【步骤四】利用R进行数据可视化分析
写在前面
简介:本文章基于厦门大学提供的大数据课程实验案例:网站用户行为分析,通过使用 CentOS 操作编写而来。具体介绍请打开链接进行阅读。
这里介绍几点值得特别注意的事项:
1、对于案例所涉及的系统及软件此文档使用的是以下版本,其他软件版本随意:
- Linux系统(CentOS7)
- MySQL(5.7)
- Hadoop(3.1.3)
- HBase(2.2.2,HBase版本需要和Hadoop版本兼容)
- Hive(3.1.2,Hive需要和Hadoop版本兼容)
- Sqoop(1.4.7)
- R(3.6.0)
- IDEA( 2023.3.6 社区版)
PS:Hadoop 与 HBase、Hive 版本一定要兼容!!!版本一定要兼容!!!这很重要!!!😃😃😃其他软件随意。
2、所有下载的安装包均在 / 目录下。所有安装的软件均在 /usr/local/ 目录下以 软件名-版本号 方式命名。在进行每个软件的安装操作之前请先整体阅读整个软件安装流程的文章有个整体思路,了解到安装此软件需要做哪些设置再进行操作,这样可以避免很多不必要的麻烦。
3、此案例分为五个步骤,请按照步骤顺序进行阅读!!🙂🙂
1. 环境
1、由于官方仓库中没有 R 的软件包所以需要先安装 epel-release 软件包
1 | # 先安装epel-release软件包 |
EPEL (Extra Packages for Enterprise Linux) 是一个基于Fedora的项目,为 RHEL(Red Hat Enterprise Linux)及其衍生发行版如 CentOS、Scientific Linux 等提供额外的软件包。安装 epel-release 软件包可以扩展这些系统上的软件包选择,特别是那些官方仓库中没有的软件包或更新版本的软件包。
2、安装 R 语言
1 | sudo yum -y install R |
安装结束后,可以执行下面命令启动 R:
