接。
如何实现的呢?用 DoSomething 类型的 lambda 对象来延迟拼接操作:
1
2
3
4
5
6
7
8
9
10
11
| @FunctionalInterface
public interface DoSomething {
void doIt();
}
protected final Children maybeDo(boolean condition, DoSomething something) {
if (condition) {
something.doIt();
}
return typedThis;
}
|
然而,它在实现 ()->appendSqlSegments(...) 拼接时,是不断修改一个 expression 状态变量,为函数编程所不齿。
4.3.4 偏门用法
第二,如果用 LambdaQueryWrapper 拼接 sql 条件时,为了取得列名,采用了这个办法:
它要做的事很简单,但内部实现却比较复杂:
- 必须用
Student::getName 方法引用,而不能用其它 Lambda 对象
Student::getName 会实现 Serializable 接口,序列化时会把它变成 SerializedLambda- 想办法拿到 SerializedLambda 对象(反射调用 writeReplace)
- 通过 SerializedLambda 能够获得它对应的实际方法,也就是 String getName() 和所在类 Student
- 再通过方法名推导得到属性名(去掉 is,get)即 name
- 所在类 Student 知道了,属性名 name 也有了,就可以进一步确定列名
- 属性上的
@TableField 指定的列名优先
- 没有
@TableField,把属性名当作列名
PS:
- 不是很喜欢这种做法,比较恶心
- 但它确实是想做这么一件事:在代码中全面使用 java 的字段名,避免出现数据库的列名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public static void main(String[] args) throws Exception {
Type2 lambda = (Type2 & Serializable) Student::getName;
Method writeReplace = lambda.getClass().getDeclaredMethod("writeReplace");
SerializedLambda serializedLambda = (SerializedLambda) writeReplace.invoke(lambda);
System.out.println(serializedLambda.getCapturingClass());
System.out.println(serializedLambda.getImplClass());
System.out.println(serializedLambda.getImplMethodName());
}
interface Type2 {
String get(Student student);
}
interface Type1 {
int add(int a, int b);
}
|
4.4 并行计算
统计页面的访问次数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| public class ParallelTest {
static Pattern reg = Pattern.compile("(\\S+) - \\[(.+)] (.+) (.+)");
private static final int FILES = 100;
public static void main(String[] args) throws ExecutionException, InterruptedException {
for (int i = 0; i < 5; i++) {
sequence();
}
}
private static void sequence() throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
Map<String, Long> m0 = new HashMap<>();
for (int i = 0; i < FILES; i++) {
Map<String, Long> mi = one(i);
m0 = Stream.of(m0, mi)
.flatMap(m -> m.entrySet().stream())
.collect(toMap(Map.Entry::getKey, Map.Entry::getValue, Long::sum));
}
long sum = 0;
for (Map.Entry<String, Long> e : m0.entrySet()) {
sum += e.getValue();
}
System.out.println(sum);
System.out.println("cost: " + (System.currentTimeMillis() - start));
}
private static Map<String, Long> one(int i) {
try (Stream<String> lines = Files.lines(Path.of(String.format("web_server_access_%d.log", i)))) {
return lines
.map(reg::matcher)
.filter(Matcher::find)
.map(matcher -> matcher.group(3))
.collect(groupingBy(identity(), counting()));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static void parallel() throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
List<CompletableFuture<Map<String, Long>>> futures = new ArrayList<>();
for (int i = 0; i < FILES; i++) {
int k = i;
CompletableFuture<Map<String, Long>> future = CompletableFuture.supplyAsync(() -> one(k));
futures.add(future);
}
CompletableFuture<Map<String, Long>> f0 = futures.getFirst();
for (int i = 1; i < futures.size(); i++) {
f0 = f0.thenCombine(futures.get(i), (m1, m2) ->
Stream.of(m1, m2)
.flatMap(m -> m.entrySet().stream())
.collect(toMap(Map.Entry::getKey, Map.Entry::getValue, Long::sum))
);
}
Map<String, Long> map = f0.get();
long sum = 0;
for (Map.Entry<String, Long> e : map.entrySet()) {
sum += e.getValue();
}
System.out.println(sum);
System.out.println("cost: " + (System.currentTimeMillis() - start));
}
}
|
4.5 UI 事件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class TestUIEvent {
public static void main(String[] args) {
JFrame frame = new JFrame("Lambda Example");
JButton button = new JButton("Click me");
button.addActionListener(e -> {
System.out.println("Button clicked!");
});
frame.add(button);
frame.setSize(300, 200);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setVisible(true);
}
}
|
5. 实现原理
5.1 lambda 原理
以下面代码为例:
1
2
3
4
5
6
7
8
9
