写在前面 简介:本文章基于厦门大学提供的大数据课程实验案例:网站用户行为分析 ,通过使用 CentOS 操作编写而来。具体介绍请打开链接进行阅读。
这里介绍几点值得特别注意的事项:
1、对于案例所涉及的系统及软件此文档使用的是以下版本,其他软件版本随意:
Linux系统(CentOS7)
MySQL(5.7)
Hadoop(3.1.3)
HBase(2.2.2,HBase版本需要和Hadoop版本兼容)
Hive(3.1.2,Hive需要和Hadoop版本兼容)
Sqoop(1.4.7)
R(3.6.0)
IDEA( 2023.3.6 社区版)
PS:Hadoop 与 HBase、Hive 版本一定要兼容!!!版本一定要兼容!!!这很重要!!!
2、所有下载 的安装包均在 / 目录下。所有安装 的软件均在 /usr/local/ 目录下以 软件名-版本号 方式命名。在进行每个软件的安装操作之前请先整体阅读 整个软件安装流程的文章有个整体思路,了解到安装此软件需要做哪些设置再进行操作 ,这样可以避免很多不必要的麻烦。
3、此案例分为五个步骤,请按照步骤顺序进行阅读!! 🙂🙂
1. Hive预操作 1、启动 MySQL 数据库
因为需要借助于 MySQL 保存 Hive 的元数据,所以,请首先启动 MySQL 数据库,请在终端中输入下面命令:
1 2 3 4 5 # 查看 MySQL 状态 systemctl status mysqld # 启动 MySQL sudo systemctl start mysqld
2、启动 Hadoop
由于 Hive 是基于 Hadoop 的数据仓库,使用 HiveQL 语言撰写的查询语句,最终都会被 Hive 自动解析成 MapReduce 任务由 Hadoop 去具体执行,因此,需要启动 Hadoop,然后再启动 Hive。
请执行下面命令启动 Hadoop(如果你已经启动了 Hadoop 就不用再次启动了):
1 2 3 4 5 # 启动 Hadoop start-all.sh # 查看当前运行的进程 jps
如果出现下面这些进程,说明Hadoop启动成功了。
1 2 3 4 5 6 NameNode DataNode NodeManager Jps SecondaryNameNode ResourceManager
3、启动进入 Hive:
通过上述过程,我们就完成了 MySQL、Hadoop 和 Hive 三者的启动。启动成功以后,就进入了 hive> 命令提示符状态,可以输入类似SQL 语句的 HiveQL 语句。
然后,在 hive> 命令提示符状态下执行下面命令:
(1) 创建临时表 user_action
1 create table dblab.user_action(id STRING,uid STRING, item_id STRING, behavior_type STRING, item_category STRING, visit_date DATE, province STRING) COMMENT 'Welcome to XMU dblab! ' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
这个命令执行完以后,Hive 会自动在 HDFS 文件系统中创建对应的数据文件/user/hive/warehouse/dblab.db/user_action
1 hdfs dfs -ls /user/hive/warehouse/dblab.db
1 2 drwxr-xr-x - muyoukule supergroup 0 2024-03-24 02:06 /user/hive/warehouse/dblab.db/scan drwxr-xr-x - muyoukule supergroup 0 2024-03-24 02:15 /user/hive/warehouse/dblab.db/user_action
这说明,这个数据文件在 HDFS 中确实被创建了。注意,这个 HDFS 中的数据文件,在我们后面的 “使用 HBase Java API 把数据从本地导入到 HBase 中” 操作中会使用到。
(2) 将 bigdata_user 表中的数据插入到 user_action (执行时间:10秒左右)
在第二个步骤—— Hive 数据分析中,我们已经在 Hive 中的 dblab 数据库中创建了一个外部表 bigdata_user。下面把dblab.bigdata_user 数据插入到 dblab.user_action 表中,命令如下:
1 INSERT OVERWRITE TABLE dblab.user_action select * from dblab.bigdata_user;
请执行下面命令查询上面的插入命令是否成功执行:
1 select * from dblab.user_action limit 10;
