MyBatis-Plus官网 1 :https://baomidou.com/
MyBatis-Plus官网 2:https://mybatis.plus/
1. MyBatis-Plus 概述 1.1 为什么要学? MyBatis-Plus只需简单配置即可快速进行单表 CRUD 操作,简单的 CRUD 操作不再需要我们书写。(肯定不是因为这个)
MyBatis-Plus 由国人开发,文档很详细易上手,编码符合国人习惯,并且已连续 5 年(2017、2018 、2019、2020、2021)获得”OSC 年度最受欢迎中国开源软件”殊荣。最最最重要的是官方为我们提供了自动生成代码的代码生成器…真的是太贴心了!!🤩这不就相当于是别人都把饭喂你嘴里了吗?你还有什么理由不吃呢?😂
PS:本文中,MP 是 MyBatis-Plus 的简写。
1.2 简介 MyBatis-Plus (简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
从这张图中我们可以看出 MP 旨在成为 MyBatis 的最好搭档,而不是替换 MyBatis ,所以可以理解为 MP 是 MyBatis 的一套增强工具,它是在 MyBatis 的基础上进行开发的,我们虽然使用 MP 但是底层依然是 MyBatis 的东西,也就是说我们也可以在 MP 中写 MyBatis 的内容。
PS:使用 MP 可以节省代码的编写,尽量 不要同时 导入 MP 和 MyBatis,避免存在依赖错误。
1.3 特性
无侵入 :只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑损耗小 :启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作强大的 CRUD 操作 :内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求( 言外之意,简单的 CRUD 操作不再需要我们书写 )支持 Lambda 形式调用 :通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错支持主键自动生成 :支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题支持 ActiveRecord 模式 :支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作支持自定义全局通用操作 :支持全局通用方法注入( Write once, use anywhere )内置代码生成器 :采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用内置分页插件 :基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询分页插件支持多种数据库 :支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库内置性能分析插件 :可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询内置全局拦截插件 :提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
2. 快速开始 接下来将通过一个简单的 Demo 来阐述 MP 的强大功能,在此之前,假设你已经:
拥有 Java 开发环境以及相应 IDE
熟悉 Spring Boot
熟悉 Maven
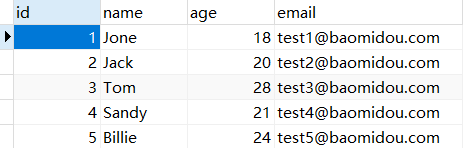
2.1 环境准备 现有一张 User 表,其表结构如下:
步骤
1、创建一个数据库 mybatis_plus
2、创建 user 表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 DROP TABLE IF EXISTS `user `;CREATE TABLE `user `( id BIGINT NOT NULL COMMENT '主键ID' , name VARCHAR (30 ) NULL DEFAULT NULL COMMENT '姓名' , age INT NULL DEFAULT NULL COMMENT '年龄' , email VARCHAR (50 ) NULL DEFAULT NULL COMMENT '邮箱' , PRIMARY KEY (id) ); DELETE FROM `user `;INSERT INTO `user ` (id, name, age, email) VALUES (1 , 'Jone' , 18 , 'test1@baomidou.com' ), (2 , 'Jack' , 20 , 'test2@baomidou.com' ), (3 , 'Tom' , 28 , 'test3@baomidou.com' ), (4 , 'Sandy' , 21 , 'test4@baomidou.com' ), (5 , 'Billie' , 24 , 'test5@baomidou.com' );
3、使用 IDEA 初始化一个 SpringBoot 项目 mybatis_plus,选择 Spring Web 和 Lombok 依赖进行导入。
4、导入其他依赖
由于这个 mybatis-plus-boot-starter 包含对 Mybatis 的自动装配,因此完全可以替换掉 Mybatis 的 starter 。
1 2 3 4 5 6 7 8 9 10 11 12 <dependency > <groupId > com.mysql</groupId > <artifactId > mysql-connector-j</artifactId > <version > 8.0.31</version > </dependency > <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-boot-starter</artifactId > <version > 3.5.3.1</version > </dependency >
PS:注意 SpringBoot 版本要与 Mybatis-Plus 版本相对应。
5、编写配置文件 application.yml 连接数据库
1 2 3 4 5 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/mybatis_plus?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true username: root password: root
6、编写实体类 User.java (此处使用了 Lombok 简化代码)
1 2 3 4 5 6 7 8 9 10 @Data @NoArgsConstructor @AllArgsConstructor @TableName("`user`") public class User { private Long id; private String name; private Integer age; private String email; }
7、编写 Mapper 包下的 UserMapper接口
1 2 public interface UserMapper extends BaseMapper <User> {}
8、在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:
1 2 3 4 5 6 7 8 @SpringBootApplication @MapperScan("com.muyoukule.mapper") public class MybatisPlusApplication { public static void main (String[] args) { SpringApplication.run(MybatisPlusApplication.class, args); } }
2.2 标准CRUD使用 对于标准的 CRUD 功能 MP 都提供了哪些方法可以使用呢?
新增 Insert
在测试类中进行新增操作:
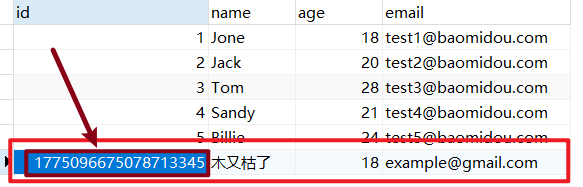
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @SpringBootTest class MybatisPlusApplicationTests { @Autowired private UserMapper userMapper; @Test void testSave () { User user = new User (); user.setName("木又枯了" ); user.setAge(18 ); user.setEmail("example@gmail.com" ); int i = userMapper.insert(user); System.out.println(i); } }
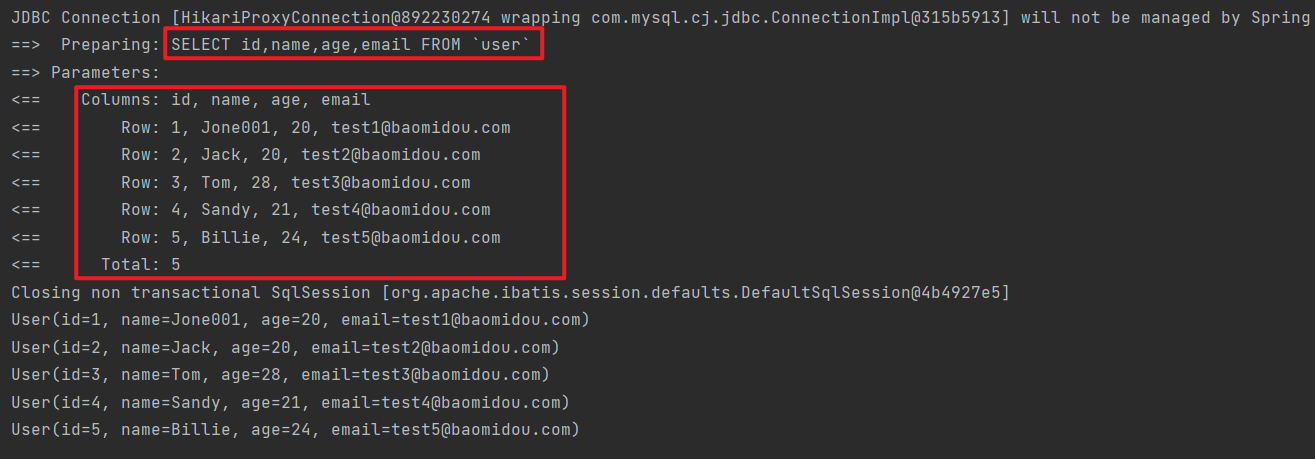
控制台结果:
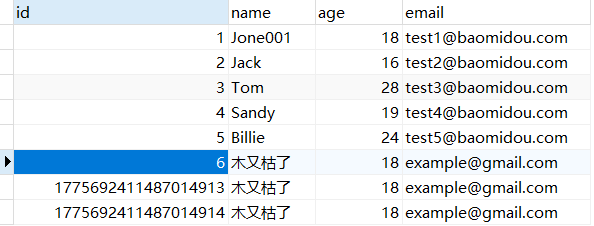
说明数据插入成功,这时候到数据库中查看,数据库表中就会添加一条数据:
但是我们发现:我们明明没有设置 ID,插入时居然自动生成了 ID,而且生成的 ID 似乎有点 “ 奇怪 ”。那这个主键 ID 是如何来的?我们更想要的是主键自增,应该是 6 才对,这个是我们后面要学习的 主键生成策略 ,这块的这个问题,我们暂时先放放。
删除 Delete
1 int deleteById (Serializable id)
Serializable:参数类型
int:返回值类型,数据删除成功返回 1,未删除数据返回 0
思考:参数类型为什么是一个序列化类?