| public class TestLambda {
public static void main(String[] args) {
test((a, b) -> a + b);
}
static void test(BinaryOperator<Integer> lambda) {
System.out.println(lambda.apply(1, 2));
}
}
|
执行结果:
5.1.1 第一步,生成静态方法
如何证明?用反射
1
2
3
| for (Method method : TestLambda.class.getDeclaredMethods()) {
System.out.println(method);
}
|
输出为(去掉了包名,容易阅读):
1
2
3
| public static void TestLambda.main(java.lang.String[])
static void TestLambda.test(BinaryOperator)
private static java.lang.Integer TestLambda.lambda$main$0(Integer,Integer)
|
可以看到除了我们自己写的 main 和 test 以外,多出一个名为 lambda$main$0 的方法
这个方法是在编译期间由编译器生成的方法,是 synthetic(合成)方法
它的参数、内容就是 lambda 表达式提供的参数和内容,如下面代码片段所示
1
2
3
| private static Integer lambda$main$0(Integer a, Integer b) {
return a + b;
}
|
5.1.2 第二步,生成实现类字节码
如果是我自己造一个对象包含此方法,可以这么做。
先创建一个类:
1
2
3
4
5
6
7
| final class LambdaObject implements BinaryOperator<Integer> {
@Override
public Integer apply(Integer a, Integer b) {
return TestLambda.lambda$main$0(a, b);
}
}
|
将来使用时,创建对象:
1
| test(new LambdaObject());
|
只不过,jvm 是在运行期间造出的这个类以及对象而已,要想查看这个类
在 jdk 21 中运行时添加虚拟机参数:
1
| -Djdk.invoke.LambdaMetafactory.dumpProxyClassFiles
|
早期 jdk 添加的参数是(没有去进行版本比对了):
1
| -Djdk.internal.lambda.dumpProxyClasses
|
若想实现在运行期间生成上述 class 字节码,有两种手段:
- 一是动态代理,jdk 并没有采用这种办法来生成 Lambda 类
- 二是用
LambdaMetaFactory,它配合 MethodHandle API 在执行时更具性能优势
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public class TestLambda1 {
public static void main(String[] args) throws Throwable {
test((a, b) -> a + b);
MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodType factoryType = MethodType.methodType(BinaryOperator.class);
MethodType interfaceMethodType = MethodType.methodType(Object.class, Object.class, Object.class);
MethodType implementsMethodType = MethodType.methodType(Integer.class, Integer.class, Integer.class);
MethodHandle implementsMethod = lookup.findStatic(TestLambda1.class, "lambda$main$1", implementsMethodType);
MethodType lambdaType = MethodType.methodType(Integer.class, Integer.class, Integer.class);
CallSite callSite = LambdaMetafactory.metafactory(lookup,
"apply", factoryType, interfaceMethodType,
implementsMethod,
lambdaType);
BinaryOperator<Integer> lambda = (BinaryOperator) callSite.getTarget().invoke();
test(lambda);
}
static Integer lambda$main$1(Integer a, Integer b) {
return a + b;
}
static void test(BinaryOperator<Integer> lambda) {
System.out.println(lambda.apply(1, 2));
}
}
|
其中:
5.2 方法引用原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class TestLambda3 {
public static void main(String[] args) throws Throwable {
test(String::toLowerCase);
MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodType factoryType = MethodType.methodType(Function.class);
MethodType interfaceMethodType = MethodType.methodType(Object.class, Object.class);
MethodHandle implementsMethod = lookup.findVirtual(String.class, "toLowerCase", MethodType.methodType(String.class));
MethodType lambdaType = MethodType.methodType(String.class, String.class);
CallSite callSite = LambdaMetafactory.metafactory(lookup,
"apply", factoryType, interfaceMethodType,
implementsMethod,
lambdaType);
Function<String, String> lambda = (Function<String, String>) callSite.getTarget().invoke();
System.out.println(lambda.apply("Tom"));
}
static void test(Function<String,String> lambda) {
System.out.println(lambda.apply("Tom"));
}
}
|
5.3 闭包原理
捕获基本类型变量:
1
2
3
4
5
6
| int c = 10;
test((a, b) -> a + b + c);
static void test(BinaryOperator<Integer> lambda) {
System.out.println(lambda.apply(1, 2));
}
|
生成一个带 3 个参数的方法,但它和 BinaryOperator 还差一个 int 参数:
1
2
3
| static Integer lambda$main$1(int c, Integer a, Integer b) {
return a + b + c;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public class TestLambda2 {
public static void main(String[] args) throws Throwable {
MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodType factoryType = MethodType.methodType(BinaryOperator.class, int.class);