1 | R |
启动后,会显示如下信息,并进入 > 命令提示符状态:

> 就是 R 的命令提示符,你可以在后面输入 R 语言命令。可以执行下面命令退出R:
1 | q() |
2. 可视化分析MySQL中的数据
2.1 安装依赖库
为了完成可视化功能,我们需要为 R 安装一些依赖库,包括:RMySQL、ggplot2、devtools 和 recharts。
RMySQL是一个提供了访问 MySQL 数据库的R语言接口程序的R语言依赖库。ggplot2和recharts则是R语言中提供绘图可视化功能的依赖库。
启动 R 进入 R 命令提示符状态,执行如下命令安装 RMySQL:
1 | install.packages('RMySQL') |
上面命令执行后, 屏幕会提示 Would you like to user a personal library instead?(y/n) 等问题,只要遇到提问,都在键盘输入y后回车即可。然后,屏幕会显示 ---在此连线阶段时请选用CRAN的镜子--- ,并会弹出一个白色背景的竖条形窗口,窗口标题是 HTTPS CRAN mirros,标题下面列出了很多国家的镜像列表,我们可以选择位于 China 的镜像,比如,选择 China (Beijing 2) [https] ,然后点击 Enter 按钮,就开始安装了。安装过程需要几分钟(当然,也和当前网络速度有关系)。
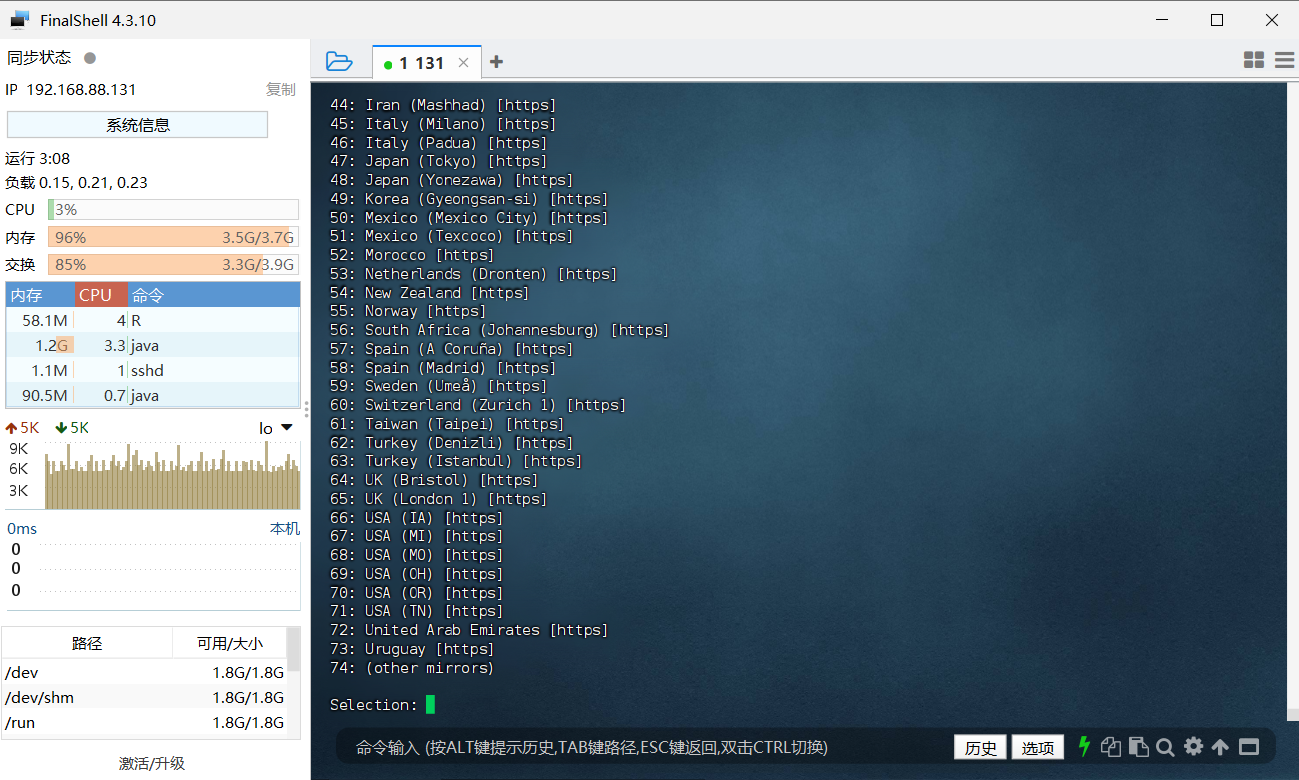
由于不同用户的开发环境(虚拟机)不一样,安装有很大可能因为缺少组件导致失败,如果出现如下错误信息:
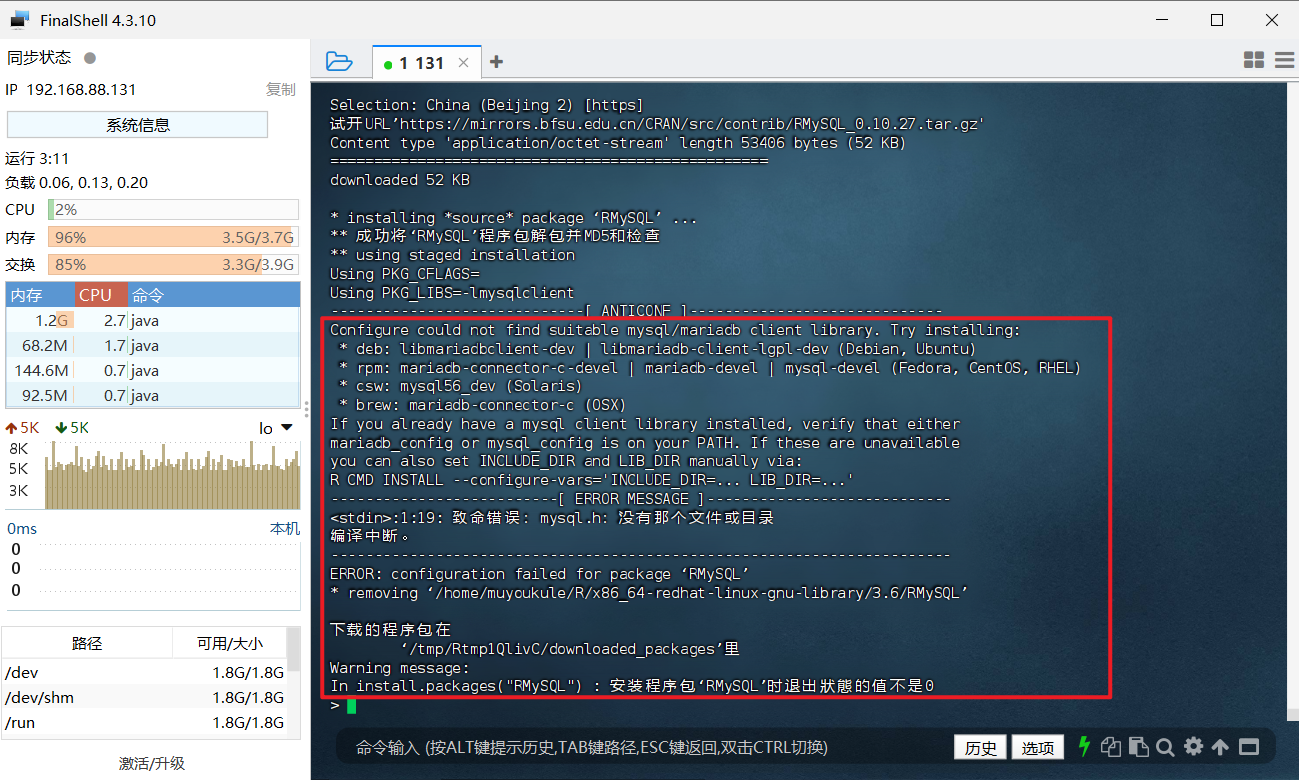
只要根据错误给出的错误信息,进行操作即可。q() 退出 R 命令提示符状态,回到 Shell 状态,根据上面的英文错误信息,就需要在Shell 命令提示符状态下执行下面命令安装 libmariadb-client-lgpl-dev :
1 | sudo yum -y install mariadb-devel |
然后,再次输入下面命令进入 R 命令提示符状态:
1 | R |
成功会出现以下信息:
1 | 下载的程序包在 |
和上面一样继续安装以下包,如果还出现缺少组件的错误,请按照上面的解决方案解决!:
1 | install.packages('ggplot2') |
1 | install.packages('devtools') |
1 | install.packages('DBI') |
如果在上面安装包的过程中,又出现了错误,处理方法很简单,还是按照上面介绍的方法,根据屏幕上给出的英文错误信息,缺少什么软件,就用 sudo yum -y install 命令安装该软件就可以了。我在 CentOS上执行安装时,用到了以下几个软件,安装命令如下:
1 | sudo yum -y install harfbuzz-devel fribidi-devel fontconfig-devel libfreetype6-dev libjpeg-turbo-devel |
你在安装过程中,可能会出现不同的错误,按照同样的处理方法可以顺利解决。
PS:在 CentOS 系统和 Ubuntu 系统软件名可能会有差异,在安装时会提示找不到可用的包,你可以在英文错误信息中找到软件包关键字使用以下命令进行包的查找。😀
1 | 查找特定的包 |
上面的包安装好后,下面在 R 命令提示符下再执行如下命令安装 taiyun/recharts:
1 | devtools::install_github('taiyun/recharts') |
2.2 分析
以下分析使用的函数方法,都可以使用如下命令查询函数的相关文档。例如:查询 sort() 函数如何使用
1 | ?sort |
这时,就会进入冒号 : 提示符状态(也就是帮助文档状态),在冒号后面输入q即可退出帮助文档状态,返回到 R 提示符状态!
连接 MySQL 获取数据,请在 Linux 系统中新建另外一个终端,然后执行下面命令启动 MySQL 数据库:
1 | # 启动 MySQL |
然后进入 MySQL 命令提示符状态:
1 | mysql -u root -p |
会提示你输入密码,输入密码,就进入了 mysql> 提示符状态,下面就可以输入一些 SQL 语句查询数据:
1 | use dblab; |
这样,就可以查看到数据库 dblab 中的 user_action 表的前10行记录,如下:
1 | +--------+-----------+-----------+---------------+---------------+------------+-----------+ |
然后切换到刚才已经打开的R命令提示符终端窗口:
1 | library(DBI) |
1、分析消费者对商品的行为
1 | summary(user_action$behavior_type) |
summary() 函数可以得到样本数据类型和长度,如果样本是数值型,我们还能得到样本数据的最小值、最大值、四分位数以及均值信息。
得到结果:
1 | Length Class Mode |
可以看出原来的 MySQL 数据中,消费者行为变量的类型是字符型。这样不好做比较,需要把消费者行为变量转换为数值型变量
1 | summary(as.numeric(user_action$behavior_type)) |
得到结果:
1 | Min. 1st Qu. Median Mean 3rd Qu. Max. |
接下来用柱状图表示:
1 | library(ggplot2) |
在使用 ggplot2 库的时候,需要使用library导入库。ggplot()绘制时,创建绘图对象,即第一个图层,包含两个参数(数据与变量名称映射)。变量名称需要被包含aes函数里面。ggplot2 的图层与图层之间用 + 进行连接。ggplot2 包中的 geom_histogram() 可以很方便的实现直方图的绘制。
分析结果如下图:
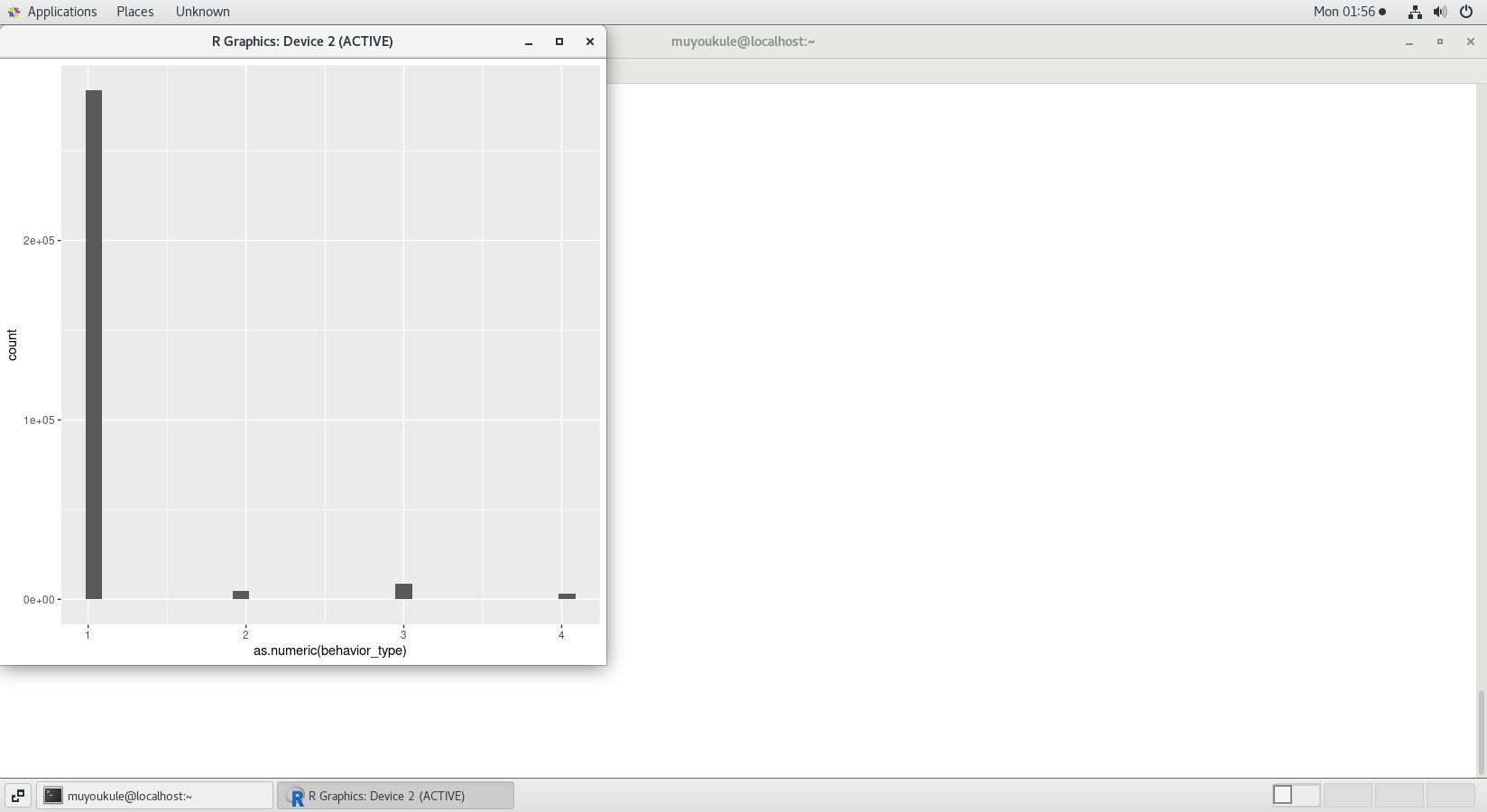
从上图可以得到:大部分消费者行为仅仅只是浏览。只有很少部分的消费者会购买商品。
2、分析哪一类商品被购买总量前十的商品和被购买总量
1 | # 获取子数据集 |
subset() 函数,从某一个数据框中选择出符合某条件的数据或是相关的列.table()对应的就是统计学中的列联表,是一种记录频数的方法。sort() 进行排序,返回排序后的数值向量。
得到结果:
1 | 6344 1863 5232 12189 7957 4370 13230 11537 1838 5894 |
结果第一行表示商品分类,该类下被消费的数次。
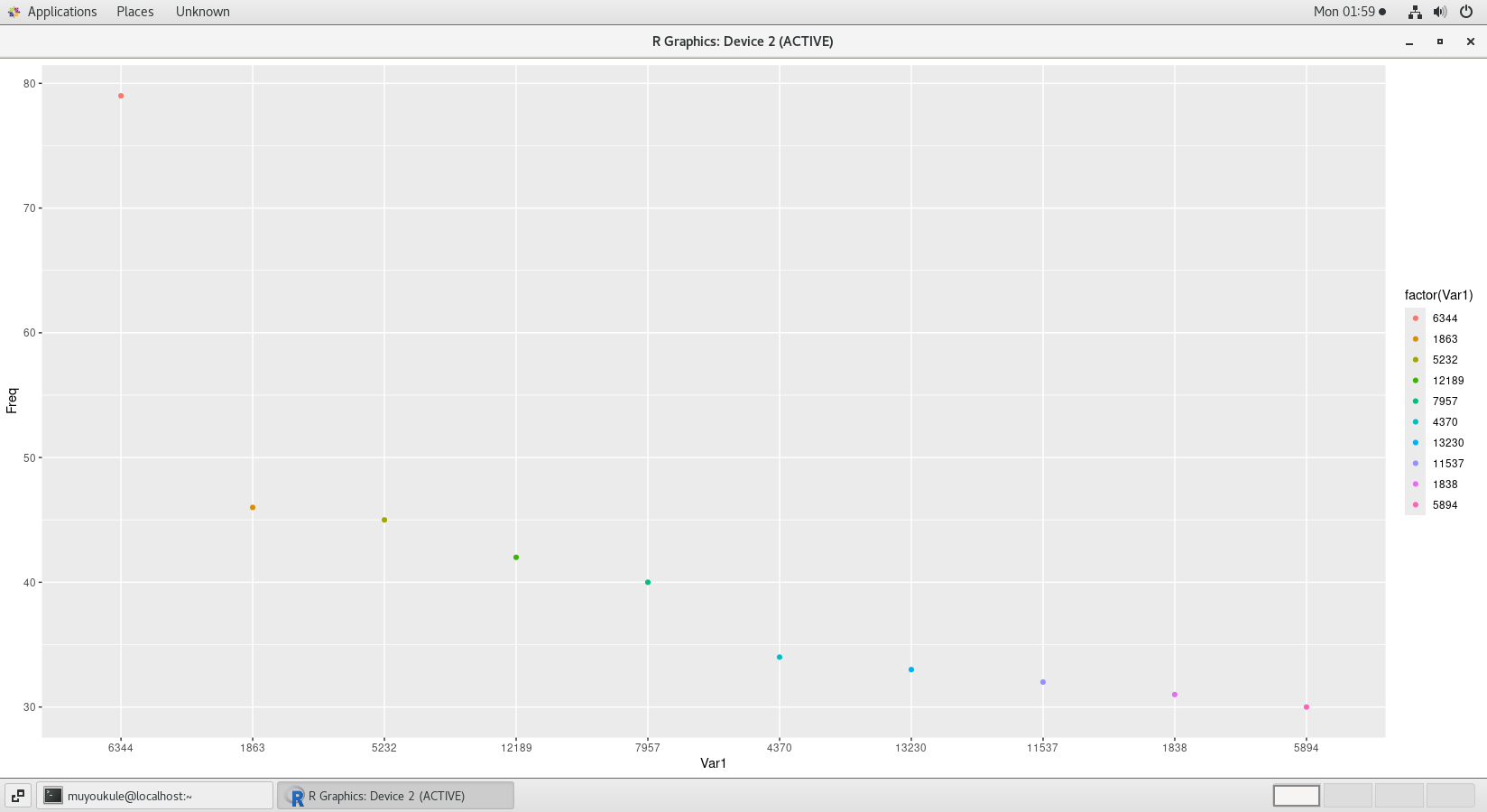
接下来用散点图表示:
1 | #将count矩阵结果转换成数据框 |
通过 as.data.frame() 把矩阵等转换成为数据框。
分析结果如下图:
3、分析每年的哪个月份购买商品的量最多
从 MySQL 直接获取的数据中 visit_date 变量都是 2014 年份,并没有划分出具体的月份,那么可以在数据集增加一列月份数据。
1 | # visit_date变量中截取月份 |
接下来用柱状图分别表示消费者购买量
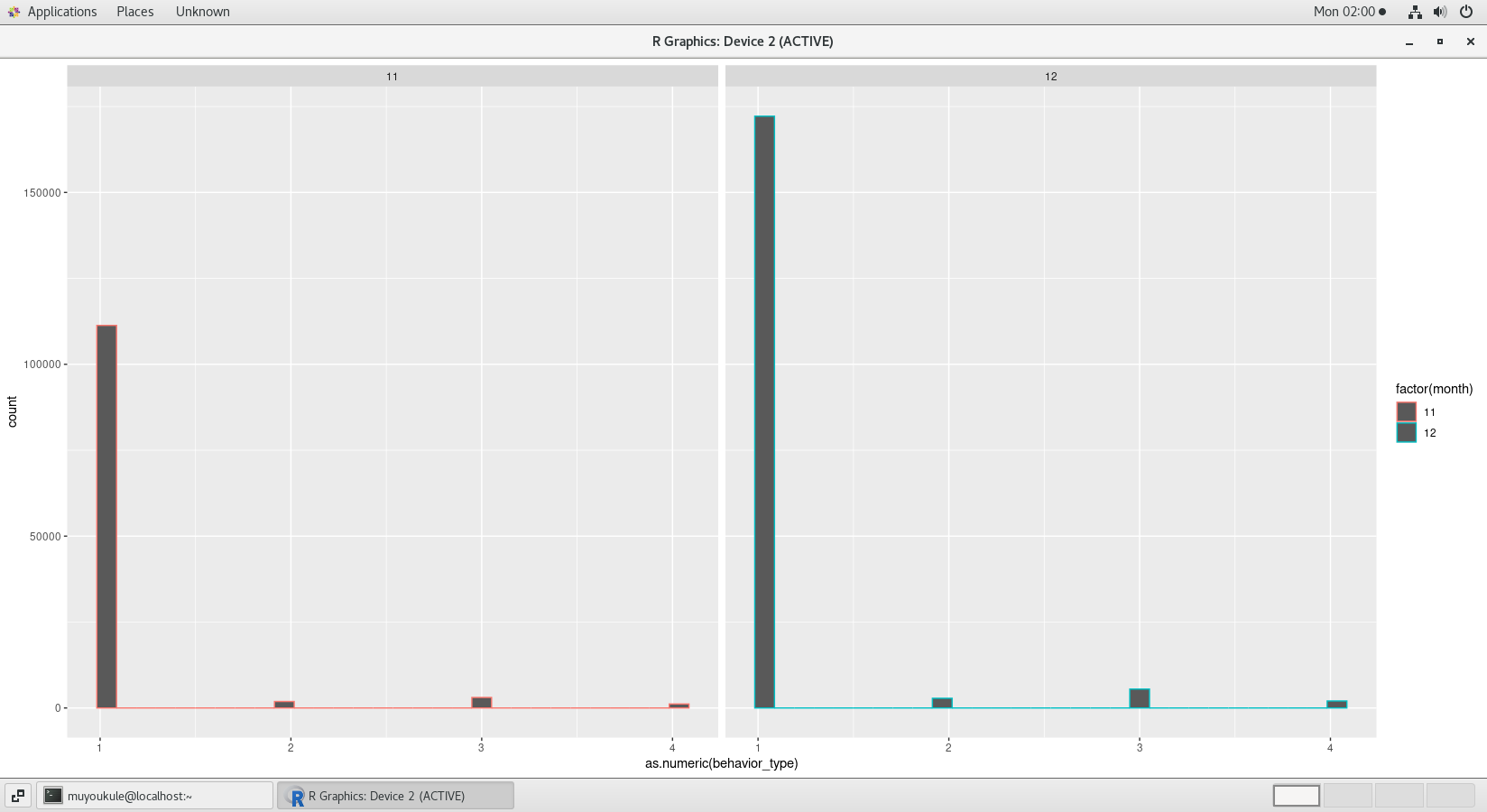
1 | ggplot(user_action,aes(as.numeric(behavior_type),col=factor(month)))+geom_histogram()+facet_grid(.~month) |
aes() 函数中的 col 属性可以用来设置颜色。factor() 函数则是把数值变量转换成分类变量,作用是以不同的颜色表示。如果不使用factor() 函数,颜色将以同一种颜色渐变的颜色表现。 facet_grid(.~month) 表示柱状图按照不同月份进行分区。
由于 MySQL 获取的数据中只有11月份和12月份的数据,所以上图只有显示两个表格。
分析结果如下图:
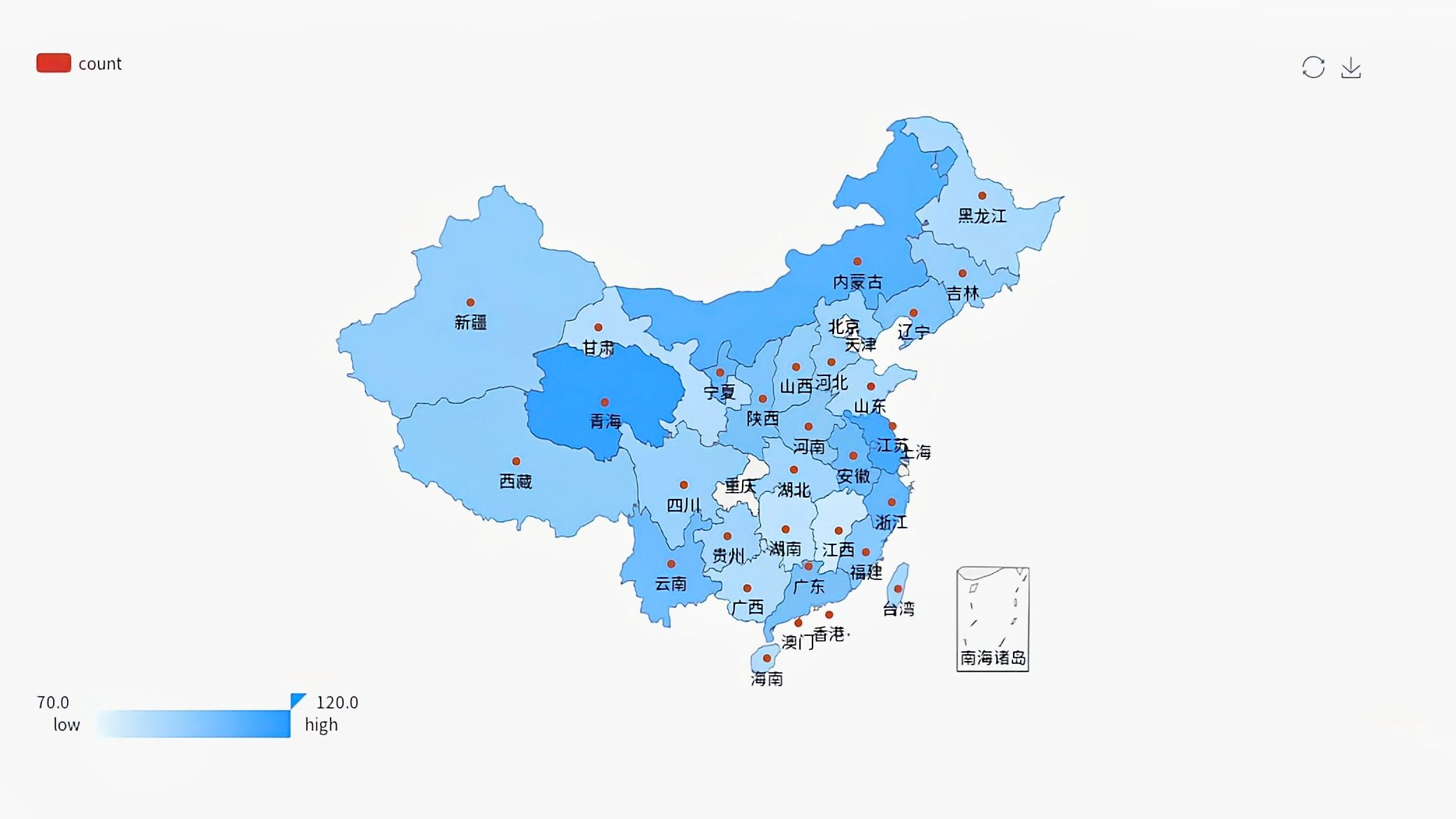
4、分析国内哪个省份的消费者最有购买欲望
1 | library(recharts) |
nrow() 用来计算数据集的行数。
分析结果如下图:
大数据案例网站用户购物行为分析所有实验步骤到此结束!!!!!
大数据案例网站用户购物行为分析所有实验步骤到此结束!!!!!
😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀😀