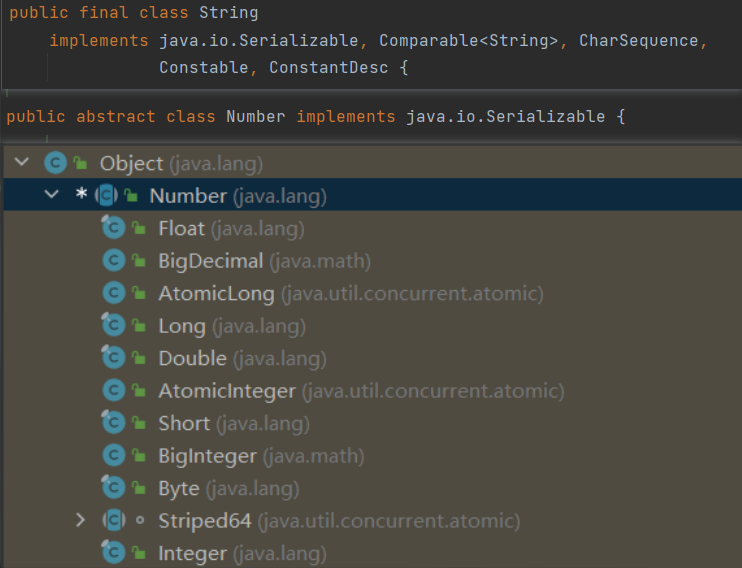
从这张图可以看出:
String 和 Number 是 Serializable 的子类
Number 又是 Float,Double,Integer 等类的父类
能作为主键的数据类型都已经是 Serializable 的子类
MP 使用 Serializable 作为参数类型,就好比我们可以用 Object 接收任何数据类型一样。
在测试类中进行删除操作:
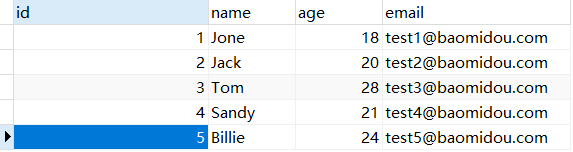
1 2 3 4 5 @Test void testDelete () { int i = userMapper.deleteById(1775096675078713345L ); System.out.println(i); }
控制台结果:
说明数据删除入成功,这时候到数据库中查看,数据库表中 ID 为 1775096675078713345 的数据就会被删除:
修改 Update
在测试类中进行修改操作:
1 2 3 4 5 6 7 8 9 @Test void testUpdate () { User user = new User (); user.setId(1L ); user.setName("Jone001" ); user.setAge(20 ); int i = userMapper.updateById(user); System.out.println(i); }
控制台结果:
说明数据修改成功,这时候到数据库中查看,发现修改成功:
查询 Select
根据 ID 查询
1 T selectById (Serializable id)
Serializable:参数类型,主键 ID 的值
T:根据 ID 查询只会返回一条数据
在测试类中进行查询操作:
1 2 3 4 5 @Test void testSelectById () { User user = userMapper.selectById(1L ); System.out.println(user); }
1 User(id=1, name=Jone001, age=20, email=test1@baomidou.com)
查询所有
1 List<T> selectList (Wrapper<T> queryWrapper)
Wrapper:用来构建条件查询的条件,目前我们没有可直接传为 Null
List:因为查询的是所有,所以返回的数据是一个集合
在测试类中进行查询操作:
1 2 3 4 5 @Test void testSelectAll () { List<User> userList = userMapper.selectList(null ); userList.forEach(System.out::println); }
控制台输出:
1 2 3 4 5 User(id=1, name=Jone001, age=20, email=test1@baomidou.com) User(id=2, name=Jack, age=20, email=test2@baomidou.com) User(id=3, name=Tom, age=28, email=test3@baomidou.com) User(id=4, name=Sandy, age=21, email=test4@baomidou.com) User(id=5, name=Billie, age=24, email=test5@baomidou.com)
通过以上几个简单的步骤,我们就实现了 User 表的 CRUD 功能,甚至连 XML 文件都不用编写!
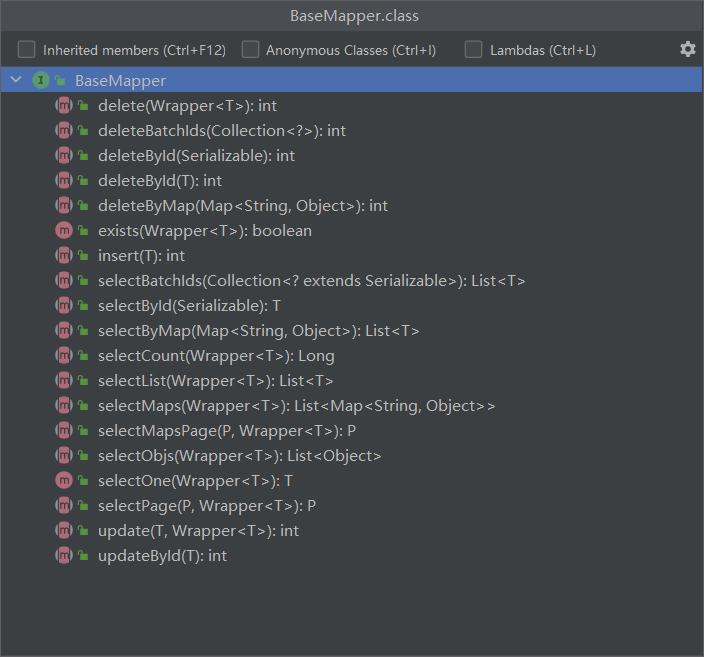
上面我们只是继承了 BaseMapper 就省去所有的单表 CRUD,怎么实现的呢?
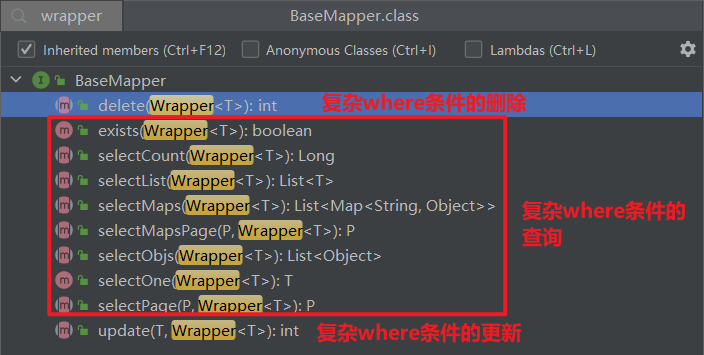
当然是 BaseMapper 接口其中已经实现了单表的 CRUD:
因此我们自定义的 Mapper 只要实现了这个 BaseMapper,就无需自己实现单表 CRUD 了。
3. 配置日志 使用 MP 后,部分 SQL 是不可见的,我们希望知道它是如何执行的,这个时候就需要查看日志!
在配置文件中进行配置:
1 2 3 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
配置日志后,在以后的学习中,我们可以查看日志,观察 MP 的 SQL 执行。
4. 常见注解 在刚刚的入门案例中,我们仅仅引入了依赖,继承了 BaseMapper 就能使用 MP ,非常简单。
但是问题来了: MP 如何知道我们要查询的是哪张表?表中有哪些字段呢?
大家回忆一下,UserMapper 在继承BaseMapper 的时候指定了一个泛型 User
1 2 public interface UserMapper extends BaseMapper <User> {}
泛型中的 User 就是与数据库对应的 PO。
MP 就是根据 PO实体的信息来推断出表的信息,从而生成 SQL 的。默认情况下:
MP 会把 PO 实体的类名驼峰转下划线作为表名
MP 会把 PO 实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型
MP 会把名为 ID 的字段作为主键
但很多情况下,默认的实现与实际场景不符,因此 MP 提供了一些注解便于我们声明表信息。
4.1 @TableName
描述:表名注解,标识实体类对应的表
使用位置:实体类
1 2 3 4 5 6 7 @TableName("sys_user") public class User { private Long id; private String name; private Integer age; private String email; }
TableName 注解除了指定表名以外,还可以指定很多其它属性:
属性
类型
必须指定
默认值
描述
value
String
否
“”
表名
schema
String
否
“”
schema
keepGlobalPrefix
boolean
否
false
是否保持使用全局的 tablePrefix 的值(当全局 tablePrefix 生效时)
resultMap
String
否
“”
xml 中 resultMap 的 id(用于满足特定类型的实体类对象绑定)
autoResultMap
boolean
否
false
是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建与注入)
excludeProperty
String[]
否
{}
需要排除的属性名 @since 3.3.1
4.2 @TableId
1 2 3 4 5 6 7 8 @TableName("sys_user") public class User { @TableId private Long id; private String name; private Integer age; private String email; }
TableId 注解支持两个属性:
属性
类型
必须指定
默认值
描述
value
String
否
“”
表名
type
Enum
否
IdType.NONE
指定主键类型
IdType 支持的类型有:
值
描述
AUTO
数据库 ID 自增
NONE
无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
INPUT
insert 前自行 set 主键值
ASSIGN_ID
分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法)
ASSIGN_UUID
分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法)
ID_WORKER分布式全局唯一 ID 长整型类型(please use ASSIGN_ID)
UUID32 位 UUID 字符串(please use ASSIGN_UUID)
ID_WORKER_STR分布式全局唯一 ID 字符串类型(please use ASSIGN_ID)
这里比较常见的有三种:
ASSIGN_ID:雪花算法生成Long类型的全局唯一ID,这是 MP 默认 的 ID 策略AUTO:利用数据库的ID自增长INPUT:手动生成ID
4.2.1 主键生成策略
雪花算法
雪花算法(Snowflake)是 Twitter 开源的一种分布式ID生成算法,其生成的 ID 具有全局唯一性。这种算法的核心思想是将 64 位的 Long 型 ID 分为四个部分:时间戳、工作机器ID、数据中心ID和序列号。
在上面我们进行数据插入的时候,由于未对主键生成策略进行配置,而 MP 默认 采用的使用 Twitter 的 雪花算法。所以才会看到生成了一长串数字作为 ID。
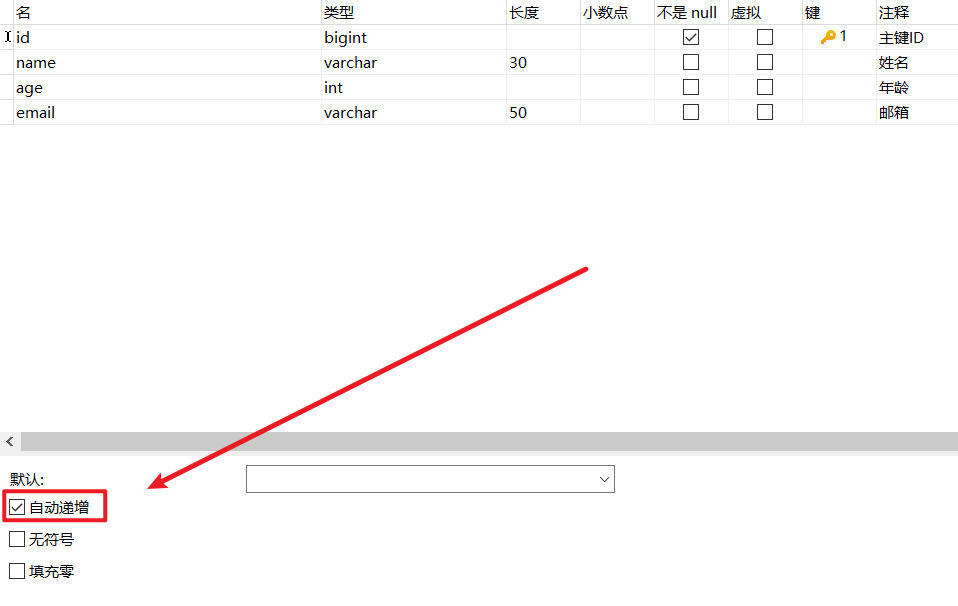
利用数据库的 ID 自增长
1、实体类中表示组件的属性上添加注解:@TableId(type = IdType.AUTO)
2、 数据库字段一定设置为自增 😀
3、再次运行插入测试:
手动生成 ID
1、实体类中表示组件的属性上添加注解:@TableId(type = IdType.INPUT)
2、修改测试类,手动设置 ID
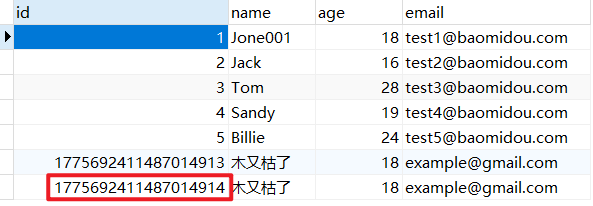
1 2 3 4 5 6 7 8 9 10 @Test void testSave () { User user = new User (); user.setId(6L ); user.setName("木又枯了" ); user.setAge(18 ); user.setEmail("example@gmail.com" ); int i = userMapper.insert(user); System.out.println(i); }