MethodType interfaceMethodType = MethodType.methodType(Object.class, Object.class, Object.class);
MethodType implementsMethodType = MethodType.methodType(Integer.class, int.class, Integer.class, Integer.class);
MethodHandle implementsMethod = lookup.findStatic(TestLambda2.class, "lambda$main$1", implementsMethodType);
MethodType lambdaType = MethodType.methodType(Integer.class, Integer.class, Integer.class);
CallSite callSite = LambdaMetafactory.metafactory(lookup,
"apply", factoryType, interfaceMethodType,
implementsMethod,
lambdaType);
BinaryOperator<Integer> lambda = (BinaryOperator) callSite.getTarget().invoke(10);
test(lambda);
}
static Integer lambda$main$1(int c, Integer a, Integer b) {
return a + b + c;
}
static void test(BinaryOperator<Integer> lambda) {
System.out.println(lambda.apply(1, 2));
}
}
|
不同之处:
- factoryType,除了原本的接口类型之外,多了实现方法第一个参数的类型
- 产生 lambda 对象的时候,通过 invoke 把这个参数的实际值传进去
这样产生的 LambdaType 就是这样,并且生成 Lambda 对象时,c 的值被固定为 10
1
2
3
4
5
6
7
8
9
10
11
| final class LambdaType implements BinaryOperator {
private final int c;
private TestLambda2$$Lambda(int c) {
this.c = c;
}
public Object apply(Object a, Object b) {
return TestLambda2.lambda$main$1(this.c, (Integer)a, (Integer)b);
}
}
|
捕获引用类型变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public class TestLambda4 {
static class MyRef {
int age;
public MyRef(int age) {
this.age = age;
}
}
public static void main(String[] args) throws Throwable {
MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodType factoryType = MethodType.methodType(BinaryOperator.class, MyRef.class);
MethodType interfaceMethodType = MethodType.methodType(Object.class, Object.class, Object.class);
MethodType implementsMethodType = MethodType.methodType(Integer.class, MyRef.class, Integer.class, Integer.class);
MethodHandle implementsMethod = lookup.findStatic(TestLambda4.class, "lambda$main$1", implementsMethodType);
MethodType lambdaType = MethodType.methodType(Integer.class, Integer.class, Integer.class);
CallSite callSite = LambdaMetafactory.metafactory(lookup,
"apply", factoryType, interfaceMethodType,
implementsMethod,
lambdaType);
BinaryOperator<Integer> lambda = (BinaryOperator) callSite.getTarget().bindTo(new MyRef(20)).invoke();
test(lambda);
}
static Integer lambda$main$1(MyRef c, Integer a, Integer b) {
return a + b + c.age;
}
static void test(BinaryOperator<Integer> lambda) {
System.out.println(lambda.apply(1, 2));
}
}
|
与捕获基本类型变量类似,不过:
除了
1
| callSite.getTarget().invoke(new MyRef(20));
|
还可以
1
| callSite.getTarget().bindTo(new MyRef(20)).invoke();
|
5.4 Stream 构建
自定义可切分迭代器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| public class TestSpliterator {
static class MySpliterator<T> implements Spliterator<T> {
T[] array;
int begin;
int end;
public MySpliterator(T[] array, int begin, int end) {
this.array = array;
this.begin = begin;
this.end = end;
}
@Override
public boolean tryAdvance(Consumer<? super T> action) {
if (begin > end) {
return false;
}
action.accept(array[begin++]);
return true;
}
@Override
public Spliterator<T> trySplit() {
if (estimateSize() > 5) {
int mid = (begin + end) >>> 1;
MySpliterator<T> res = new MySpliterator<>(array, begin, mid);
System.out.println(Thread.currentThread().getName() + "=>" + res);
begin = mid + 1;
return res;
}
return null;
}
@Override
public String toString() {
return Arrays.toString(Arrays.copyOfRange(array, begin, end + 1));
}
@Override
public long estimateSize() {
return end - begin + 1;
}
@Override
public int characteristics() {
return Spliterator.SUBSIZED | Spliterator.ORDERED;
}
}
public static void main(String[] args) {
Integer[] all = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
MySpliterator<Integer> spliterator = new MySpliterator<>(all, 0, 9);
StreamSupport.stream(spliterator, false)
.parallel()
.forEach(x -> System.out.println(Thread.currentThread().getName() + ":" + x));
}
}
|
练习:按每次切分固定大小来实现