1 2 3 4 5 6 7 8 9 10 11 12 OK 1 10001082 285259775 1 4076 2014-12-08 吉林 2 10001082 4368907 1 5503 2014-12-12 贵州 3 10001082 4368907 1 5503 2014-12-12 西藏 4 10001082 53616768 1 9762 2014-12-02 江苏 5 10001082 151466952 1 5232 2014-12-12 青海 6 10001082 53616768 4 9762 2014-12-02 广西 7 10001082 290088061 1 5503 2014-12-12 台湾 8 10001082 298397524 1 10894 2014-12-12 辽宁 9 10001082 32104252 1 6513 2014-12-12 内蒙古 10 10001082 323339743 1 10894 2014-12-12 四川 Time taken: 0.132 seconds, Fetched: 10 row(s)
2. 使用 Sqoop 将数据从 Hive 导入 MySQL 1、启动Hadoop集群、MySQL服务
前面我们已经启动了Hadoop集群和MySQL服务。这里请确认已经按照前面操作启动成功。
2、将前面生成的临时表数据从Hive导入到 MySQL 中,包含如下四个步骤。
(1) 登录 MySQL
请在 Linux 系统中新建一个终端,执行下面命令:
为了简化操作,本教程直接使用 root 用户登录 MySQL 数据库。但是,在实际应用中,建议在 MySQL 中再另外创建一个用户。
执行上面命令以后,就进入了 mysql> 命令提示符状态。
(2) 创建数据库
1 2 3 4 5 6 7 8 #显示所有数据库 show databases; #创建dblab数据库 create database dblab; #使用数据库 use dblab;
PS:请使用下面命令查看数据库的编码:
1 show variables like "char%";
会显示类似下面的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.01 sec)
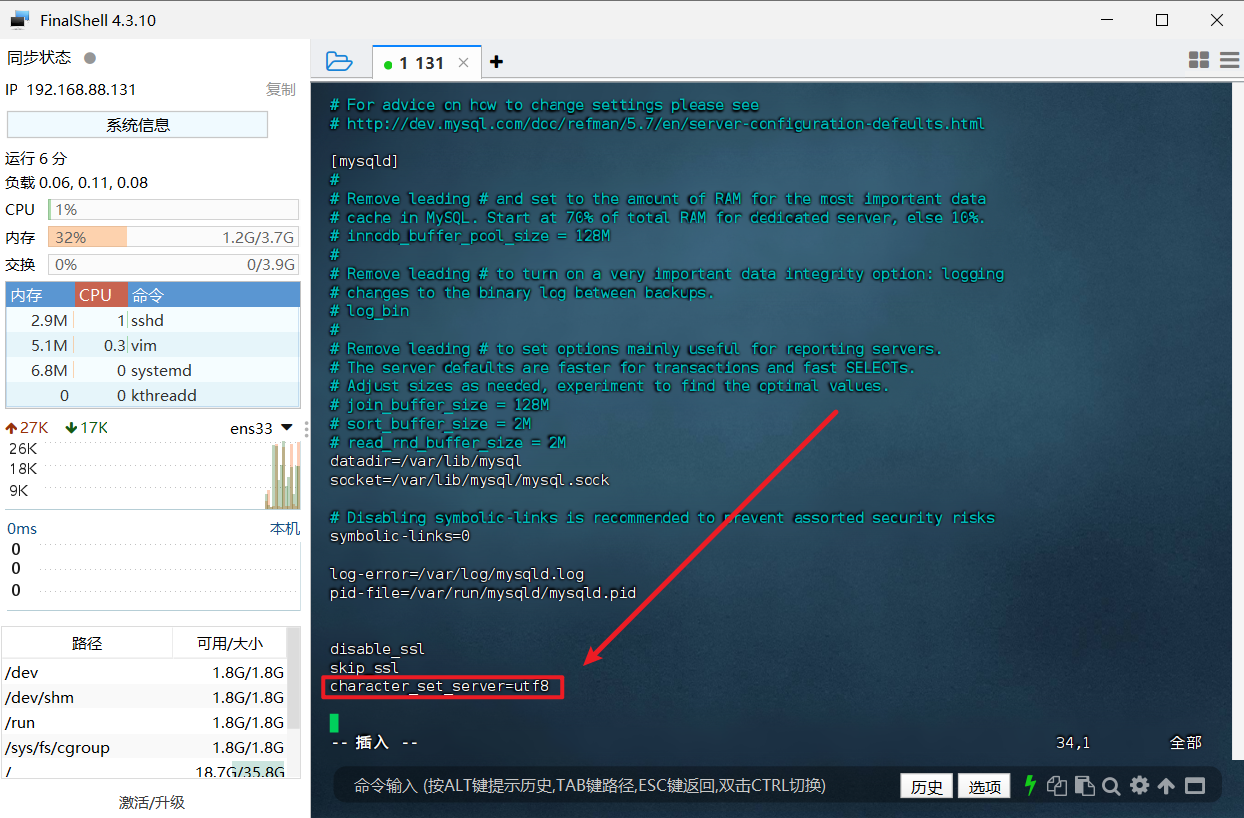
请确认当前编码为 utf8,否则无法导入中文。如果不是 utf8则需要找到自己 MySQL 的配置文件(不同的安装方式对应的配置文件位置不同),yum 方式安装的 MySQL 配置文件所在位置为 /etc/my.cnf 。找到之后使用 vim 编辑器打开:
1 2 # 修改 MySQL 配置文件,目录根据安装时自行查找 sudo vim /etc/my.cnf
打开后在配置文件中添加 character_set_server=utf8:
1 2 # 修改完后重启 MySQL 服务 sudo systemctl restart mysqld
下面是修改了编码格式后的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec)
(3) 创建表
下面在 MySQL 的数据库 dblab 中创建一个新表 user_action,并设置其编码为 utf-8:
1 CREATE TABLE `dblab`.`user_action` (`id` varchar(50),`uid` varchar(50),`item_id` varchar(50),`behavior_type` varchar(10),`item_category` varchar(50), `visit_date` DATE,`province` varchar(20)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
PS:语句中的引号是反引号 ` ,不是单引号 ’
创建成功后,输入下面命令退出 MySQL:
(4) 导入数据(执行时间:20秒左右)
注意,刚才已经退出 MySQL,回到了 Shell 命令提示符状态。下面就可以执行数据导入操作,
1 2 # 导入命令 sqoop export --connect jdbc:mysql://localhost:3306/dblab?useSSL=false --username root --password root --table user_action --export-dir '/user/hive/warehouse/dblab.db/user_action' --fields-terminated-by '\t';
字段解释:
1 2 3 4 5 6 7 sqoop export # 表示数据从 hive 复制到 mysql 中 --connect jdbc:mysql://localhost:3306/dblab --username root # mysql登陆用户名 --password root # 登录密码 --table user_action # mysql 中的表,即将被导入的表名称 --export-dir '/user/hive/warehouse/dblab.db/user_action ' #hive 中被导出的文件 --fields-terminated-by '\t' #Hive 中被导出的文件字段的分隔符
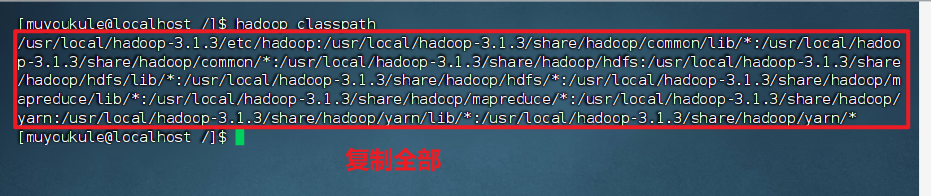
如果出现错误,找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster:
在命令行下输入如下命令,并将返回的内容复制。
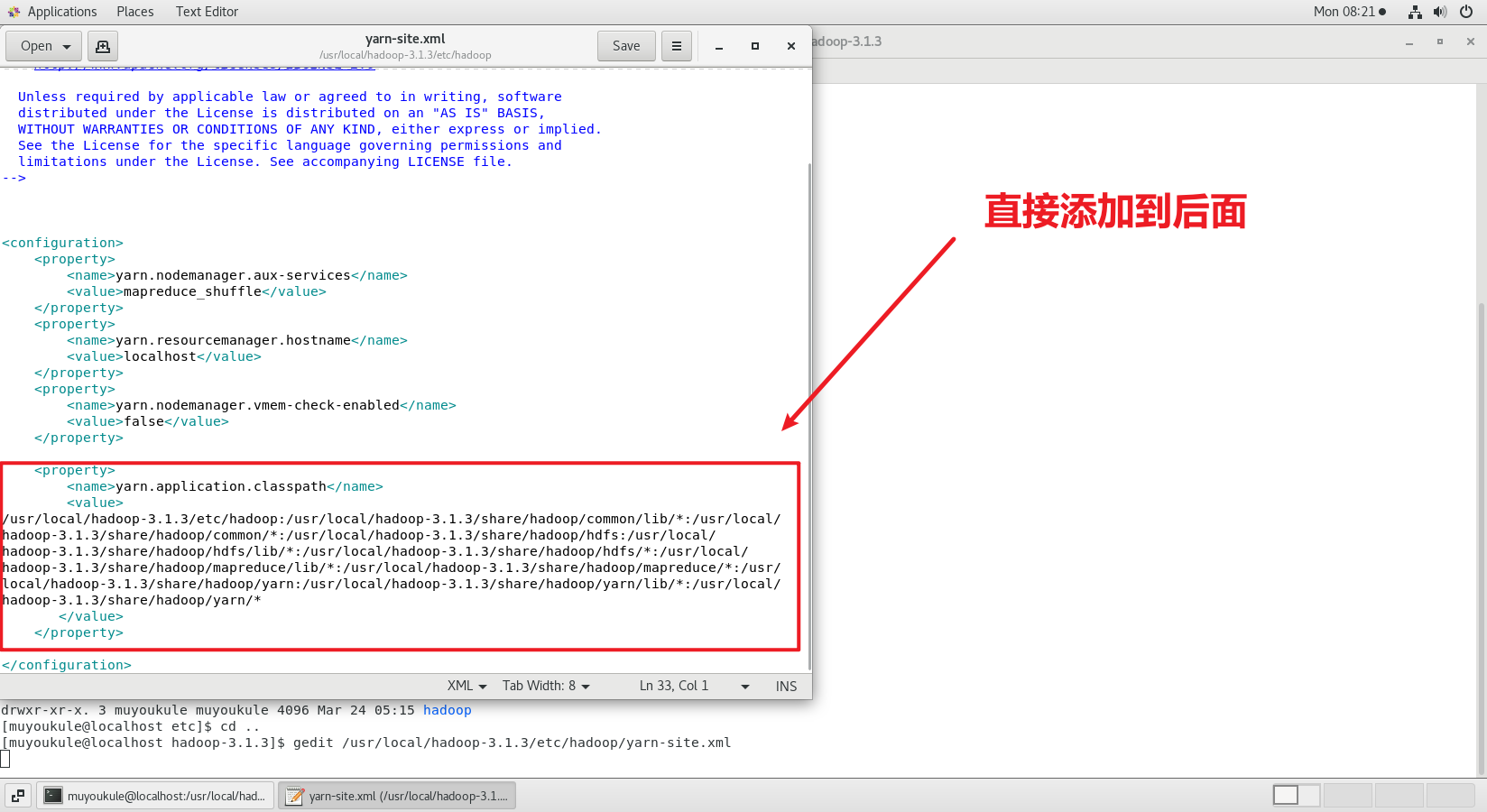
将如上信息全部复制,找到自己安装 Hadoop 的路径打开 yarn-site.xml 文件,在后面添加如下配置:
1 2 # 使用 gedit 编辑器记得直接操作虚拟机 gedit /usr/local/hadoop-3.1.3/etc/hadoop/yarn-site.xml
1 2 3 4 5 6 <configuration > <property > <name > yarn.application.classpath</name > <value > 输入刚才返回的Hadoop classpath路径</value > </property > </configuration >
在所有的 Master 和 Slave 节点进行如上设置,设置完毕后重启 Hadoop 集群,重新运行刚才的 MapReduce 程序,修改后运行成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 2024-03-24 05:18:25,571 INFO mapreduce.Job: Job job_1711280620175_0004 completed successfully 2024-03-24 05:18:25,655 INFO mapreduce.Job: Counters: 32 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=904948 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=15607365 HDFS: Number of bytes written=0 HDFS: Number of read operations=19 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=4 Data-local map tasks=4 Total time spent by all maps in occupied slots (ms)=37647 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=37647 Total vcore-milliseconds taken by all map tasks=37647 Total megabyte-milliseconds taken by all map tasks=38550528 Map-Reduce Framework Map input records=300000 Map output records=300000 Input split bytes=696 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=1097 CPU time spent (ms)=14110 Physical memory (bytes) snapshot=1415909376 Virtual memory (bytes) snapshot=11207258112 Total committed heap usage (bytes)=1074266112 Peak Map Physical memory (bytes)=360275968 Peak Map Virtual memory (bytes)=2806079488 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 2024-03-24 05:18:25,659 INFO mapreduce.ExportJobBase: Transferred 14.8843 MB in 31.3371 seconds (486.3743 KB/sec) 2024-03-24 05:18:25,661 INFO mapreduce.ExportJobBase: Exported 300000 records.
3、查看MySQL中user_action表数据
下面需要再次启动 MySQL,进入 mysql> 命令提示符状态:
会提示你输入 MySQL 的 root 用户的密码,然后执行下面命令查询 user_action 表中的数据:
1 2 use dblab; select * from user_action limit 10;
会得到类似下面的查询结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 +--------+-----------+-----------+---------------+---------------+------------+-----------+ | id | uid | item_id | behavior_type | item_category | visit_date | province | +--------+-----------+-----------+---------------+---------------+------------+-----------+ | 225651 | 102865660 | 237147749 | 1 | 5689 | 2014-12-04 | 黑龙江 | | 225652 | 102865660 | 395294600 | 1 | 3099 | 2014-12-11 | 山西 | | 225653 | 102865660 | 164310319 | 1 | 5027 | 2014-12-08 | 江苏 | | 225654 | 102865660 | 72511722 | 1 | 1121 | 2014-12-13 | 西藏 | | 225655 | 102865660 | 334372932 | 1 | 5027 | 2014-11-30 | 甘肃 | | 225656 | 102865660 | 323237439 | 1 | 5027 | 2014-12-02 | 广东 | | 225657 | 102865660 | 323237439 | 1 | 5027 | 2014-12-07 | 重庆市 | | 225658 | 102865660 | 34102362 | 1 | 1863 | 2014-12-13 | 宁夏 | | 225659 | 102865660 | 373499226 | 1 | 12388 | 2014-11-26 | 黑龙江 | | 225660 | 102865660 | 271583890 | 1 | 5027 | 2014-12-06 | 福建 | +--------+-----------+-----------+---------------+---------------+------------+-----------+ 10 rows in set (0.00 sec)
从Hive导入数据到MySQL中,成功!
3. 使用 Sqoop 将数据从 MySQL 导入 HBase 1、启动 Hadoop 集群、MySQL 服务、HBase 服务
之前我们已经启动了 Hadoop 集群、MySQL 服务,这里请确认已经按照前面操作启动成功。这里我们再启动 HBase 服务。本教程中,HBase的安装目录是 /usr/local/hbase-2.2.2,而且本教程中,HBase 配置为使用 HDFS 存储数据。
请新建一个终端,执行下面命令:
1 2 3 4 5 6 7 8 9 HRegionServer Jps ResourceManager NameNode SecondaryNameNode NodeManager DataNode HQuorumPeer HMaster
2、启动 HBase shell
启动成功后,就进入了 hbase> 命令提示符状态。
3、创建表 user_action
1 create 'user_action', { NAME => 'f1', VERSIONS => 5}
上面命令在 HBase 中创建了一个 user_action 表,这个表中有一个列族 f1(你愿意把列族名称取为其他名称也可以,比如列族名称为userinfo ),历史版本保留数量为 5 。
4、导入数据(执行时间:30秒左右)
下面新建一个终端,执行下面命令导入数据:
1 sqoop import --connect jdbc:mysql://localhost:3306/dblab?useSSL=false --username root --password root --table user_action --hbase-table user_action --column-family f1 --hbase-row-key id --hbase-create-table -m 1
PS:IP部分改为本机IP地址或localhost。同时,HBase只支持十六进制存储中文。
命令解释如下:
1 2 3 4 5 6 7 8 9 sqoop import --connect jdbc:mysql://localhost:3306/dblab --username root --password root --table user_action --hbase-table user_action #HBase中表名称 --column-family f1 #列簇名称 --hbase-row-key id #HBase 行键 --hbase-create-table #是否在不存在情况下创建表 -m 1 #启动 Map 数量
如果出现 Exception in thread “main“ java.lang.NoSuchMethodError: org.apache.hadoop.hbase.client.HBaseAdmin. 的错误:根据报错信息提示,HBase 中没有对应的方法执行语句。查看错误,因为对应 HBase 版本太高导致。
解决方法:根据链接下载 HBase1.6 版本 ,本地解压,将 lib 文件夹中所有 jar 包上传至虚拟机 $SQOOP_HOME/lib 文件夹中。
修改后再执行上面的 sqoop import 命令以后,会得到类似下面的结果(省略了很多非重要的屏幕信息):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=277341 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=0 HDFS: Number of read operations=1 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=13618 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=13618 Total vcore-milliseconds taken by all map tasks=13618 Total megabyte-milliseconds taken by all map tasks=13944832 Map-Reduce Framework Map input records=300000 Map output records=300000 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=217 CPU time spent (ms)=8620 Physical memory (bytes) snapshot=425291776 Virtual memory (bytes) snapshot=2816741376 Total committed heap usage (bytes)=321388544 Peak Map Physical memory (bytes)=425291776 Peak Map Virtual memory (bytes)=2816741376 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 2024-03-24 07:06:38,422 INFO mapreduce.ImportJobBase: Transferred 0 bytes in 69.6995 seconds (0 bytes/sec) 2024-03-24 07:06:38,425 INFO mapreduce.ImportJobBase: Retrieved 300000 records.
5、查看 HBase 中 user_action 表数据
现在,再次切换到 HBase Shell 运行的那个终端窗口,在 hbase> 命令提示符下,执行下面命令查询刚才导入的数据:
1 2 # 只查询前面10行 scan 'user_action',{LIMIT=>10}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 ROW COLUMN+CELL 1 column=f1:behavior_type, timestamp=1711289186613, value=1 1 column=f1:item_category, timestamp=1711289186613, value=4076 1 column=f1:item_id, timestamp=1711289186613, value=285259775 1 column=f1:province, timestamp=1711289186613, value=\xE6\xB1\x9F\xE8\xA5\xBF 1 column=f1:uid, timestamp=1711289186613, value=10001082 1 column=f1:visit_date, timestamp=1711289186613, value=2014-12-08 10 column=f1:behavior_type, timestamp=1711289186613, value=1 10 column=f1:item_category, timestamp=1711289186613, value=10894 10 column=f1:item_id, timestamp=1711289186613, value=323339743 10 column=f1:province, timestamp=1711289186613, value=\xE6\xB5\x99\xE6\xB1\x9F 10 column=f1:uid, timestamp=1711289186613, value=10001082 10 column=f1:visit_date, timestamp=1711289186613, value=2014-12-12 100 column=f1:behavior_type, timestamp=1711289186613, value=1 100 column=f1:item_category, timestamp=1711289186613, value=10576 100 column=f1:item_id, timestamp=1711289186613, value=275221686 100 column=f1:province, timestamp=1711289186613, value=\xE9\xBB\x91\xE9\xBE\x99\xE6 \xB1\x9F 100 column=f1:uid, timestamp=1711289186613, value=10001082 100 column=f1:visit_date, timestamp=1711289186613, value=2014-12-02 1000 column=f1:behavior_type, timestamp=1711289186910, value=1 1000 column=f1:item_category, timestamp=1711289186910, value=3381 1000 column=f1:item_id, timestamp=1711289186910, value=168463559 1000 column=f1:province, timestamp=1711289186910, value=\xE9\xA6\x99\xE6\xB8\xAF 1000 column=f1:uid, timestamp=1711289186910, value=100068031 1000 column=f1:visit_date, timestamp=1711289186910, value=2014-12-02 10000 column=f1:behavior_type, timestamp=1711289188323, value=1 10000 column=f1:item_category, timestamp=1711289188323, value=12488 10000 column=f1:item_id, timestamp=1711289188323, value=45571867 10000 column=f1:province, timestamp=1711289188323, value=\xE6\x96\xB0\xE7\x96\x86 10000 column=f1:uid, timestamp=1711289188323, value=100198255 10000 column=f1:visit_date, timestamp=1711289188323, value=2014-12-05 100000 column=f1:behavior_type, timestamp=1711289190040, value=1 100000 column=f1:item_category, timestamp=1711289190040, value=6580 100000 column=f1:item_id, timestamp=1711289190040, value=78973192 100000 column=f1:province, timestamp=1711289190040, value=\xE5\xA4\xA9\xE6\xB4\xA5\xE5 \xB8\x82 100000 column=f1:uid, timestamp=1711289190040, value=101480065 100000 column=f1:visit_date, timestamp=1711289190040, value=2014-11-29 100001 column=f1:behavior_type, timestamp=1711289190040, value=1 100001 column=f1:item_category, timestamp=1711289190040, value=3472 100001 column=f1:item_id, timestamp=1711289190040, value=34929314 100001 column=f1:province, timestamp=1711289190040, value=\xE5\xB9\xBF\xE8\xA5\xBF 100001 column=f1:uid, timestamp=1711289190040, value=101480065 100001 column=f1:visit_date, timestamp=1711289190040, value=2014-12-15 100002 column=f1:behavior_type, timestamp=1711289190040, value=1 100002 column=f1:item_category, timestamp=1711289190040, value=10392 100002 column=f1:item_id, timestamp=1711289190040, value=401104894 100002 column=f1:province, timestamp=1711289190040, value=\xE5\x8C\x97\xE4\xBA\xAC\xE5 \xB8\x82 100002 column=f1:uid, timestamp=1711289190040, value=101480065 100002 column=f1:visit_date, timestamp=1711289190040, value=2014-11-29 100003 column=f1:behavior_type, timestamp=1711289190040, value=1 100003 column=f1:item_category, timestamp=1711289190040, value=5894 100003 column=f1:item_id, timestamp=1711289190040, value=217913901 100003 column=f1:province, timestamp=1711289190040, value=\xE7\x94\x98\xE8\x82\x83 100003 column=f1:uid, timestamp=1711289190040, value=101480065 100003 column=f1:visit_date, timestamp=1711289190040, value=2014-12-04 100004 column=f1:behavior_type, timestamp=1711289190040, value=1 100004 column=f1:item_category, timestamp=1711289190040, value=12189 100004 column=f1:item_id, timestamp=1711289190040, value=295053167 100004 column=f1:province, timestamp=1711289190040, value=\xE6\xB9\x96\xE5\x8C\x97 100004 column=f1:uid, timestamp=1711289190040, value=101480065 100004 column=f1:visit_date, timestamp=1711289190040, value=2014-11-26 10 row(s) Took 0.3723 seconds
注意,我们用 limit10 是返回 HBase 表中的前面10行数据,但是,上面的结果,从 “行数” 来看,给人一种错误,似乎不是10行,要远远多于10行。这是因为,HBase 在显示数据的时候,和关系型数据库 MySQL 是不同的,每行显示的不是一行记录,而是一个 “单元格”。
4. 使用HBase Java API把数据从本地导入到HBase中 1、启动 Hadoop 集群、HBase 服务
请首先确保启动了 Hadoop 集群和 HBase 服务。如果还没有启动,请在Linux 系统中打开一个终端。
首先,按照下面命令启动 Hadoop、HBase:
1 2 3 4 5 # 启动 Hadoop start-all.sh # 启动 HBase start-hbase.sh
2、数据准备
实际上,我们也可以编写 Java 程序,直接从 HDFS 中读取数据加载到 HBase。但是,这里我们展示的是如何用 JAVA 程序把本地数据导入到 HBase 中。你只要把程序做简单修改,就可以实现从 HDFS 中读取数据加载到 HBase。
首先,请将之前的 user_action 数据从 HDFS 复制到 Linux 系统的本地文件系统中,命令如下:
1 2 3 4 5 6 7 cd /usr/local/bigdatacase/dataset # 将 HDFS 上的 user_action 数据复制到本地当前目录,注意'.' 表示当前目录 hdfs dfs -get /user/hive/warehouse/dblab.db/user_action . # 查看前 10 行数据 cat ./user_action/* | head -10
结果:
1 2 3 4 5 6 7 8 9 10 1 10001082 285259775 1 4076 2014-12-08 江西 2 10001082 4368907 1 5503 2014-12-12 西藏 3 10001082 4368907 1 5503 2014-12-12 贵州 4 10001082 53616768 1 9762 2014-12-02 广西 5 10001082 151466952 1 5232 2014-12-12 陕西 6 10001082 53616768 4 9762 2014-12-02 河南 7 10001082 290088061 1 5503 2014-12-12 重庆市 8 10001082 298397524 1 10894 2014-12-12 云南 9 10001082 32104252 1 6513 2014-12-12 安徽 10 10001082 323339743 1 10894 2014-12-12 浙江
1 2 3 4 5 # 将00000*文件复制一份重命名为user_action.output,*表示通配符 cat ./user_action/00000* > user_action.output # 查看user_action.output前10行 head user_action.output
1 2 3 4 5 6 7 8 9 10 1 10001082 285259775 1 4076 2014-12-08 江西 2 10001082 4368907 1 5503 2014-12-12 西藏 3 10001082 4368907 1 5503 2014-12-12 贵州 4 10001082 53616768 1 9762 2014-12-02 广西 5 10001082 151466952 1 5232 2014-12-12 陕西 6 10001082 53616768 4 9762 2014-12-02 河南 7 10001082 290088061 1 5503 2014-12-12 重庆市 8 10001082 298397524 1 10894 2014-12-12 云南 9 10001082 32104252 1 6513 2014-12-12 安徽 10 10001082 323339743 1 10894 2014-12-12 浙江
3、编写数据导入程序
这里采用 IDEA 编写 Java 程序实现 HBase 数据导入功能。
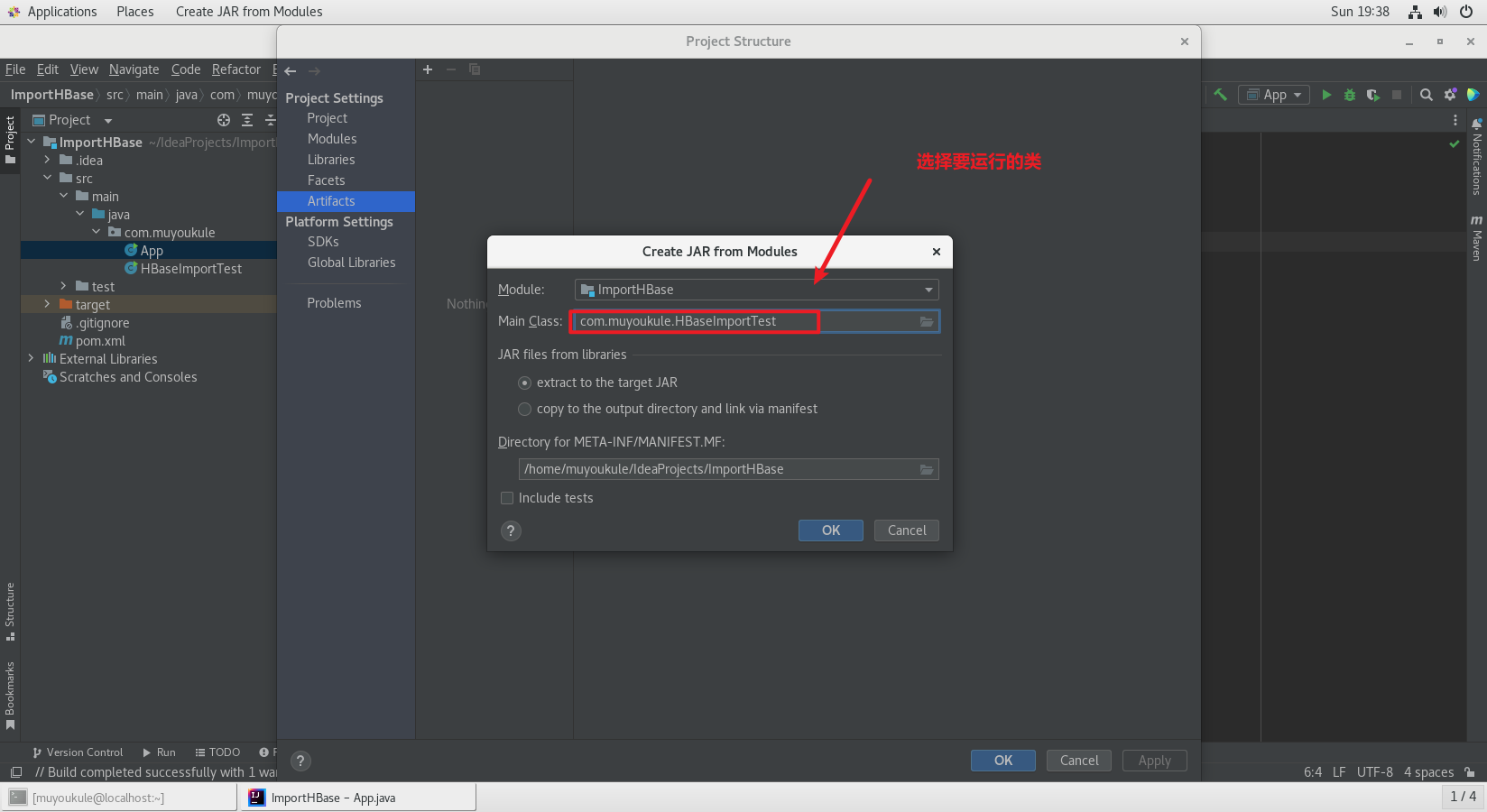
请使用 IDEA 编写 ImportHBase 程序( Java 代码在本文最后的附录部分),并打包成可执行 jar 包,命名为 ImportHBase.jar。
然后,请在 /usr/local/bigdatacase/ 目录下面新建一个 hbase 子目录,用来存放 ImportHBase.jar。
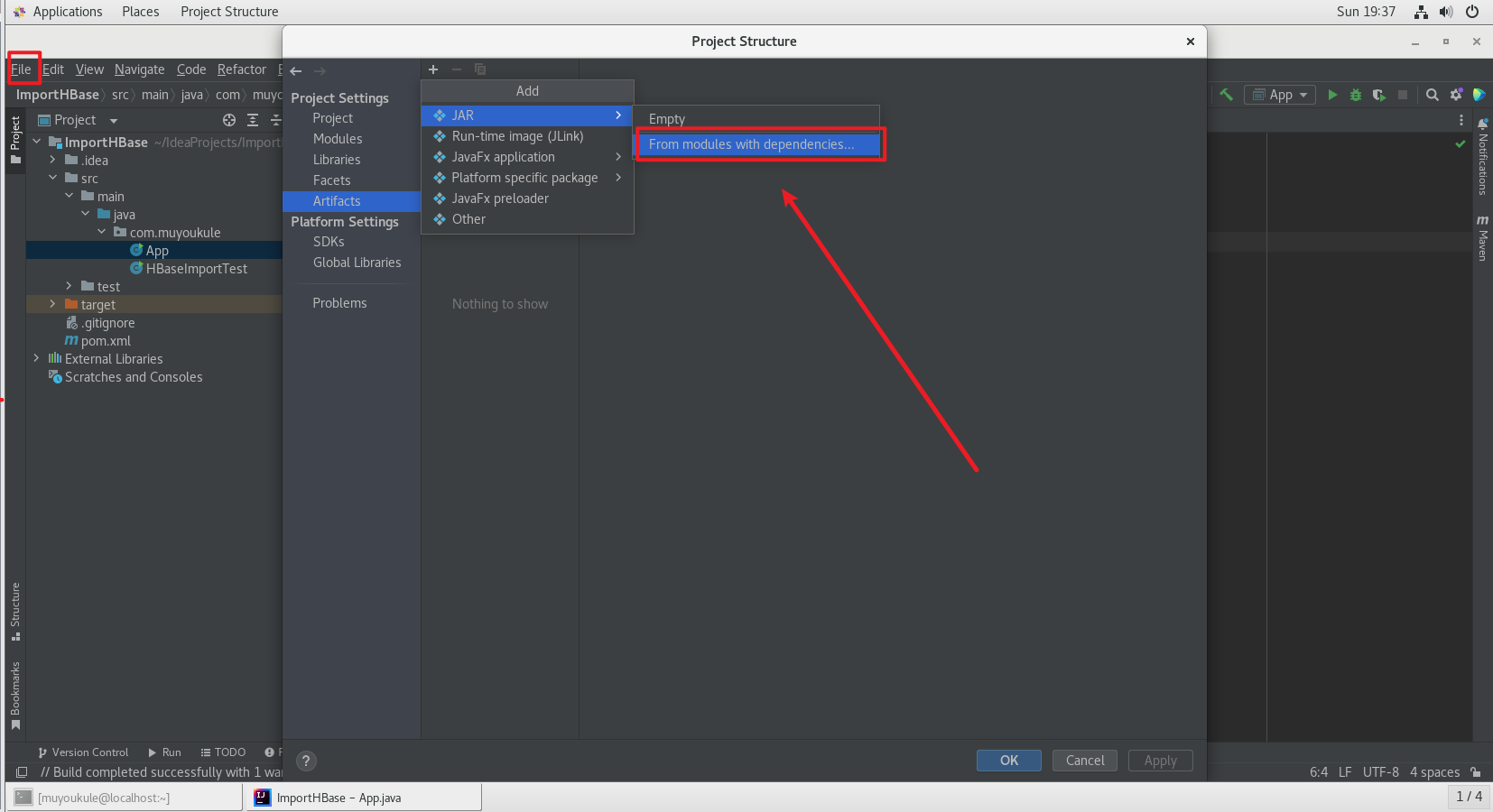
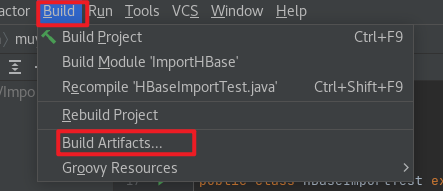
IEDA 打包成可执行 jar 包:
左上角 File –> Project Structure 打开如下界面,点击 Artifacts –> From moudles with dependencies ,然后依次操作:
然后就可以在设置的 jar 包输出路径下找到对应 jar 包。
4、数据导入
使用 Java 程序将数据从本地导入 HBase 中,导入前,请先清空 user_action 表。
请在之前已经打开的 HBase Shel l窗口中(也就是在 hbase> 命令提示符下)执行下面操作:
1 2 3 4 Truncating 'user_action' table (it may take a while): Disabling table... Truncating table... Took 2.3970 seconds
1 2 # 删除以后再查看就没有记录了 scan 'user_action',{LIMIT=>10}
1 2 3 ROW COLUMN+CELL 0 row(s) Took 0.0542 seconds
下面就可以运行 hadoop jar 命令运行程序:
1 hadoop jar /usr/local/bigdatacase/hbase/ImportHBase.jar HBaseImportTest /usr/local/bigdatacase/dataset/user_action.output
命令解释如下:
1 2 3 4 /usr/local/hadoop/bin/hadoop jar #hadoop jar包执行方式 /usr/local/bigdatacase/hbase/ImportHBase.jar #jar包的路径 HBaseImportTest #主函数入口 /usr/local/bigdatacase/dataset/user_action.output #main方法接收的参数args,用来指定输入文件的路径
这个命令大概会执行3分钟左右,执行过程中,屏幕上会打印出执行进度,每执行1万条,对打印出一行信息,所以,整个执行过程屏幕上显示如下信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 10000 20000 30000 40000 50000 60000 70000 80000 90000 100000 110000 120000 130000 140000 150000 160000 170000 180000 190000 200000 210000 220000 230000 240000 250000 260000 270000 280000 290000 300000 Total Time: 140506 ms
5、查看 HBase 中 user_action 表数据
下面,再次切换到 HBase Shell 窗口,执行下面命令查询数据:
1 2 # 只查询前面10行 scan 'user_action',{LIMIT=>10}
就可以得到类似下面的查询结果了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 ROW COLUMN+CELL 1 column=f1:behavior_type, timestamp=1711334492967, value=1 1 column=f1:date, timestamp=1711334492967, value=2014-12-08 1 column=f1:item_category, timestamp=1711334492967, value=4076 1 column=f1:item_id, timestamp=1711334492967, value=285259775 1 column=f1:province, timestamp=1711334492967, value=\xE6\xB1\x9F\xE8\xA5\xBF 1 column=f1:uid, timestamp=1711334492967, value=10001082 10 column=f1:behavior_type, timestamp=1711334493000, value=1 10 column=f1:date, timestamp=1711334493000, value=2014-12-12 10 column=f1:item_category, timestamp=1711334493000, value=10894 10 column=f1:item_id, timestamp=1711334493000, value=323339743 10 column=f1:province, timestamp=1711334493000, value=\xE6\xB5\x99\xE6\xB1\x9F 10 column=f1:uid, timestamp=1711334493000, value=10001082 100 column=f1:behavior_type, timestamp=1711334493295, value=1 100 column=f1:date, timestamp=1711334493295, value=2014-12-02 100 column=f1:item_category, timestamp=1711334493295, value=10576 100 column=f1:item_id, timestamp=1711334493295, value=275221686 100 column=f1:province, timestamp=1711334493295, value=\xE9\xBB\x91\xE9\xBE\x99\xE6\xB1\x9F 100 column=f1:uid, timestamp=1711334493295, value=10001082 1000 column=f1:behavior_type, timestamp=1711334494583, value=1 1000 column=f1:date, timestamp=1711334494583, value=2014-12-02 1000 column=f1:item_category, timestamp=1711334494583, value=3381 1000 column=f1:item_id, timestamp=1711334494583, value=168463559 1000 column=f1:province, timestamp=1711334494583, value=\xE9\xA6\x99\xE6\xB8\xAF 1000 column=f1:uid, timestamp=1711334494583, value=100068031 10000 column=f1:behavior_type, timestamp=1711334500210, value=1 10000 column=f1:date, timestamp=1711334500210, value=2014-12-05 10000 column=f1:item_category, timestamp=1711334500210, value=12488 10000 column=f1:item_id, timestamp=1711334500210, value=45571867 10000 column=f1:province, timestamp=1711334500210, value=\xE6\x96\xB0\xE7\x96\x86 10000 column=f1:uid, timestamp=1711334500210, value=100198255 100000 column=f1:behavior_type, timestamp=1711334543592, value=1 100000 column=f1:date, timestamp=1711334543592, value=2014-11-29 100000 column=f1:item_category, timestamp=1711334543592, value=6580 100000 column=f1:item_id, timestamp=1711334543592, value=78973192 100000 column=f1:province, timestamp=1711334543592, value=\xE5\xA4\xA9\xE6\xB4\xA5\xE5\xB8\x82 100000 column=f1:uid, timestamp=1711334543592, value=101480065 100001 column=f1:behavior_type, timestamp=1711334543592, value=1 100001 column=f1:date, timestamp=1711334543592, value=2014-12-15 100001 column=f1:item_category, timestamp=1711334543592, value=3472 100001 column=f1:item_id, timestamp=1711334543592, value=34929314 100001 column=f1:province, timestamp=1711334543592, value=\xE5\xB9\xBF\xE8\xA5\xBF 100001 column=f1:uid, timestamp=1711334543592, value=101480065 100002 column=f1:behavior_type, timestamp=1711334543593, value=1 100002 column=f1:date, timestamp=1711334543593, value=2014-11-29 100002 column=f1:item_category, timestamp=1711334543593, value=10392 100002 column=f1:item_id, timestamp=1711334543593, value=401104894 100002 column=f1:province, timestamp=1711334543593, value=\xE5\x8C\x97\xE4\xBA\xAC\xE5\xB8\x82 100002 column=f1:uid, timestamp=1711334543593, value=101480065 100003 column=f1:behavior_type, timestamp=1711334543593, value=1 100003 column=f1:date, timestamp=1711334543593, value=2014-12-04 100003 column=f1:item_category, timestamp=1711334543593, value=5894 100003 column=f1:item_id, timestamp=1711334543593, value=217913901 100003 column=f1:province, timestamp=1711334543593, value=\xE7\x94\x98\xE8\x82\x83 100003 column=f1:uid, timestamp=1711334543593, value=101480065 100004 column=f1:behavior_type, timestamp=1711334543593, value=1 100004 column=f1:date, timestamp=1711334543593, value=2014-11-26 100004 column=f1:item_category, timestamp=1711334543593, value=12189 100004 column=f1:item_id, timestamp=1711334543593, value=295053167 100004 column=f1:province, timestamp=1711334543593, value=\xE6\xB9\x96\xE5\x8C\x97 100004 column=f1:uid, timestamp=1711334543593, value=101480065 10 row(s) Took 0.2652 seconds
实验顺利结束!
附录:ImportHBase.java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 package com.muyoukule;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.util.Bytes;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.nio.file.Files;import java.nio.file.Paths;import java.util.List;public class HBaseImportTest extends Thread { public Configuration config; public Table table; public HBaseAdmin admin; Connection connection = ConnectionFactory.createConnection(); public HBaseImportTest () throws IOException { config = HBaseConfiguration.create(); try { table = connection.getTable(TableName.valueOf("user_action" )); connection = ConnectionFactory.createConnection(config); admin = (HBaseAdmin) connection.getAdmin(); } catch (IOException e) { e.printStackTrace(); } } public static void main (String[] args) throws Exception { if (args.length == 0 ) { throw new Exception ("You must set input path!" ); } String fileName = args[args.length - 1 ]; HBaseImportTest test = new HBaseImportTest (); test.importLocalFileToHBase(fileName); } public void importLocalFileToHBase (String fileName) { long st = System.currentTimeMillis(); BufferedReader br = null ; try { br = new BufferedReader (new InputStreamReader (Files.newInputStream(Paths.get(fileName)))); String line = null ; int count = 0 ; while ((line = br.readLine()) != null ) { count++; put(line); if (count % 10000 == 0 ) System.out.println(count); } } catch (IOException e) { e.printStackTrace(); } finally { if (br != null ) { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } try { table.close(); } catch (IOException e) { e.printStackTrace(); } } long en2 = System.currentTimeMillis(); System.out.println("Total Time: " + (en2 - st) + " ms" ); } @SuppressWarnings("deprecation") public void put (String line) throws IOException { String[] arr = line.split("\t" , -1 ); String[] column = {"id" , "uid" , "item_id" , "behavior_type" , "item_category" , "date" , "province" }; if (arr.length == 7 ) { Put put = new Put (Bytes.toBytes(arr[0 ])); for (int i = 1 ; i < arr.length; i++) { put.addColumn(Bytes.toBytes("f1" ), Bytes.toBytes(column[i]), Bytes.toBytes(arr[i])); } table.put(put); } } public void get (String rowkey, String columnFamily, String column, int versions) throws IOException { long st = System.currentTimeMillis(); Get get = new Get (Bytes.toBytes(rowkey)); get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column)); Scan scanner = new Scan (get); scanner.setMaxVersions(versions); ResultScanner rsScanner = table.getScanner(scanner); for (Result result : rsScanner) { final List<Cell> list = result.listCells(); for (final Cell kv : list) { System.out.println(Bytes.toStringBinary(kv.getValueArray()) + "\t" + kv.getTimestamp()); } } rsScanner.close(); long en2 = System.currentTimeMillis(); System.out.println("Total Time: " + (en2 - st) + " ms" ); } }