PS:如果我们设置组件生成策略为手动输入 ,但是没有输入,这个时候日志就会显示插入的是 null,但是数据库中也会插入一条 ID 自增的记录
3、再次运行插入测试:
4.3 @TableField
1 2 3 4 5 6 7 8 9 @TableName("sys_user") public class User { @TableId private Long id; @TableField("nickname") private String name; private Integer age; private String email; }
一般情况下我们并不需要给字段添加 @TableField 注解,一些特殊情况除外:
成员变量名与数据库字段名不一致
成员变量是以 isXXX 命名,按照 JavaBean 的规范,MP 识别字段时会把 is 去除,这就导致与数据库不符。
成员变量名与数据库一致,但是与数据库的关键字冲突。使用 @TableField 注解给字段名添加转义字符:``
更多支持的其它属性如下请参考官方文档:@Tablefield注解
5. 常见配置 MP 也支持基于 yml 文件的自定义配置,详见官方文档:使用配置
大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如:
1 2 3 4 5 mybatis-plus: type-aliases-package: com.muyoukule.entity global-config: db-config: id-type: auto
需要注意的是,MP 也支持手写 SQL 的,而 mapper 文件的读取地址可以自己配置:
1 2 mybatis-plus: mapper-locations: "classpath*:/mapper/**/*.xml"
可以看到默认值是 classpath*:/mapper/**/*.xml,也就是说我们只要把 mapper.xml 文件放置这个目录下就一定会被加载。
6. 条件构造器 除了新增以外,修改、删除、查询的SQL语句都需要指定 where 条件。因此 BaseMapper 中提供的相关方法除了以 id 作为 where 条件以外,还支持更加复杂的 where 条件。
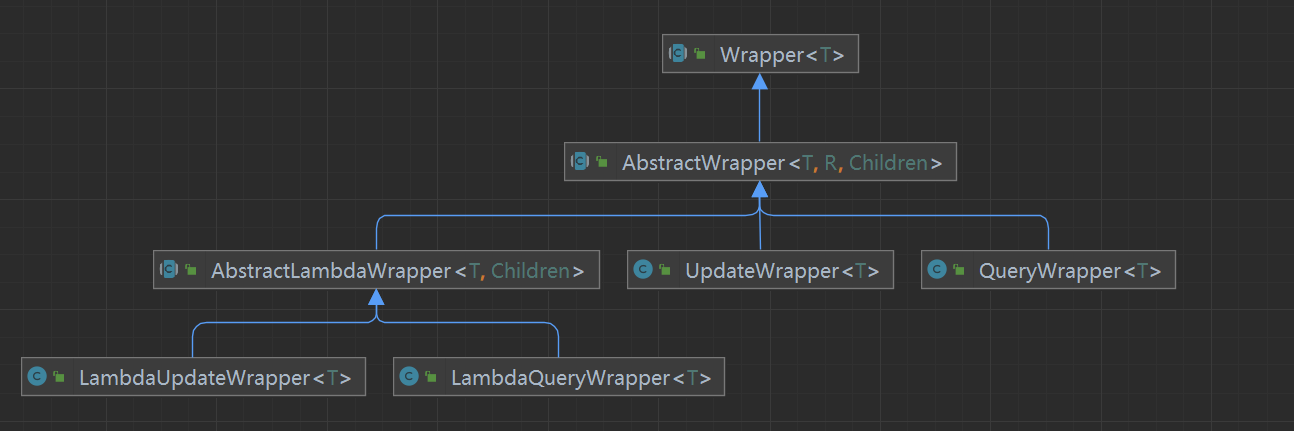
参数中的 Wrapper 就是条件构造的抽象类,其下有很多默认实现,继承关系如图:
Wrapper 的子类 AbstractWrapper 提供了 where 中包含的所有条件构造方法:
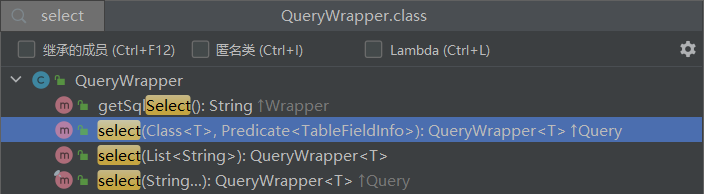
而 QueryWrapper 在 AbstractWrapper 的基础上拓展了一个 select 方法,允许指定查询字段:
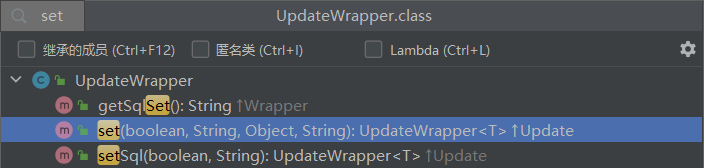
而 UpdateWrapper 在 AbstractWrapper 的基础上拓展了一个 set 方法,允许指定 SQL 中的 SET 部分:
接下来,我们就来看看如何利用 Wrapper 实现复杂查询。
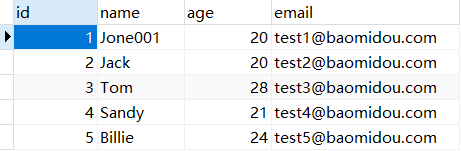
6.1 QueryWrapper 当前数据表数据:
无论是修改、删除、查询,都可以使用 QueryWrapper 来构建查询条件。接下来看一些例子:
多条件构建
查询出名字中带 o ,年龄大于等于 18 的人
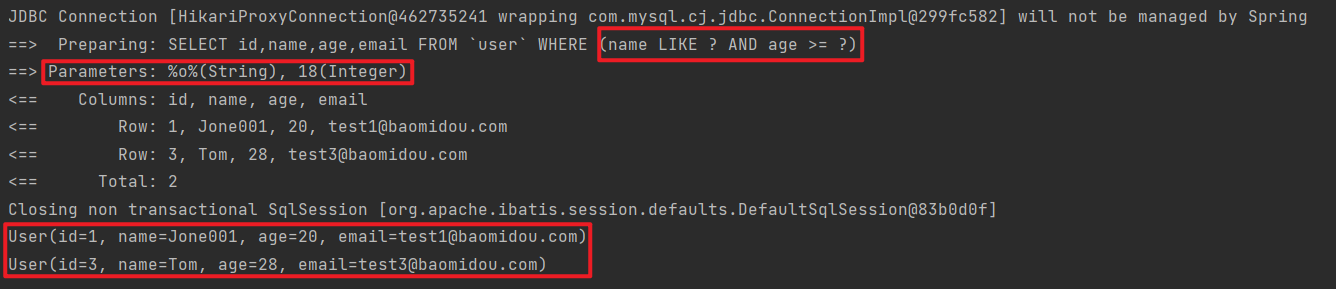
1 2 3 4 5 6 7 8 9 10 11 @Test void testQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>() .select("id" , "name" , "age" , "email" ) .like("name" , "o" ) .ge("age" , 18 ); List<User> userList = userMapper.selectList(wrapper); userList.forEach(System.out::println); }
可以看到 MP 在编写 SQL 语句时会使用 ? 占位符,然后将参数传进去,最终查询到结果:
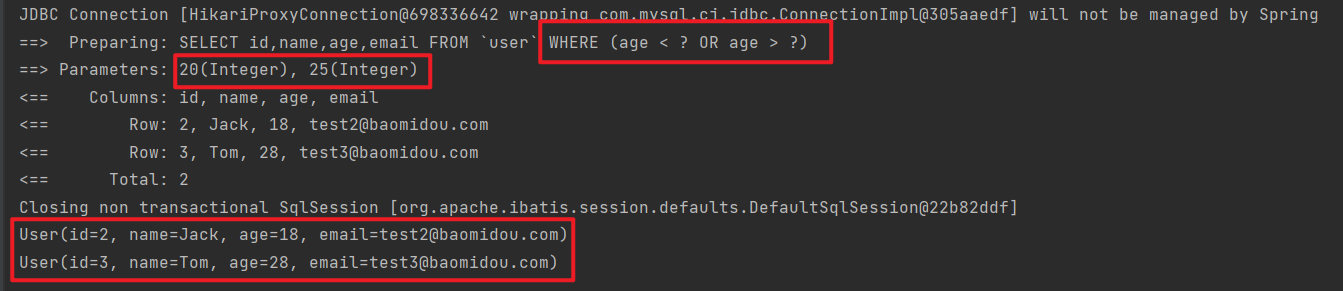
查询出年龄小于 20 或年龄大于 25 的人
1 2 3 4 5 6 7 8 9 @Test void testQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>(); wrapper.lt("age" , 20 ).or().gt("age" , 25 ); List<User> userList = userMapper.selectList(wrapper); userList.forEach(System.out::println); }
PS:or() 就相当于我们sql语句中的 or 关键字,不加默认是 and
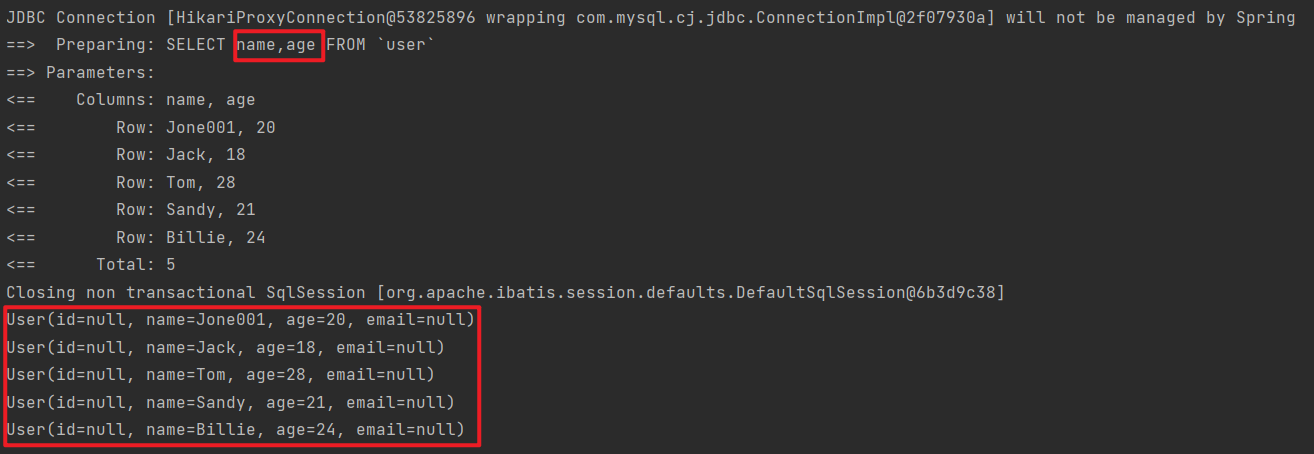
查询投影
查询指定字段
1 2 3 4 5 6 7 @Test void testQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>(); wrapper.select("name" ,"age" ); List<User> userList = userMapper.selectList(wrapper); userList.forEach(System.out::println); }
聚合查询
count、max、min、avg、sum
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test void testQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>(); wrapper.select("avg(age) as avgAge" ); List<Map<String, Object>> userList = userMapper.selectMaps(wrapper); userList.forEach(System.out::println); }
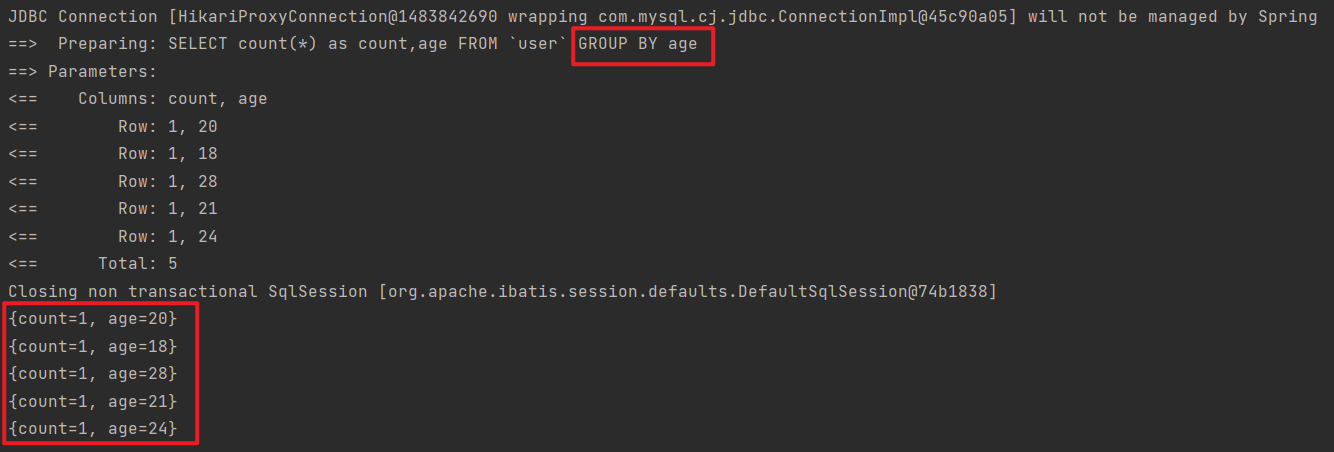
分组查询
分组查询,完成 group by 的查询使用
1 2 3 4 5 6 7 8 9 @Test void testQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>(); wrapper.select("count(*) as count,age" ); wrapper.groupBy("age" ); List<Map<String, Object>> list = userMapper.selectMaps(wrapper); list.forEach(System.out::println); }
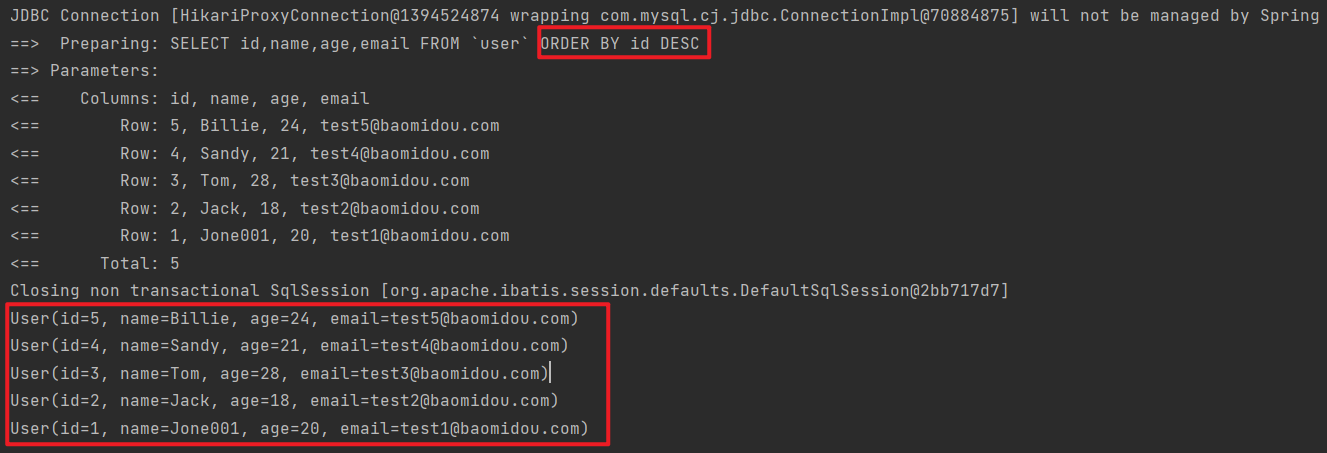
根据 ID 降序排列
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test void testQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <>(); wrapper.orderBy(true , false , "id" ); List<User> userList = userMapper.selectList(wrapper); userList.forEach(System.out::println); }
更新用户名为 Jack 的用户的年龄为 18
1 2 3 4 5 6 7 8 9 @Test void testUpdateByQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>().eq("name" , "Jack" ); User user = new User (); user.setAge(18 ); userMapper.update(user, wrapper); }
除了上面介绍的这几种查询条件构建方法以外还会有很多其他的方法,比如 isNull,isNotNull,in,notIn 等等方法可供选择,具体参考官方文档 的条件构造器来学习使用。
6.2 UpdateWrapper 基于 BaseMapper 中的 update 方法更新时只能直接赋值,对于一些复杂的需求就难以实现。
例如:更新 ID 为 1、2、4 的用户的年龄,减两岁,对应的 SQL 应该是:
1 UPDATE user SET age = age - 2 WHERE id in (1 , 2 , 4 )
SET 的赋值结果是基于字段现有值的,这个时候就要利用 UpdateWrapper 中的 setSql 功能了:
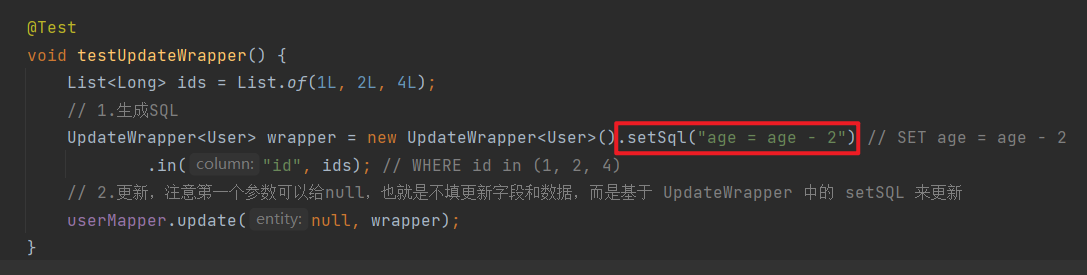
1 2 3 4 5 6 7 8 9 10 @Test void testUpdateWrapper () { List<Long> ids = List.of(1L , 2L , 4L ); UpdateWrapper<User> wrapper = new UpdateWrapper <User>() .setSql("age = age - 2" ) .in("id" , ids); userMapper.update(null , wrapper); }
6.3 LambdaQueryWrapper 无论是 QueryWrapper 还是 UpdateWrapper 在构造条件的时候都需要写死字段名称,会出现字符串魔法值。这在编程规范中显然是不推荐的。 那怎么样才能不写字段名,又能知道字段名呢?
其中一种办法是基于变量的 gettter 方法结合反射技术。因此我们只要将条件对应的字段的 getter 方法传递给 MP,它就能计算出对应的变量名了。而传递方法可以使用JDK8中的 方法引用 和 Lambda 表达式。 因此 MP 又提供了一套基于 Lambda 的Wrapper,包含两个:
LambdaQueryWrapper
LambdaUpdateWrapper
分别对应 QueryWrapper 和 UpdateWrapper
其使用方式如下:
1 2 3 4 5 6 7 8 9 10 11 12 @Test void testLambdaQueryWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <>(); wrapper.lambda() .select(User::getId, User::getName, User::getAge, User::getEmail) .like(User::getName, "o" ) .ge(User::getAge, 18 ); List<User> userList = userMapper.selectList(wrapper); userList.forEach(System.out::println); }
6.4 自定义SQL 在演示 UpdateWrapper 的案例中,我们在代码中编写了更新的 SQL 语句:
这种写法在某些企业也是不允许的,因为 SQL 语句最好都维护在持久层,而不是业务层。就当前案例来说,由于条件是 in 语句,只能将SQL写在Mapper.xml文件,利用foreach来生成动态SQL。 这实在是太麻烦了。假如查询条件更复杂,动态SQL的编写也会更加复杂。
所以,MP提供了自定义SQL功能,可以让我们利用Wrapper生成查询条件,再结合Mapper.xml编写SQL。
6.4.1 基本用法 以当前案例来说,我们可以这样写:
1 2 3 4 5 6 7 8 @Test void testCustomWrapper () { List<Long> ids = List.of(1L , 2L , 4L ); QueryWrapper<User> wrapper = new QueryWrapper <User>().in("id" , ids); userMapper.deductAgeByIds(2 , wrapper); }
然后在UserMapper中自定义SQL:
1 2 3 4 public interface UserMapper extends BaseMapper <User> { @Select("UPDATE user SET age = age - #{age} ${ew.customSqlSegment}") void deductAgeByIds (@Param("age") int age, @Param("ew") QueryWrapper<User> wrapper) ; }
这样就省去了编写复杂查询条件的烦恼了。
6.4.2 多表关联 理论上来讲MyBatisPlus是不支持多表查询的,不过我们可以利用Wrapper中自定义条件结合自定义SQL来实现多表查询的效果。
执行SQL脚本,创建address表,与 user 表相关联:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 CREATE TABLE IF NOT EXISTS `address` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_id` bigint DEFAULT NULL COMMENT '用户ID' , `province` varchar (10 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '省' , `city` varchar (10 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '市' , `town` varchar (10 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '县/区' , `mobile` varchar (255 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '手机' , `street` varchar (255 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '详细地址' , `contact` varchar (255 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '联系人' , `is_default` bit(1 ) DEFAULT b'0' COMMENT '是否是默认 1默认 0否' , `notes` varchar (255 ) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '备注' , PRIMARY KEY (`id`) USING BTREE, KEY `user_id` (`user_id`) USING BTREE ) ENGINE= InnoDB AUTO_INCREMENT= 71 DEFAULT CHARSET= utf8mb3 ROW_FORMAT= COMPACT; INSERT INTO `address` (`id`, `user_id`, `province`, `city`, `town`, `mobile`, `street`, `contact`, `is_default`, `notes`) VALUES (59 , 2 , '北京' , '北京' , '朝阳区' , '13900112222' , '金燕龙办公楼' , 'Rose' , b'1' , NULL ), (60 , 1 , '北京' , '北京' , '朝阳区' , '13700221122' , '修正大厦' , 'Jack' , b'0' , NULL ), (61 , 1 , '上海' , '上海' , '浦东新区' , '13301212233' , '航头镇航头路' , 'Jack' , b'1' , NULL ), (63 , 2 , '广东' , '佛山' , '永春' , '13301212233' , '永春武馆' , 'Rose' , b'0' , NULL ), (64 , 3 , '浙江' , '杭州' , '拱墅区' , '13567809102' , '浙江大学' , 'Hope' , b'1' , NULL ), (65 , 3 , '浙江' , '杭州' , '拱墅区' , '13967589201' , '左岸花园' , 'Hope' , b'0' , NULL ), (66 , 4 , '湖北' , '武汉' , '汉口' , '13967519202' , '天天花园' , 'Thomas' , b'1' , NULL ), (67 , 3 , '浙江' , '杭州' , '拱墅区' , '13967589201' , '左岸花园' , 'Hopey' , b'0' , NULL ), (68 , 4 , '湖北' , '武汉' , '汉口' , '13967519202' , '天天花园' , 'Thomas' , b'1' , NULL ), (69 , 3 , '浙江' , '杭州' , '拱墅区' , '13967589201' , '左岸花园' , 'Hopey' , b'0' , NULL ), (70 , 4 , '湖北' , '武汉' , '汉口' , '13967519202' , '天天花园' , 'Thomas' , b'1' , NULL );
我们要查询出所有收货地址在北京的并且用户 ID 在 1、2、4 之中的用户 要是自己基于 Mybatis 实现 SQL,大概是这样的:
1 2 3 4 5 6 7 8 9 10 <select id ="queryUserByIdAndAddr" resultType ="com.muyoukule.entity.User" > SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id WHERE u.id <foreach collection ="ids" separator ="," item ="id" open ="IN (" close =")" > #{id} </foreach > AND a.city = #{city} </select >
可以看出其中最复杂的就是 WHERE 条件的编写,如果业务复杂一些,这里的 SQL 会更变态。
但是基于自定义 SQL 结合 Wrapper 的玩法,我们就可以利用 Wrapper 来构建查询条件,然后手写 SELECT 及 FROM 部分,实现多表查询。
查询条件这样来构建:
1 2 3 4 5 6 7 8 9 10 11 @Test void testCustomJoinWrapper () { QueryWrapper<User> wrapper = new QueryWrapper <User>() .in("u.id" , List.of(1L , 2L , 4L )) .eq("a.city" , "北京" ); List<User> userList = userMapper.queryUserByWrapper(wrapper); userList.forEach(System.out::println); }
然后在UserMapper中自定义方法:
1 2 @Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}") List<User> queryUserByWrapper (@Param("ew") QueryWrapper<User> wrapper) ;
当然,也可以在UserMapper.xml中写SQL:
1 2 3 <select id ="queryUserByIdAndAddr" resultType ="com.itheima.mp.domain.po.User" > SELECT * FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment} </select >
7. 代码生成 在使用MP 以后,基础的Mapper、Service、PO代码相对固定,重复编写也比较麻烦。因此MP 官方提供了代码生成器。
适用版本:mybatis-plus-generator 3.5.1 及其以上版本,对历史版本不兼容!
3.5.1 以下的请参考:代码生成器(旧)
首先需要添加依赖,MP 从 3.0.3 之后移除了代码生成器与模板引擎的默认依赖,需要手动添加相关依赖:
1 2 3 4 5 6 7 8 9 10 11 12 <dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-generator</artifactId > <version > 3.5.3.1</version > </dependency > <dependency > <groupId > org.apache.velocity</groupId > <artifactId > velocity-engine-core</artifactId > <version > 2.3</version > </dependency >
创建代码生成类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 package com.muyoukule;import com.baomidou.mybatisplus.annotation.FieldFill;import com.baomidou.mybatisplus.annotation.IdType;import com.baomidou.mybatisplus.generator.FastAutoGenerator;import com.baomidou.mybatisplus.generator.config.OutputFile;import com.baomidou.mybatisplus.generator.config.rules.DateType;import com.baomidou.mybatisplus.generator.config.rules.DbColumnType;import com.baomidou.mybatisplus.generator.fill.Column;import com.baomidou.mybatisplus.generator.fill.Property;import java.sql.Types;import java.util.Collections;public class CodeGenerator { public static void main (String[] args) { FastAutoGenerator.create("jdbc:mysql://127.0.0.1:3306/mybatis_plus" , "root" , "root" ) .globalConfig(builder -> { builder.disableOpenDir() .author("木又枯了" ) .outputDir(System.getProperty("user.dir" ) + "/src/main/java" ) .dateType(DateType.TIME_PACK) .commentDate("yyyy-MM-dd" ) .build(); }) .dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> { int typeCode = metaInfo.getJdbcType().TYPE_CODE; if (typeCode == Types.SMALLINT) { return DbColumnType.INTEGER; } return typeRegistry.getColumnType(metaInfo); }) ) .packageConfig(builder -> { builder.parent("com.muyoukule" ) .entity("entity" ) .service("service" ) .serviceImpl("service.impl" ) .mapper("mapper" ) .xml("AddressMapper.xml" ) .controller("controller" ) .pathInfo(Collections.singletonMap(OutputFile.xml, System.getProperty("user.dir" ) + "/src/main/resources/mapper" )) .build(); }) .strategyConfig(builder -> { builder .entityBuilder() .enableLombok() .versionColumnName("version" ) .logicDeleteColumnName("deleted" ) .addTableFills(new Column ("create_time" , FieldFill.INSERT)) .addTableFills(new Property ("updateTime" , FieldFill.INSERT_UPDATE)) .idType(IdType.AUTO) .formatFileName("%s" ) .controllerBuilder() .enableRestStyle() .formatFileName("%sController" ) .build(); }) .execute(); } }
以上代码按要求修改即可使用。对于代码生成器中的更多代码内容,我们可以直接从官方文档 中获取代码进行修改。
8. 逻辑删除 对于一些比较重要的数据,我们往往会采用逻辑删除的方案,即:
在表中添加一个字段标记数据是否被删除
当删除数据时把标记置为true
查询时过滤掉标记为true的数据
一旦采用了逻辑删除,所有的查询和删除逻辑都要跟着变化,非常麻烦。
为了解决这个问题,MP 就添加了对逻辑删除的支持。
PS:只有 MP 生成的SQL语句才支持自动的逻辑删除,自定义 SQL 需要自己手动处理逻辑删除。
1、我们给 user 表添加一个逻辑删除字段,设置默认值为 0 :
1 alter table user add deleted bit default b'0' null comment '逻辑删除' ;
2、给 user 实体添加 deleted 字段:
1 2 private Boolean deleted;
3、在application.yml中配置逻辑删除字段:
1 2 3 4 5 6 mybatis-plus: global-config: db-config: logic-delete-field: deleted logic-delete-value: 1 logic-not-delete-value: 0
4、测试
首先,我们执行一个删除操作:
1 2 3 4 @Test void testDelete () { int i = userMapper.deleteById(1L ); }
方法与普通删除一模一样,但是底层的SQL逻辑变了:
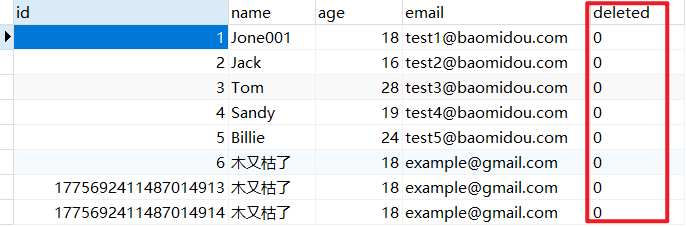
查看数据库,发现 ID 为1 的记录还在数据库,只是 deleted 字段变为 1 :
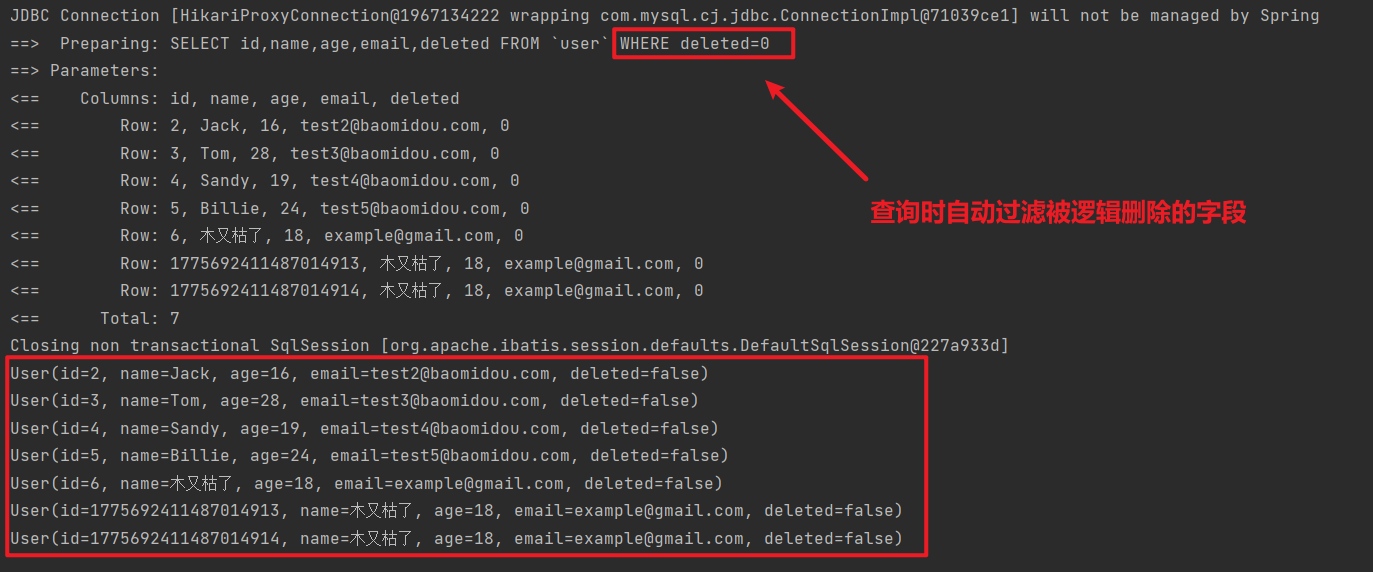
查询一下试试:
1 2 3 4 5 @Test void testSelectAll () { List<User> userList = userMapper.selectList(null ); userList.forEach(System.out::println); }
会发现 ID为 1 的记录确实没有查询出来,而且 SQL 中也对逻辑删除字段做了判断:
综上, 开启了逻辑删除功能以后,我们就可以像普通删除一样做CRUD,基本不用考虑代码逻辑问题。还是非常方便的。
注意 : 逻辑删除本身也有自己的问题,比如:
会导致数据库表垃圾数据越来越多,从而影响查询效率
SQL 中全都需要对逻辑删除字段做判断,影响查询效率
因此,不太推荐采用逻辑删除功能,如果数据不能删除,可以采用把数据迁移到其它表的办法。
9. 通用枚举 9.1 声明通用枚举属性 1、我们给 user 表添加一个 status 字段:
1 alter table user add `status` INT (10 ) NULL DEFAULT '1' COMMENT '使用状态(1正常 2冻结)' ;
2、定义一个用户状态的枚举:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.muyoukule.enums;import lombok.Getter;@Getter public enum UserStatus { NORMAL(1 , "正常" ), FREEZE(2 , "冻结" ); private final int value; private final String desc; UserStatus(int value, String desc) { this .value = value; this .desc = desc; } }
3、给 user 实体添加 status 字段:
1 2 private UserStatus status;
要让 MP 处理枚举与数据库类型自动转换,我们必须告诉 MP,枚举中的哪个字段的值作为数据库值。
MP 提供了 @EnumValue 注解来标记枚举属性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Getter public enum UserStatus { NORMAL(1 , "正常" ), FREEZE(2 , "冻结" ); @EnumValue private final int value; private final String desc; UserStatus(int value, String desc) { this .value = value; this .desc = desc; } }
9.2 配置扫描通用枚举PS:从 3.5.2 开始无需配置!
方式一:仅配置指定包内的枚举类使用 MybatisEnumTypeHandler
1 2 3 4 mybatis-plus: typeEnumsPackage: com.muyoukule.enums
当添加这个配置后,mybatis-plus 提供的 MybatisSqlSessionFactoryBean 会自动扫描包内合法的枚举类(使用了 @EnumValue 注解,或者实现了 IEnum 接口),分别为这些类注册使用 MybatisEnumTypeHandler。
换句话说,只有指定包下的枚举类会使用新的 TypeHandler。其他包下,或者包内没有做相关改造的枚举类,仍然会使用 Mybatis 的 DefaultEnumTypeHandler。
方式二:直接指定 DefaultEnumTypeHandler
此方式用来 全局 修改 Mybatis 使用的 EnumTypeHandler。
在application.yaml文件中添加配置:
1 2 3 mybatis-plus: configuration: default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
自定义配置类 MybatisPlusAutoConfiguration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Configuration public class MybatisPlusAutoConfiguration { @Bean public MybatisPlusPropertiesCustomizer mybatisPlusPropertiesCustomizer () { return properties -> { GlobalConfig globalConfig = properties.getGlobalConfig(); globalConfig.setBanner(false ); MybatisConfiguration configuration = new MybatisConfiguration (); configuration.setDefaultEnumTypeHandler(MybatisEnumTypeHandler.class); properties.setConfiguration(configuration); }; } }
查询一条数据查看:
1 2 3 4 5 6 7 8 { "id" : 2 , "name" : "Jack" , "age" : 16 , "email" : "test2@baomidou.com" , "deleted" : false , "status" : "NORMAL" }
如何序列化枚举值为前端返回值?
在UserStatus枚举中通过 @JsonValue 注解标记 JSON 序列化时展示的字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Getter public enum UserStatus { NORMAL(1 , "正常" ), FREEZE(2 , "冻结" ); @EnumValue private final int value; @JsonValue private final String desc; UserStatus(int value, String desc) { this .value = value; this .desc = desc; } }
再次查看:
1 2 3 4 5 6 7 8 { "id" : 2 , "name" : "Jack" , "age" : 16 , "email" : "test2@baomidou.com" , "deleted" : false , "status" : "正常" }
可以看到在 desc 上加了 @JsonValue 注解注解后 status 由 NORMAL 变为了 正常 。
10. JSON类型处理器 1、我们给 user 表添加一个 info 字段,是 JSON 类型:
1 alter table user add `info` JSON NOT NULL COMMENT '详细信息' ;
2、向 info 字段擦插入数据格式像这样:
1 { "intro" : "佛系青年" , "gender" : "male" }
3、给 user 实体添加 info 字段:
一般 User 实体类中都是 String 类型的 info,这样一来,我们要读取 info 中的属性时就非常不方便。
1 2 3 4 5 6 7 8 9 { "id" : 2 , "name" : "Jack" , "age" : 16 , "email" : "test2@baomidou.com" , "deleted" : false , "status" : "正常" , "info" : "{\"intro\": \"佛系青年\", \"gender\": \"male\"}" }
如果要方便获取,info 的类型最好是一个 Map 或者实体类。而一旦我们把 info 改为 对象 类型,就需要在写入数据库时手动转为 String,再读取数据库时,手动转换为 对象,这会非常麻烦。
因此 MP 提供了很多特殊类型字段的类型处理器,解决特殊字段类型与数据库类型转换的问题。例如处理 JSON 就可以使用 JacksonTypeHandler 处理器。
怎么使用 JacksonTypeHandler 处理器呢?
1、我们定义一个单独实体类来与 info 字段的属性匹配:
1 2 3 4 5 @Data public class UserInfo { private String intro; private String gender; }
2、接下来,将 User 类的 info 字段设置为 UserInfo 类型,并声明类型处理器:
PS:必须开启映射注解 @TableName(autoResultMap = true) !!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Data @NoArgsConstructor @AllArgsConstructor @TableName(value = "`user`", autoResultMap = true) public class User { @TableId(type = IdType.INPUT) private Long id; @TableField(typeHandler = JacksonTypeHandler.class) private UserInfo info; }
3、测试可以发现,所有数据都正确封装到 UserInfo 当中了:
1 2 3 4 5 6 7 8 9 10 11 12 { "id" : 2 , "name" : "Jack" , "age" : 16 , "email" : "test2@baomidou.com" , "deleted" : false , "status" : "正常" , "info" : { "intro" : "伏地魔" , "gender" : "male" } }
11. 自动填充功能 创建时间、更新时间,对于这两个字段的操作我们希望是自动完成而不是需要手动编写。
1、我们给 user 表添加 create_time 字段和 update_time 字段并将这两个字段类型设置为 timestamp:
1 2 alter table user add `create_time` timestamp COMMENT '创建时间' ;alter table user add `update_time` timestamp COMMENT '更新时间' ;
2、同步实体类,实体类的属性上增加注解:
1 2 3 4 5 @TableField(fill = FieldFill.INSERT) private LocalDateTime createTime;@TableField(fill = FieldFill.INSERT_UPDATE) private LocalDateTime updateTime;
3、编写处理器来处理这些注解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Slf4j @Component public class MyMetaObjectHandler implements MetaObjectHandler { @Override public void insertFill (MetaObject metaObject) { log.info("start insert fill ...." ); this .strictInsertFill(metaObject, "createTime" , LocalDateTime.class, LocalDateTime.now()); this .strictInsertFill(metaObject, "updateTime" , LocalDateTime.class, LocalDateTime.now()); } @Override public void updateFill (MetaObject metaObject) { log.info("start update fill ...." ); this .strictUpdateFill(metaObject, "updateTime" , LocalDateTime.class, LocalDateTime.now()); } }
3、测试插入:
1 2 3 4 5 6 7 8 9 @Test void testSave () { User user = new User (); user.setName("木又枯了" ); user.setAge(18 ); user.setEmail("example@gmail.com" ); userMapper.insert(user); }
4、查看数据库:
12. 乐观锁插件 与乐观锁相对的有:悲观锁
悲观锁在数据修改前加锁,避免其他事务修改,确保数据安全但可能降低并发性能。
乐观锁则假设冲突少,只在数据提交时验证冲突,提高并发性能但可能需处理更多冲突。
官方解释:乐观锁插件
目的:当要更新一条记录的时候,希望这条记录没有被别人更新。
乐观锁实现方式:
取出记录时,获取当前 version
更新时,带上这个 version
执行更新时, set version = newVersion where version = oldVersion
如果 version 不对,就更新失败
1 2 3 4 update user set name = "木又枯了", version = version + 1 where id = 6 and version = 1
乐观锁插件实现步骤
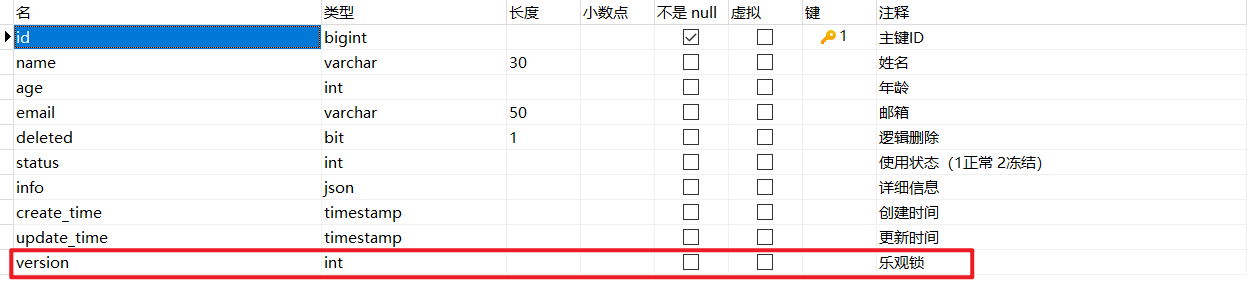
1、我们给 user 表添加一个 version 字段,设置默认值为 1 :
1 alter table user add version int default b'1' null comment '乐观锁' ;
添加结果如下:
2、给实体类增加相应的字段,并添加注解 @Version
1 2 @Version private Integer version;
3、注册组件
1 2 3 4 5 6 7 8 9 10 11 @Configuration @MapperScan("com.muyoukule.mapper") public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor () { MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor (); mybatisPlusInterceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor ()); return mybatisPlusInterceptor; } }
4、编写测试方法进行测试:
PS:要想实现乐观锁,首先第一步应该是拿到表中的 version,然后拿 version 当条件再将 version 加 1 更新回到数据库表中,所以我们需要先对其进行查询
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void testOptimisticLocker () { User user = userMapper.selectById(2L ); user.setName("muyoukule" ); user.setAge(18 ); user.setEmail("example@gmail.com" ); userMapper.updateById(user); }
5、查看数据库:
我们再来测试一下修改失败的情况,模拟一种加锁的情况,看看能不能实现多个人修改同一个数据的时候,只能有一个人修改成功。
1 2 3 4 5 6 7 8 9 10 11 @Test public void testOptimisticLocker2 () { User user = userMapper.selectById(2L ); User user2 = userMapper.selectById(2L ); user2.setName("muyoukule222" ); userMapper.updateById(user2); user.setName("muyoukule111" ); userMapper.updateById(user); }
如果没有乐观锁,最后一次的修改会覆盖前一次的修改,但是有了乐观锁就不会出现这种情况了。查看数据库修改结果:
查看数据库后发现 muyoukule111 并未覆盖 muyoukule222 。
12. 分页插件 在未引入分页插件的情况下,MP 是不支持分页功能的,IService 和 BaseMapper 中的分页方法都无法正常起效。 所以,我们必须配置分页插件。
1、配置分页插件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Configuration @MapperScan("com.muyoukule.mapper") public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor () { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor (); interceptor.addInnerInterceptor(new PaginationInnerInterceptor (DbType.MYSQL)); return interceptor; } }
2、编写一个分页查询的测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test void testPageQuery () { Page<User> page = new Page <>(2 , 2 ); userMapper.selectPage(page, null ); System.out.println("total = " + page.getTotal()); System.out.println("pages = " + page.getPages()); List<User> records = page.getRecords(); records.forEach(System.out::println); }
3、控制台输出:
1 2 3 4 total = 8 pages = 4 User(id=4, name=Sandy, age=19, email=test4@baomidou.com, deleted=false, status=NORMAL, info=null, createTime=null, updateTime=null, version=1) User(id=5, name=Billie, age=24, email=test5@baomidou.com, deleted=false, status=NORMAL, info=null, createTime=null, updateTime=null, version=1)
PS:由于前面我们使用了逻辑删除,deleted 值为 1 的字段不会被查询到,所以数据表一共是 8 条记录。
4、对比数据库数据: